Python分析特征数据类别与预处理方法速学
目录
- 前言
- 一、特征类型判别
- 二、定量数据特征处理
- 三.定类数据特征处理
- 1.LabelEncoding
- 2.OneHotcoding
- 优点:
- 缺点:
- 应用场景:
- 无用场景:
- 代码实现
- 方法二:
前言
当我们开始准备数据建模、构建机器学习模型的时候,第一时间考虑的不应该是就考虑到选择模型的种类和方法。而是首先拿到特征数据和标签数据进行研究,挖掘特征数据包含的信息以及思考如何更好的处理这些特征数据。那么数据类型本身代表的含义就需要我们进行思考,究竟是定量计算还是进行定类分析更好呢?这就是这篇文章将要详解的一个问题。
一、特征类型判别
特征类型判断以及处理是前期特征工程重要的一环,也是决定特征质量好坏和权衡信息丢失最重要的一环。其中涉及到的数据有数值类型的数据,例如:年龄、体重、身高这类特征数据。也有字符类型特征数据,例如性别、社会阶层、血型、国家归属等数据。
按照数据存储的数据格式可以归纳为两类:
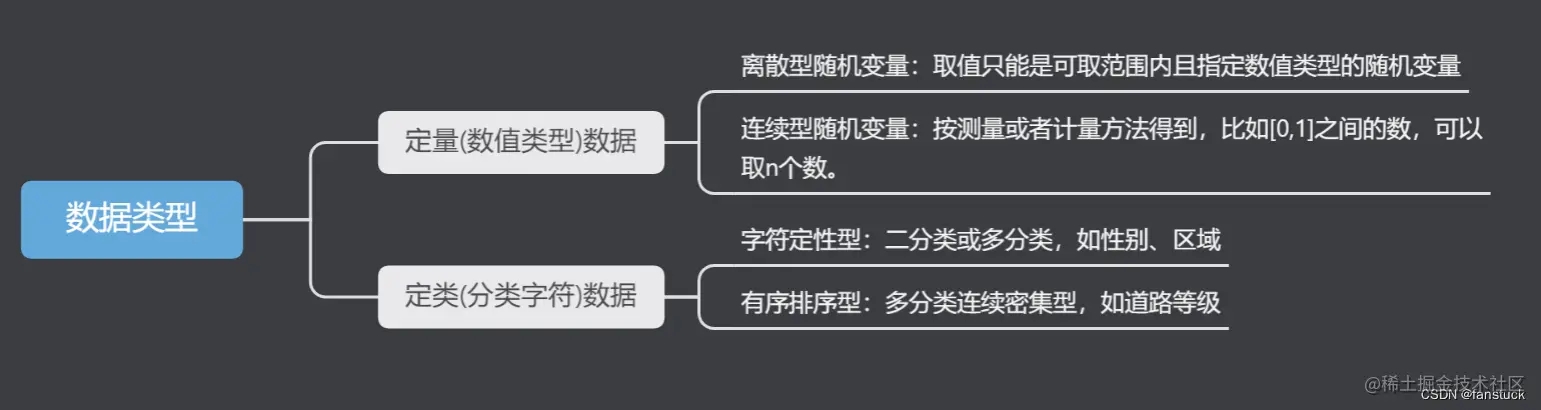
按照特征数据含义又可分为:
- 离散型随机变量:取值只能是可取范围内的指定数值类型的随机变量,比如年龄、车流量此类数据。
- 连续随机变量:按照测量或者计算方法得到,在某个范围内连取n个值,此类数据可化为定类数据。
- 二分类数据:此类数据仅只有两类:例如是与否、成功与失败。
- 多分类数据:此类数据有多类:例如天气出太阳、下雨、阴天。
- 周期型数据:此类数据存在一个周期循环:例如周数月数。
二、定量数据特征处理
拿到获取的原始特征,必须对每一特征分别进行归一化,比如,特征A的取值范围是[-1000,1000],特征B的取值范围是[-1,1].如果使用logistic回归,w1x1+w2x2,因为x1的取值太大了,所以x2基本起不了作用。所以,必须进行特征的归一化,每个特征都单独进行归一化。
关于处理定量数据我已经在:数据预处理归一化详细解释这篇文章里面讲述的很详细了,这里进行前后关联,共有min-max标准化、Z-score标准化、Sigmoid函数标准化三种方法:
根据特征数据含义类型来选择处理方法:
- 离散型随机变量处理方法:min-max标准化、Z-score标准化、Sigmoid函数标准
- 连续随机变量处理:Z-score标准化,Sigmoid函数标准
三.定类数据特征处理
