Python数据可视化制作全球地震散点图
目录
- 查看JSON数据
- 参数indent
- 创建地震列表
- 提取震级
- 提取位置数据
- 绘制震级散点图
- 指定图表数据的方式
- DataFrame()函数
- 设计标记点的尺寸
- 设计标记的颜色
前言:
为了制作全球地震散点图,我在网上下载了一个数据集,其中记录了一个月内全球发生的所有地震,但这些数据是以JSON格式存储的,因此需要用json模块来进行处理。
查看JSON数据
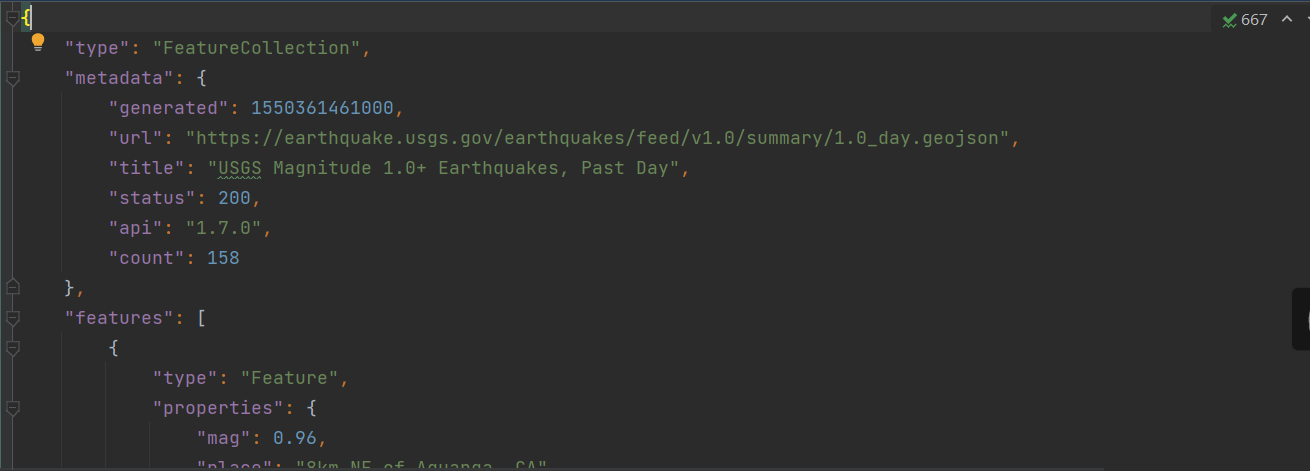
首先我们先打开下载好的数据集浏览一下:

你会发现其中的数据密密麻麻,根本不是人读的,因此,接下来我们将对数据进行处理,让它变得简单易读。
import json#导入json模块,以便于加载文件中的数据
filename='eq_data_1_day_m1.json'
with open(filename) as f:
all_eq_data=json.load(f)#json.load(),将数据转化为Python能够处理的格式
readable_file='eq_data_1_day_m1.json'#创建一个文件,以便将这些数据以易于阅读的方式写入其中
with open(readable_file,'w') as f:
json.dump(all_eq_data,f,indent=4)#json.dump()将数据读入其中
#参数indent让dump()使用与数据结构匹配的缩进量来设置数据的格式
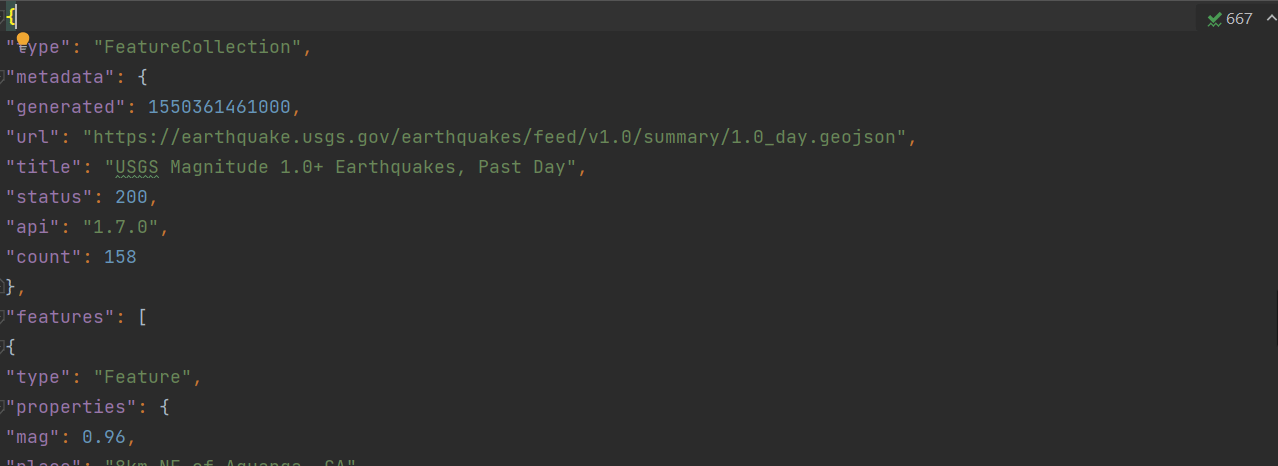
经过处理之后,我们再打开这个文件会发现里面的数据变得清晰了许多。
从中我们能够快速获取数据的很多信息,比如地震的次数,类型等等,不仅如此,我们还能够知道有关这些数据的一些信息,比如,它的生成时间,他在网页上怎么获取等等。
参数indent
如果indent是非负整数或字符串,则JSON数组元素和对象成员将使用该缩进级别进行打印。如果indent为0,负数或“”只会插入换行符。
None(默认)则选择最紧凑的表示形式。,使用正整数缩进会使每个级别缩进多个空格。,如果缩进是字符串(例如“
t”),则该字符串用于缩进每个级别。
当我们将缩进量修改为0时,文件的排版也会发生变化:
json.dump(all_eq_data,f,indent=0)
创建地震列表
import json
filename='eq_data_1_day_m1.json'
with open(filename) as f:
all_eq_data=json.load(f)#对文件进行处理
all_eq_dicts=all_eq_data['features']
print(len(all_eq_dicts))#提取出这个文件记录的所有地震
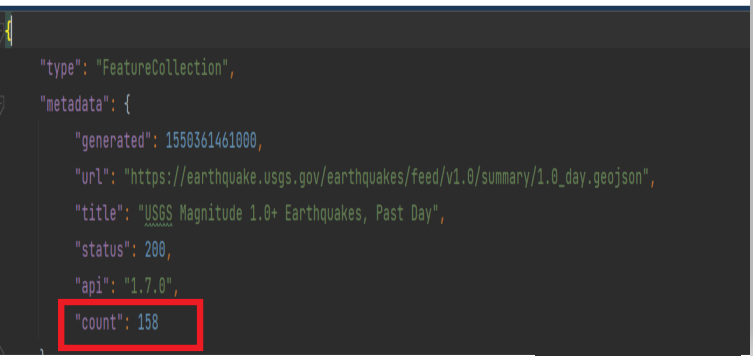
输出结果如下:
158
是的,从文件的开头,我们就可以确定地震的次数为158次,因此输出结果正确:
提取震级
方法即是新建立一个列表用来存放震源的有关数据,再提取字典features的properties部分的mag.
代码如下:
import json
filename='eq_data_1_day_m1.json'
with open(filename) as f:
all_eq_data=json.load(f)
