Python Pandas实现DataFrame合并的图文教程
目录
- 一、merge(合并)的语法:
- 二、以关键列来合并两个dataframe
- 三、理解merge时数量的对齐关系
- 1、one-to-one 一对一关系的merge
- 2、one-to-many 一对多关系的merge
- 3、many-to-many 多对多关系的merge
- 四、理解left join、right join、inner join、outer join的区别
- 1、inner join,默认
- 2、left join
- 3、 right join
- 4、 outer join
- 五、如果出现非Key的字段重名怎么办
- 总结
一、merge(合并)的语法:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
参数介绍:
left,right:要merge的dataframe或者有name的Series
how:join类型,'left', 'right', 'outer', 'inner'
on:join的key,left和right都需要有这个key
left_on:left的df或者series的key
right_on:right的df或者seires的key
left_index,right_index:使用index而不是普通的column做join
suffixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是('_x', '_y')
二、以关键列来合并两个dataframe
可以看到只有left和right的key1=y的行保留了下来,即默认合并后只保留有共同列项并且值相等行(即交集)。
本例中left和right的k1=y分别有2个,最终构成了2*2=4行
import pandas as pd
left = pd.DataFrame({'A': ['a0', 'a1', 'a2', 'a3'],
'B': ['b0', 'b1', 'b2', 'b3'],
'k1': ['x', 'x', 'y', 'y']})
right = pd.DataFrame({'C': ['c1', 'c2', 'c3', 'c4'],
'D': ['d1', 'd2', 'd3', 'd4'],
'k1': ['y', 'y', 'z', 'z']})
left

right

pd.merge(left, right, on=‘k1’)

三、理解merge时数量的对齐关系
one-to-one:一对一关系,关联的key都是唯一的
比如(学号,姓名) merge (学号,年龄)
结果条数为:1*1
one-to-many:一对多关系,左边唯一key,右边不唯一key
比如(学号,姓名) merge (学号,[语文成绩、数学成绩、英语成绩])
结果条数为:1*N
many-to-many:多对多关系,左边右边都不是唯一的
比如(学号,[语文成绩、数学成绩、英语成绩]) merge (学号,[篮球、足球、乒乓球])
结果条数为:M*N
1、one-to-one 一对一关系的merge
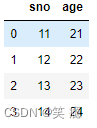
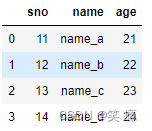
left = pd.DataFrame({'sno': [11, 12, 13, 14],
'name': ['name_a', 'name_b', 'name_c', 'name_d']
})
right = pd.DataFrame({'sno': [11, 12, 13, 14],
'age': ['21', '22', '23', '24']
})
left

right
# 一对一关系,结果中有4条 pd.merge(left, right, on='sno')
2、one-to-many 一对多关系的merge
注意:数据会被复制
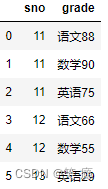
left = pd.DataFrame({'sno': [11, 12, 13, 14],
'name': ['name_a', 'name_b', 'name_c', 'name_d']
})
right = pd.DataFrame({'sno': [11, 11, 11, 12, 12, 13],
'grade': ['语文88', '数学90', '英语75','语文66', '数学55', '英语29']
})
left

right
# 数目以多的一边为准 pd.merge(left, right, on='sno')
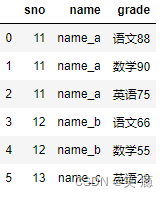
3、many-to-many 多对多关系的merge
注意:结果数量会出现乘法
left = pd.DataFrame({'sno': [11, 11, 12, 12,12],
'爱好': ['篮球', '羽毛球', '乒乓球', '篮球', "足球"]
})
right = pd.DataFrame({'sno': [11, 11, 11, 12, 12, 13],
'grade': ['语文88', '数学90', '英语75','语文66', '数学55', '英语29']
})
left

right
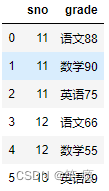
pd.merge(left, right, on=‘sno’)
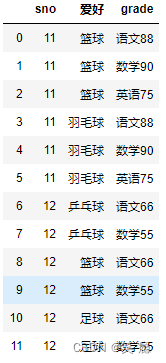
四、理解left join、right join、inner join、outer join的区别
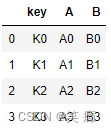
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
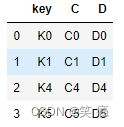
right = pd.DataFrame({'key': ['K0', 'K1', 'K4', 'K5'],
'C': ['C0', 'C1', 'C4', 'C5'],
'D': ['D0', 'D1', 'D4', 'D5']})
left
right
1、inner join,默认
左边和右边的key都有,才会出现在结果里
pd.merge(left, right, how='inner')

2、left join
左边的都会出现在结果里,右边的如果无法匹配则为Null
pd.merge(left, right, how='left')