我的上篇文章[数据预处理归一化详细解释]并没有介绍关于定类数据我们如何去处理,在本篇文章详细介绍一些常用的处理方法:
1.LabelEncoding
直接替换方法适用于原始数据集中只存在少量数据需要人工进行调整的情况。如果需要调整的数据量非常大且数据格式不统一,直接替换的方法也可以实现我们的目的,但是这种方法需要的工作量会非常大。因此, 我们需要能够快速对整列变量的所有取值进行编码的方法。
LabelEncoding,即标签编码,作用是为变量的 n 个唯一取值分配一个[0, n-1]之间的编码,将该变量转换成连续的数值型变量。
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() le.fit(['拥堵','缓行','畅行']) le.transform(['拥堵','拥堵','畅行','缓行'])
array([0, 0, 1, 2])
2.OneHotcoding
对于处理定类数据我们很容易想到将该类别的数据全部替换为数值:比如车辆拥堵情况,我们把拥堵标为1,缓行为2,畅行为3.那么这样是实现了标签编码的,但同时也给这些无量纲的数据转为了有量纲数据,我们本意是没有将它们比较之意的。机器可能会学习到“拥堵<缓行<畅行”,所以采用这个标签编码是不够的,需要进一步转换。因为有三种区间,所以有三个比特,即拥堵编码为100,缓行为010,畅行为001.如此一来每两个向量之间的距离都是根号2,在向量空间距离都相等,所以这样不会出现偏序性,基本不会影响基于向量空间度量算法的效果。
自然状态码为:000,001,010,011,100,101
独热编码为:000001,000010,000100,001000,010000,100000
我们可以使用sklearn的onehotencoder来实现:
from sklearn import preprocessing enc = preprocessing.OneHotEncoder() enc.fit([[0, 0, 1], [0, 1, 0], [1, 0, 0]]) # fit来学习编码 enc.transform([[0, 0, 1]]).toarray() # 进行编码
array([[1., 0., 1., 0., 0., 1.]])
数据矩阵是3*3的,那么原理是怎么来的呢?我们仔细观察:
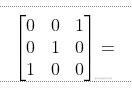
第一列的第一个特征维度有两种取值0/1,所以对应的编码方式为10、01.
