Python实现有趣的亲戚关系计算器
目录
- 介绍
- 需求
- 数据定义
- 算法实现
- 分析
- 算法主要函数一:transformTitleToKey
- 算法主要函数二:FilteHelper
- 算法主要函数三:dataValueByKeys
- 输出与效果
- 一些细节与已知问题
每年的春节,都会有一些自己几乎没印象但父母就是很熟的亲戚,关系凌乱到你自己都说不清。
今年趁着春节在家没事情干,正好之前知道有中国亲戚关系计算器,想着自己实现一下,特此记录。
介绍
由于本人能力有限,只完成了基本功能....
需求
计算亲戚关系链得出我应该怎么称呼的结果
数据定义
1.定义关系字符和修饰符
【关系】f:父,m:母,h:夫,w:妻,s:子,d:女,xb:兄弟,ob:兄,lb:弟,xs:姐妹,os:姐,ls:妹
【修饰符】 &o:年长,&l:年幼,#:隔断,[a|b]:并列
2.关系对应数据集合、关系过滤数据集合(data.json 和 filter.json)
原来参考的作者的关系过滤数据集合json有点问题,改了一下
filter 数据集的用途:比如 m,h 是我的妈妈 的丈夫就是爸爸,也就是 f。 filter 的作用是去重和简化,需要把 exp 用 str 进行替换
算法实现
需要解决的情况基本有以下三种:
- 我的爸爸 = 爸爸,
- 我的哥哥的弟弟 = 自己/弟弟/哥哥,
- 我的哥哥的老公 = ?
分析
三种结果:1.单结果 2.多结果 3.错误提示 ,那么我们的算法要兼容以上三种情况,下面我们来一步步实现。
算法主要函数一:transformTitleToKey
该函数主要负责将文字转换成关系符号
# 将文字转换成关系符号
def transformTitleToKey(text):
result = text.replace("的", ",").replace("我", "").replace("爸爸", "f").replace("父亲", "f").replace("妈妈","m").replace("母亲", "m").replace("爷爷","f,f").replace("奶奶", "f,m").replace("外公", "m,f").replace("姥爷", "m,f").replace("外婆", "m,m").replace("姥姥", "m,m").replace("老公","h").replace("丈夫", "h").replace("老婆", "w").replace("妻子", "h").replace("儿子", "s").replace("女儿", "d").replace("兄弟", "xd").replace("哥哥", "ob").replace("弟弟","lb").replace("姐妹","xs").replace("姐姐", "os").replace("妹妹", "ls").strip(",")
return result
这里简化了原参考作者的写法,更 简单(不是) 符合计算器设定
算法主要函数二:FilteHelper
该函数主要负责去重和简化
# 去重和简化
def FilteHelper(text):
result = text
filterName = '/filter.json' # filter.json文件路径
if not os.path.isfile(filterName):
return "filterName文件不存在"
with open(filterName, "r") as f:
obj = list(ijson.items(f, 'filter'))
for i in range(len(obj[0])):
users = obj[0][i]['exp']
if users == result:
return obj[0][i]['str']
elif re.match(obj[0][i]['exp'], result): # 符合正则
result1 = re.findall(obj[0][i]['exp'], result) # 返回string中所有与pattern匹配的全部字符串,返回形式为数组
print(result1)
a = 0
result2 = ""
if len(result1)>1:
try:
for i in len(result1):
result = result.replace("$" + str(a + 1), result1[a])
a = a + 1
if result.find("#") != -1:
result_l = result
resultList = list(set(result_l.split("#"))) # # 是隔断符,所以分割文本
for key in resultList:
result = FilteHelper(key.strip(","))
if (result.find("#") == -1): # 当关系符号不含#时加入最终结果中
result2 = result2 + result
return result2
else:
return text
except Exception as e:
return text
else:
return str(result1).replace("[\'", "").replace("\']", "")
elif re.match(obj[0][i]['exp'], strInsert(result, 0, ',')): # 符合正则
result1 = re.findall(obj[0][i]['exp'], strInsert(result, 0, ',')) # 返回string中所有与pattern匹配的全部字符串,返回形式为数组
a = 0
result2 = ""
if len(result1)>1:
try:
for i in len(result1):
result = result.replace("$" + str(a + 1), result1[a])
a = a + 1
if result.find("#") != -1:
result_l = result