3、 right join
右边的都会出现在结果里,左边的如果无法匹配则为Null
pd.merge(left, right, how='right')
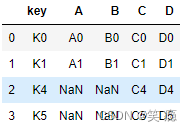
4、 outer join
左边、右边的都会出现在结果里,如果无法匹配则为Null
pd.merge(left, right, how='outer')
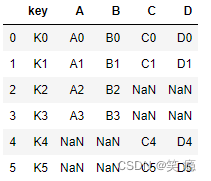
五、如果出现非Key的字段重名怎么办
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K4', 'K5'],
'A': ['A10', 'A11', 'A12', 'A13'],
'D': ['D0', 'D1', 'D4', 'D5']})
left
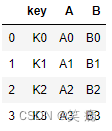
right

pd.merge(left, right, on='key')

pd.merge(left, right, on='key', suffixes=('_left', '_right'))

总结
到此这篇关于Pandas实现DataFrame合并的文章就介绍到这了,更多相关Pandas DataFrame合并内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python DataFrame使用drop_duplicates()函数去重(保留重复值,取重复值)
摘要 在进行数据分析时,我们经常需要对DataFrame去重,但有时候也会需要只保留重复值. 这里就简单的介绍一下对于DataFrame去重和取重复值的操作. 创建DataFrame 这里首先创建一个包含一行重复值的DataFrame. 2.DataFrame去重,可以选择是否保留重复值,默认是保留重复值,想要不保留重复值的话直接设置参数keep为False即可. 3.取DataFrame重复值.大多时候我们都是需要将数据去重,但是有时候很我们也需要取重复数据,这个时候我们就可以根据刚刚上面我们
-
python之DataFrame实现excel合并单元格
在工作中经常遇到需要将数据输出到excel,且需要对其中一些单元格进行合并,比如如下表表格,需要根据A列的值,合并B.C列的对应单元格 pandas中的to_excel方法只能对索引进行合并,而xlsxwriter中,虽然提供有merge_range方法,但是这只是一个和基础的方法,每次都需要编写繁琐的测试才能最终调好,而且不能很好的重用.所以想自己写一个方法,结合dataframe和merge_range.大概思路是: 1.定义一个MY_DataFrame类,继承DataFrame类,这样能很
-