第二列的第二个特征也是一样的,类比第三列的第三个特征。固001的独热编码就是101001了。
因为大部分算法是基于向量空间中的度量来进行计算的,为了使非偏序关系的变量取值不具有偏序性,并且到圆点是等距的。使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。将离散型特征使用one-hot编码,会让特征之间的距离计算更加合理。离散特征进行one-hot编码后,编码后的特征,其实每一维度的特征都可以看做是连续的特征。就可以跟对连续型特征的归一化方法一样,对每一维特征进行归一化。比如归一化到[-1,1]或归一化到均值为0,方差为1。
将离散特征通过one-hot编码映射到欧式空间,是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
优点:
独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
缺点:
当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA来减少维度。而且one hot encoding+PCA这种组合在实际中也非常有用。
应用场景:
独热编码用来解决类别型数据的离散值问题。
无用场景:
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。 Tree Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
代码实现
方法一: 实现one-hot编码有两种方法:sklearn库中的 OneHotEncoder() 方法只能处理数值型变量如果是字符型数据,需要先对其使用 LabelEncoder() 转换为数值数据,再使用 OneHotEncoder() 进行独热编码处理,并且需要自行在原数据集中删去进行独热编码处理的原变量。
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
lE = LabelEncoder()
df=pd.DataFrame({'路况':['拥堵','畅行','畅行','拥堵','畅行','缓行','缓行','拥堵','缓行','拥堵','拥堵','拥堵']})
df['路况']=lE.fit_transform(df['路况'])
OHE = OneHotEncoder()
X = OHE.fit_transform(df).toarray()
df = pd.concat([df, pd.DataFrame(X, columns=['拥堵', '缓行','畅行'])],axis=1)
df
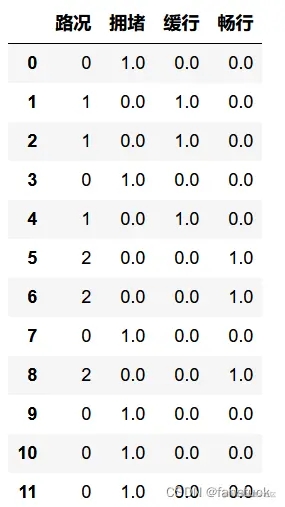
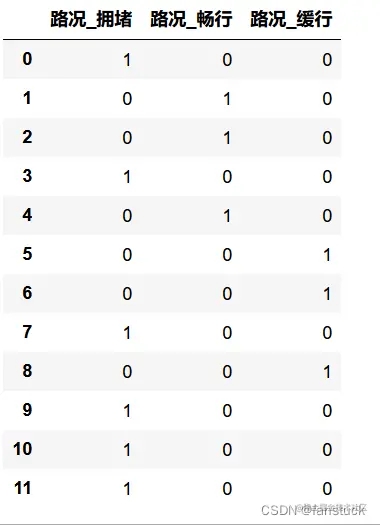
方法二:
pandas自带get_dummies()方法
get_dummies() 方法可以对数值数据和字符数据进行处理,直接在原数据集上应用该方法即可。该方法产生一个新的Dataframe,列名由原变量延伸而成。将其合并入原数据集时,需要自行在原数据集中删去进行虚拟变量处理的原变量。
import pandas as pd
df=pd.DataFrame({'路况':['拥堵','畅行','畅行','拥堵','畅行','缓行','缓行','拥堵','缓行','拥堵','拥堵','拥堵']})
pd.get_dummies(df,drop_first=False)
以上就是Python分析特征数据类别与预处理方法速学的详细内容,更多关于Python 数据类别分析预处理的资料请关注我们其它相关文章!
相关推荐
-

Python分析最近大火的网剧《隐秘的角落》
前言 估计最近很火的连续剧<隐秘的角落>大家趁着端午假期都看过了吧?小编也跟着潮流,一口气把12集的连续剧全部看完了.看过的人肯定对朋友圈里有人发的"一起去爬山"."小白船"."还有机会吗"的意思心照不宣.没看过的,如果已为人父人母的,强烈要求看一下. 剧很精彩,但追剧界有句俗话说得好:"弹幕往往比剧更精彩",为了让精彩延续下去,咱们来看看该剧弹幕的部分.电视剧是在爱奇艺独播,因此从爱奇艺上爬虫最为合适. 爬取弹幕
-
python分析实现微信钉钉等软件多开分身
目前很多软件都限制单实例,大多数软件都是用Mutex来实现的 而这个东西咱们可以用handle去干掉它,并且不影响使用. 钉钉也是一样的步骤 不过Mutex的名字不一样 我测试的钉钉的是: ”\Sessions\1\BaseNamedObjects\{{239B7D43-86D5-4E5C-ADE6-CEC42155B475}}DingTalk“ 这里要借助微软的两个软件 分别是:procexp handle 接下来开始正文: 首先咱们要手动判断下Mutex是哪个. 这就要用到procexp.e