resultList = list(set(result_l.split("#"))) # # 是隔断符,所以分割文本
for key in resultList:
result = FilteHelper(key.strip(","))
if (result.find("#") == -1): # 当关系符号不含#时加入最终结果中
result2 = result2 + result
return result2
else:
return text
except Exception as e:
return text
else:
return str(result1).replace("[\'", "").replace("\']", "")
return text
这里原参考作者解释的有点乱,我就以我个人见解参考着写了出来...能跑....有错欢迎指出
个人测试单结果,多结果都能实现,建议多结果实现参考输出和代码详细理解
算法主要函数三:dataValueByKeys
该函数主要负责从数据源中查找对应 key 的结果
# 从数据源中查找对应 key 的结果
def dataValueByKeys(data_text):
if(isChinese(data_text)): # 判断是否含有中文,含有的是特殊回复
return data_text
dataName = '/data.json' # data.json文件路径
if not os.path.isfile(dataName):
return "data文件不存在"
fo = open(dataName, 'r', encoding='utf-8')
ID_Data = demjson.decode(fo.read())
fo.close()
try:
if ID_Data[data_text]:
cityID = ID_Data[data_text]
text = ""
for key in cityID:
text = text + key + '\\'
return text.strip("\\")
else:
return "未找到"
except Exception as e:
result = ""
resultList = FilteHelper(strInsert(data_text, 0, ',')).split(",")
for key in resultList:
result = result + dataValueByKeys(key)
return result
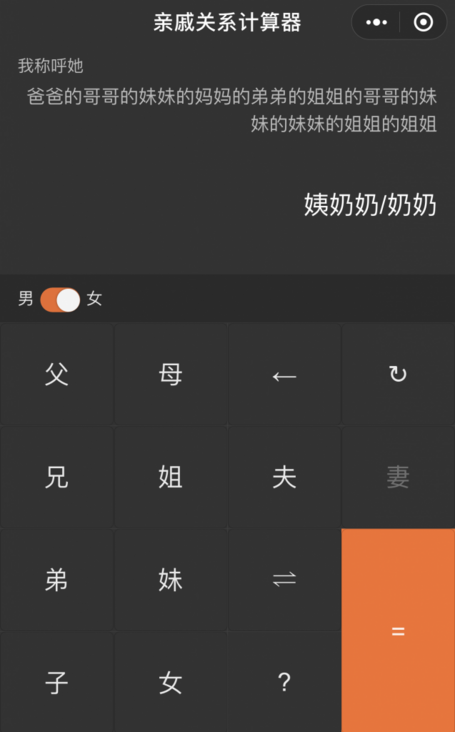
输出与效果




基本达到效果
一些细节与已知问题
首先,是性别:如果‘我’是女性,那么‘我的父亲的儿子’可以为[‘哥哥’,‘弟弟’],而不可以包含‘我’。(上述代码没实现)
另外,关于夫妻关系:在正常情况下,男性称谓只可以有‘妻子’,女性称谓只可以有‘丈夫’。(上述代码已实现)
第三,多种可能:‘我的父亲的儿子’ 可以是[‘我’,‘哥哥’,‘弟弟’],再若是再往后计算,如‘我的父亲的儿子的儿子’ ,需要同时考虑‘我的儿子’,‘哥哥的儿子’,‘弟弟的儿子’这三种可能。(上述代码已实现)
已知问题:某些涉及自己的多重可能还存在莫名BUG
以上就是Python实现有趣的亲戚关系计算器的详细内容,更多关于Python亲戚关系计算器的资料请关注我们其它相关文章!
相关推荐
-
python实现简易版计算器
学了一周的Python,这篇文章算是为这段时间自学做的小总结. 一.Python简介 Python是一门十分优美的脚本语言,如果学过java.c++那入门Python是非常简单的.Python具有丰富和强大的类库.它常被昵称为胶水语言,它能够很轻松的把用其他语言制作的各种模块(尤其是C/C++)轻松地联结在一起.常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写. 二.Python版计算器的实现 工具准备: 1.
-
python 实现一个图形界面的汇率计算器
调用的api接口: https://api.exchangerate-api.com/v4/latest/USD 完整代码 import requests from tkinter import * import tkinter as tk from tkinter import ttk class RealTimeCurrencyConverter(): def __init__(self,url): self.data = requests.get(url).json() self.curr
-

Python实现的简单计算器功能详解
本文实例讲述了Python实现的简单计算器功能.分享给大家供大家参考,具体如下: 使用python编写一款简易的计算器 计算器效果图 首先搭建计算器的面板: 计算器面板结构 建造一个继承于wx.Frame的frame,在init属性函数中搭建面板 class CalcFrame(wx.Frame):#建造一个继承于wx.Frame的frame def __init__(self,title): wx.Frame.__init__ (self,None,-1,title, pos=(100,300
-
Python PyQt5实现的简易计算器功能示例
本文实例讲述了Python PyQt5实现的简易计算器功能.分享给大家供大家参考,具体如下: 这里剩下计算函数(self.calculator)未实现,有兴趣的朋友可以实现它 [知识点] 1.利用循环添加按钮部件,及给每个按钮设置信号/槽 2.给按钮设置固定大小:button.setFixedSize(QtCore.QSize(60,30)) 3.取事件的的发送者(此例为各个按钮)的文本: self.sender().text() [效果图] [源代码] import sys from PyQt
-
基于python的Tkinter实现一个简易计算器