python中DataFrame数据合并merge()和concat()方法详解
目录 merge() 1.常规合并 ①方法1 ②方法2 重要参数 合并方式 left right outer inner 2.多对一合并 3.多对多合并 concat() 1.相同字段的表首位相连 2.横向表合并(行对齐) 3.交叉合并 总结 merge() 1.常规合并 ①方法1 指定一个参照列,以该列为准,合并其他列. import pandas as pd df1 = pd.DataFrame({'id': ['001', '002', '003'], 'num1': [120, 101,
-
Python Dataframe 指定多列去重、求差集的方法
1)去重 指定多列去重,这是在dataframe没有独一无二的字段作为PK(主键)时,需要指定多个字段一起作为该行的PK,在这种情况下对整体数据进行去重. Attention:主要用到了drop_duplicates方法,并设置参数subset为多个字段名构成的数组. 具体代码如下: >>>import pandas as pd >>>data={'state':[1,1,2,2,1,2,2],'pop':['a','b','c','d','b','c','d']} &
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
python pandas dataframe 去重函数的具体使用
今天笔者想对pandas中的行进行去重操作,找了好久,才找到相关的函数 先看一个小例子 from pandas import Series, DataFrame data = DataFrame({'k': [1, 1, 2, 2]}) print data IsDuplicated = data.duplicated() print IsDuplicated print type(IsDuplicated) data = data.drop_duplicates() print data 执行
-
关于python DataFrame的合并方法总结
目录 python DataFrame的合并方法 #concat函数 #merge函数 #append函数 把两个dataframe合并成一个 python DataFrame的合并方法 Python的Pandas针对DataFrame,Series提供了多个合并函数,通过参数的调整可以轻松实现DatafFrame的合并. 首先,定义3个DataFrame df1,df2,df3,进行concat.merge.append函数的实验. df1=pd.DataFrame([[1,2,3],[2,3
-
Python数据分析之 Pandas Dataframe合并和去重操作
目录 一.之 Pandas Dataframe合并 二.去重操作 一.之 Pandas Dataframe合并 在数据分析中,避免不了要从多个数据集中取数据,那就避免不了要进行数据的合并,这篇文章就来介绍一下 Dataframe 对象的合并操作. Pandas 提供了merge()方法来进行合并操作,使用语法如下: pd.merge(left, right, how="inner", on=None, left_on=None, right_on=None, left_index=Fa
-
python Dataframe 合并与去重详情
目录 1.合并 1.1 结构合并 1.1.1 concat函数 1.1.2 append函数 1.2 字段合并 2.去重 1.合并 1.1 结构合并 将两个结构相同的数据合并 1.1.1 concat函数 函数配置: concat([dataFrame1, dataFrame2,-], index_ingore=False) 参数说明:index_ingore=False(表示合并的索引不延续),index_ingore=True(表示合并的索引可延续) 实例: import pandas as
-
Python Pandas实现DataFrame合并的图文教程
目录 一.merge(合并)的语法: 二.以关键列来合并两个dataframe 三.理解merge时数量的对齐关系 1.one-to-one 一对一关系的merge 2.one-to-many 一对多关系的merge 3.many-to-many 多对多关系的merge 四.理解left join.right join.inner join.outer join的区别 1.inner join,默认 2.left join 3. right join 4. outer join 五.如果出现非K
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
Python Pandas工具绘制数据图使用教程
目录 背景介绍 折线图 条形图 水平条形图 堆积图 散点图 饼图 蜂巢图 箱线图 绘制子图 背景介绍 Pandas的DataFrame和Series在Matplotlib基础上封装了一个简易的绘图函数,使得数据处理过程中方便可视化查看结果. 折线图 import pandas as pd import numpy as np import matplotlib.pyplot as plt data=np.random.randn(5,2)*10 df=pd.DataFrame(np.abs(da
-
Python Pandas的concat合并
目录 使用场景 concat语法 append语法 案例演示 使用场景 批量合并相同格式的Exce,给DataFrame添加行,给DataFrame添加列 使用说明: 1.使用某种合并方式(inner/outer) 2.沿着某个轴向(axis=0/1) 3.把多个Pandas对象(DataFrame/Series)合并成一个 concat语法 pandas.concat(objs,axis=0,join=‘outer’,ignore_index = False) objs:一个列表,内容可以是D
-
python mac下安装虚拟环境的图文教程
Mac 下 Flask 框架 workon命令找不到 ---- 最终解决方案(详解具体实现操作过程中遇到的坑)2018年08月17日 00:02:05Jasonmes阅读数:622 Mac 下 Flask 的 全网最详细搭建1.安装virtualenv和virtualenvwrapper sudo pip install virtualenv# 以下成功截图 sudo pip install virtualenvwrapper# 以下成功截图 创建存放虚拟环境的文件夹并切换到该文件夹下 mkdi
-
python pandas分割DataFrame中的字符串及元组的方法实现
目录 1.使用str.split()方法 2.使用join()与split()方法结合 3.使用apply方法分割元组 1.使用str.split()方法 可以使用pandas 内置的 str.split() 方法实现分割字符串类型的数据,并将分割结果写入DataFrame中,以表格形式呈现. 语法: Series.str.split(pat=None, n=-1, expand=False) 其中,pat是字符串或正则表达式,n是一个整数数字,默认为-1.为0或-1时即为最大次数的分割.其他数
-
Python Pandas中DataFrame.drop_duplicates()删除重复值详解
目录 语法 参数 结果展示 扩展:识别重复值 总结 语法 df.drop_duplicates(subset = None, keep = 'first', inplace = False, ignore_index = False) 参数 1.subset:指定的标签或标签序列,仅删除这些列重复值,默认情况为所有列 2.keep:确定要保留的重复值,有以下可选项: first:保留第一次出现的重复值,默认 last:保留最后一次出现的重复值 False:删除所有重复值 3.inplace:是否
-
python Pandas之DataFrame索引及选取数据
目录 1.索引是什么 1.1 认识索引 1.2 自定义索引 2. 索引的简单使用 2.1 列索引 2.2 行索引 2.2.1 使用[ ] 2.2.2 使用.loc()和.iloc() 1.索引是什么 1.1 认识索引 先创建一个简单的DataFrame. myList = [['a', 10, 1.1], ['b', 20, 2.2], ['c', 30, 3.3], ['d', 40, 4.4]] df1 = pd.DataFrame(data = myList) print(df1) ---
-
windows下python 3.6.4安装配置图文教程
windows下python的安装教程,供大家参考,具体内容如下 -–因为我是个真小白,网上的大多入门教程并不适合我这种超级超级小白,有时候还会遇到各种各样的问题,因此记录一下我的安装过程,希望大家都能入门愉快,欢迎指教 -–本文针对超级小白,内容可能会引起各路大神不适,请谨慎观看 1. 打开官网/www.python.org,选择Downloads 2. 然后在这里选择要安装的版本3.X.X或者2.X.X 3. 2.X.X和3.X.X的下载(2和3需要下载的文件名字不太一样,需要注意一下下载什
-
python 3.8.3 安装配置图文教程
python安装教程(配置环境变量),供大家参考,具体内容如下 人生苦短,我用python 直接在官网下载安装包.msi文件进行安装: 下载python 注意:浏览器左下角下载(点击后,会自动下载) 安装python 1.完成后点击下一步 2. 下一步后,将这几个全部勾选上(自动安装pip等软件包) 3.下一步后,再次勾选[这里把Python的环境变量已经加了,但是后续要使用pip的时候就需要手动加一下环境变量],点击安装 查看环境变量是否有python的环境变量 在命令窗口输入 python