-
利用Python分析一下最近的股票市场
目录 一.数据获取 二.合并数据 三.绘制股票每日百分比变化 四.箱线图 五.计算月化夏普比率 六.结论 一.数据获取 数据获取范围为2022年一月一日到2022年2月25日,获取的数据为俄罗斯黄金,白银,石油,银行,天然气: # 导入模块 import numpy as np import pandas as pd import yfinance as yf # GC=F黄金,SI=F白银,ROSN.ME俄罗斯石油,SBER.ME俄罗斯银行,天然气 tickerSymbols = ['GC=F
-
如何使用Python程序完成描述性统计分析需求
目录 一.前言 1.1 关于描述性统计分析 1.2 本篇目的 1.3 提示 二.程序内容的编写 2.1 导入数据与前期处理 2.2 描述性统计分析所要计算的数据 2.3 数据可视化 2.3.1 概述 2.3.2 思路 2.4 补充内容 三.完整代码与总结 一.前言 1.1 关于描述性统计分析 概括地来说,描述性统计分析就是在收集到的数据的基础上,运用制表和分类,图形以及计算概括性数据来描述数据特征的各项活动.重要的是,该方法主要内容包括频数分析.集中趋势分析.离散程度分析.分布以及一些基本的统计
-
如何利用Python分析出微信朋友男女统计图
写在前面 现在人人都有微信,一句"咱们加个微信呗"搭载了你我之间的友谊桥梁,浑然不知自己的微信朋友已经四五百了,甚至上千,几千的都有:然而那个是那个,谁是谁,是男是女都分不清楚了,今天咱们就来统计一下你微信朋友的男女比例,来看你平常喜欢加男性朋友还是女性朋友,哈哈,暴露了吧. 下面话不多说了,来一起看看详细的介绍吧 环境安装 有一个挺有意思的库是itchat,它是一个开源的微信个人接口,咱们就用itchat来统计自己微信朋友的性别比例,并且用柱状图呈现出来,使自己一目了然. (1)首先
-
Python分析微信好友性别比例和省份城市分布比例的方法示例【基于itchat模块】
本文实例讲述了Python分析微信好友性别比例和省份城市分布比例的方法.分享给大家供大家参考,具体如下: 安装itchat pip install itchat 使用 新建wxfx.py,拷贝以下代码 # -*- coding: utf-8 -*- #导入模块 from wxpy import * ''' 微信机器人登录有3种模式, (1)极简模式:robot = Bot() (2)终端模式:robot = Bot(console_qr=True) (3)缓存模式(可保持登录状态):robot
-
python分析inkscape路径数据方案简单介绍
目录 前言 inkscape生成路径 将形状转换为路径 python分析svg 前言 开发过程中有时需要使用路径数据,虽然python有自己的svg或其他矢量库,但这里只是出于实验的目的,没必要深入研究,所以采用一些简单的方案:用inkscape生成svg,然后python分析并输出,从而达到相应目的 inkscape生成路径 设置文档属性: 设置网格: 导入png图像作为参考: 注意导入图像.文档属性,都是已左下角为原点: 在图层与对象属性栏,修改图像可见性.锁定图像: 在当前图层之上新建一个
-
python中常用的九种预处理方法分享
本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍; 1. 标准化(Standardization or Mean Removal and Variance Scaling) 变换后各维特征有0均值,单位方差.也叫z-score规范化(零均值规范化).计算方式是将特征值减去均值,除以标准差. sklearn.preprocessing.scale(X) 一般会把train和test集放在一起做标准化,或者在train集上做标准化
-
Python导入txt数据到mysql的方法
本文实例讲述了Python导入txt数据到mysql的方法.分享给大家供大家参考.具体分析如下: 从TXT文本转换数据到MYSQL数据库,接触一段时间python了 第一次写东西 用的是Python2.7 #!/usr/bin/python #coding=utf-8 import _mysql,sys,io def addCity(prov,city,tel,post): try: conn=_mysql.connect("192.168.1.99",'php','php'); co
-
python神经网络学习数据增强及预处理示例详解