本文实例介绍了基于python的Tkinter实现简易计算器的详细代码,分享给大家供大家参考,具体内容如下 第一种:使用python 的 Tkinter实现一个简易计算器 #coding:utf-8 from Tkinter import * import time root = Tk() def cacl(input_str): if "x" in input_str: ret = input_str.split("x") return int(ret[0]) *
-
Python编程使用tkinter模块实现计算器软件完整代码示例
Python 提供了多个图形开发界面的库.Tkinter就是其中之一. Tkinter 模块(Tk 接口)是 Python 的标准 Tk GUI 工具包的接口 .Tk 和 Tkinter 可以在大多数的 Unix 平台下使用,同样可以应用在 Windows 和 Macintosh 系统里.Tk8.0 的后续版本可以实现本地窗口风格,并良好地运行在绝大多数平台中. 该计算器使用Python tkinter模块开发 效果如下图 import tkinter #导入tkinter模块 root = t
-
利用Python绘制有趣的万圣节南瓜怪效果
关于万圣节 万圣节又叫诸圣节,在每年的11月1日,是西方的传统节日;而万圣节前夜的10月31日是这个节日最热闹的时刻.在中文里,常常把万圣节前夜(Halloween)讹译为万圣节(All Saints' Day). 为庆祝万圣节的来临,小孩会装扮成各种可爱的鬼怪向逐家逐户地敲门,要求获得糖果,否则就会捣蛋.而同时传说这一晚,各种鬼怪也会装扮成小孩混入群众之中一起庆祝万圣节的来临,而人类为了让鬼怪更融洽才装扮成各种鬼怪. 不知从何时开始,西方的节日一个个的走进了天朝,情人节.圣诞节.感恩节.万圣节
-
python tkinter 做个简单的计算器的方法
背景 最近本菜鸡在学习 python GUI,从 tkinter 入门,想先做个小软件练习一下 思来想去,决定做一个 计算器 设计思路 首先,导入我们需要的包 - tkinter,并通过 实例化一个 Tk 对象 创建窗口 因为我有点菜,目前还把控不好各组件的位置,所以窗口使用自动默认的大小 import tkinter as tk import tkinter.messagebox win = tkinter.Tk() win.title("计算器") win.mainloop() 大
-
Python编程中Python与GIL互斥锁关系作用分析
我们知道,在 CPython 中,有一个全局解释器锁,英文叫 global interpreter lock,简称 GIL,是一个互斥锁,用来保护 Python 世界里的对象,防止同一时刻多个线程执行 Python 的字节码,从而确保线程安全,这导致了 Python 的线程无法利用多核 CPU 的优势,因此有人说 Python 的多线程是伪多线程,性能不高,那么 Python 将来有可能去除 GIL 吗? 要回答这个问题,先从 GIL 的起源进行分析. GIL 的起源 Python 第一次发布是
-
Python超有趣实例通过冒泡排序来实现LOL厄斐琉斯控枪
目录 1.冒泡排序 2.需求更改和算法介绍 3.实际应用 1.厄斐琉斯简介 2.代码实现及说明 4.总结 今天来给大家讲解一下"冒泡排序" 1.冒泡排序 当给定一个数组arr,使用冒泡排序将其按从小到大的顺序排列. 具体原理网上已经烂大街了,这里我就不去copy了,不懂的小伙伴可以借鉴Python 冒泡排序 定义:冒泡排序(Bubble Sort)也是一种简单直观的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.走访数列的工作是重复地进行直到
-
Python中有趣在__call__函数
Python中有一个有趣的语法,只要定义类型的时候,实现__call__函数,这个类型就成为可调用的. 换句话说,我们可以把这个类型的对象当作函数来使用,相当于 重载了括号运算符. class g_dpm(object): def __init__(self, g): self.g = g def __call__(self, t): return (self.g*t**2)/2 计算地球场景的时候,我们就可以令e_dpm = g_dpm(9.8),s = e_dpm(t). class Ani
-
浅谈Python中重载isinstance继承关系的问题
判断继承关系 通过内建方法 isinstance(object, classinfo) 可以判断一个对象是否是某个类的实例.这个关系可以是直接,间接或抽象. 实例的检查是允许重载的,可见文档customizing-instance-and-subclass-checks.根据 PEP 3119的描述: The primary mechanism proposed here is to allow overloading the built-in functions isinstance() an
-
Python Matplotlib 基于networkx画关系网络图
前言 昨天才开始接触,鼓捣了一个下午,接下来会持续更新,如果哪里有错误的地方,望各位大佬指出,谢谢! 数据描述 两个文件,一个文件包含了网络图的节点,节点存在类别(0,1,2,3)四类,但是0类别舍去,不画出:另一个文件包含了网络图的边,数据基本特征如下: 图1中,id表示节点,b是类别:图2中,两个数字表示边连接的两个点. Networkx 安装 我的系统是Mac OS,直接在terminal输入sudo pip install networkx就可以安装,由于代码
-
Python中类型关系和继承关系实例详解
本文详细介绍了Python中类型关系和继承关系.分享给大家供大家参考.具体分析如下: 如果一个对象A持有另一个对象B的ID,那么检索到A之后就可以检索到B,我们就说存在一个A到B的导航.这种导航关系使得Python中所有对象之间形成了一个复杂的网络结构. Python程序的运行包括: 1. 修改这个网络结构: 2. 执行有副作用的代码对象(code object或者说bytecode,见Python Language Reference 3.2) (副作用是指影响Python虚拟机之外的设备,这