目录 学习前言 处理长宽不同的图片 数据增强 1.在数据集内进行数据增强 2.在读取图片的时候数据增强 3.目标检测中的数据增强 学习前言 进行训练的话,如果直接用原图进行训练,也是可以的(就如我们最喜欢Mnist手写体),但是大部分图片长和宽不一样,直接resize的话容易出问题. 除去resize的问题外,有些时候数据不足该怎么办呢,当然要用到数据增强啦. 这篇文章就是记录我最近收集的一些数据预处理的方式 处理长宽不同的图片 对于很多分类.目标检测算法,输入的图片长宽是一样的,如224,22
-
python分析网页上所有超链接的方法
本文实例讲述了python分析网页上所有超链接的方法.分享给大家供大家参考.具体实现方法如下: import urllib, htmllib, formatter website = urllib.urlopen("http://yourweb.com") data = website.read() website.close() format = formatter.AbstractFormatter(formatter.NullWriter()) ptext = htmllib.H
-
python:接口间数据传递与调用方法
如下所示: import requests import unittest import json from pubulic_way.get_token import getSession class testlogin(unittest.TestCase): def test_getIdentify(self): '''调用test_listCollectInfoByCreditId(self)响应数据中的taxid参数''' result = self.get_listCollectInfo
-
python hbase读取数据发送kafka的方法
本例子实现从hbase获取数据,并发送kafka. 使用 #!/usr/bin/env python #coding=utf-8 import sys import time import json sys.path.append('/usr/local/lib/python3.5/site-packages') from thrift import Thrift from thrift.transport import TSocket from thrift.transport import
-
教你在Excel中调用Python脚本实现数据自动化处理的方法
目录 一.为什么将Python与Excel VBA集成? 二.为什么使用xlwings? 三.玩转xlwings 这次我们会介绍如何使用xlwings将Python和Excel两大数据工具进行集成,更便捷地处理日常工作. 说起Excel,那绝对是数据处理领域王者般的存在,尽管已经诞生三十多年了,现在全球仍有7.5亿忠实用户,而作为网红语言的Python,也仅仅只有700万的开发人员. Excel是全世界最流行的编程语言.对,你没看错,自从微软引入了LAMBDA定义函数后,Excel已经可以实现编
-
python读取nc数据并绘图的方法实例
目录 获取nc数据的相关信息 绘图 用matplotlib绘图 用Basemap绘图 用Cartopy绘图 总结 获取nc数据的相关信息 from netCDF4 import Dataset import numpy as np import pandas as pd import os import matplotlib.pyplot as plt path = "F:\\OCO2.SIF.all.daily.2001.nc" csv_path = "F:\\test.c
-
Pytorch数据读取与预处理该如何实现
在炼丹时,数据的读取与预处理是关键一步.不同的模型所需要的数据以及预处理方式各不相同,如果每个轮子都我们自己写的话,是很浪费时间和精力的.Pytorch帮我们实现了方便的数据读取与预处理方法,下面记录两个DEMO,便于加快以后的代码效率. 根据数据是否一次性读取完,将DEMO分为: 1.串行式读取.也就是一次性读取完所有需要的数据到内存,模型训练时不会再访问外存.通常用在内存足够的情况下使用,速度更快. 2.并行式读取.也就是边训练边读取数据.通常用在内存不够的情况下使用,会占用计算资源,如果分
-
python数据预处理之将类别数据转换为数值的方法
在进行python数据分析的时候,首先要进行数据预处理. 有时候不得不处理一些非数值类别的数据,嗯, 今天要说的就是面对这些数据该如何处理. 目前了解到的大概有三种方法: 1,通过LabelEncoder来进行快速的转换: 2,通过mapping方式,将类别映射为数值.不过这种方法适用范围有限: 3,通过get_dummies方法来转换. import pandas as pd from io import StringIO csv_data = '''A,B,C,D 1,2,3,4 5,6,,