all_eq_dicts=all_eq_data['features']
mags=[]
for eq_dict in all_eq_dicts:
mag=eq_dict['properties']['mag']
mags.append(mag)
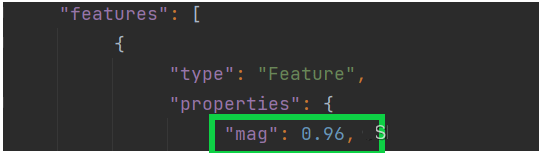
print(mags[:10])#打印前十次的震级数据
[0.96, 1.2, 4.3, 3.6, 2.1, 4, 1.06, 2.3, 4.9, 1.8]
提取位置数据
首先,我们需要在文件中找到关于经度和维度的部分,如下所示,我们在文件中查找到,它是存在于geometry字典下,coordinates键中的。
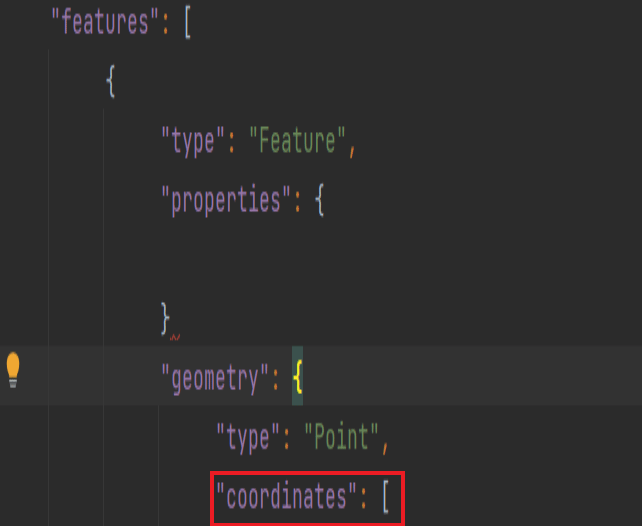
---snip---
all_eq_dicts=all_eq_data['features']
mags,titles,lons,lats=[],[],[],[]
for eq_dict in all_eq_dicts:
mag=eq_dict['properties']['mag']
title=eq_dict['properties']['title']
lon=eq_dict['geometry']['coordinates'][0]#提取coordinates键中索引值为0的数据
lat=eq_dict['geometry']['coordinates'][1]
mags.append(mag)
titles.append(title)
lons.append(lon)
lats.append(lat)
print(mags[:10])
print(titles[:2])
print(lons[:5])#输出前五个经度
print(lats[:5])#输出前五个维度
输出结果如下:
[0.96, 1.2, 4.3, 3.6, 2.1, 4, 1.06, 2.3, 4.9, 1.8]
['M 1.0 - 8km NE of Aguanga, CA', 'M 1.2 - 11km NNE of North Nenana, Alaska']
[-116.7941667, -148.9865, -74.2343, -161.6801, -118.5316667]
[33.4863333, 64.6673, -12.1025, 54.2232, 35.3098333]
绘制震级散点图
通过我们前面提取的有关震源的数据,下面我们可对提取的数据进行可视化作图:
import plotly.express as px#Plotly Express是Plotly的高级接口,相当于Matplotlib是一个工具
fig=px.scatter(
x=lons,
y=lats,
labels={'x':'经度','y':'维度'},
range_x=[-200,200],
range_y=[-90,90],
#width和height代表图表的高度和宽度均为800像素
width=800,
height=800,
title="全球地震散点图",
)
fig.write_html('global_earthquakes.html')#将可视化图保存为html文件
fig.show()
散点图配置完成后,下面我们在程序目录下寻找我们保存的可视化图(global_earthquakes.html),再使用浏览器打开该html文件
如下所示,即为散点图:
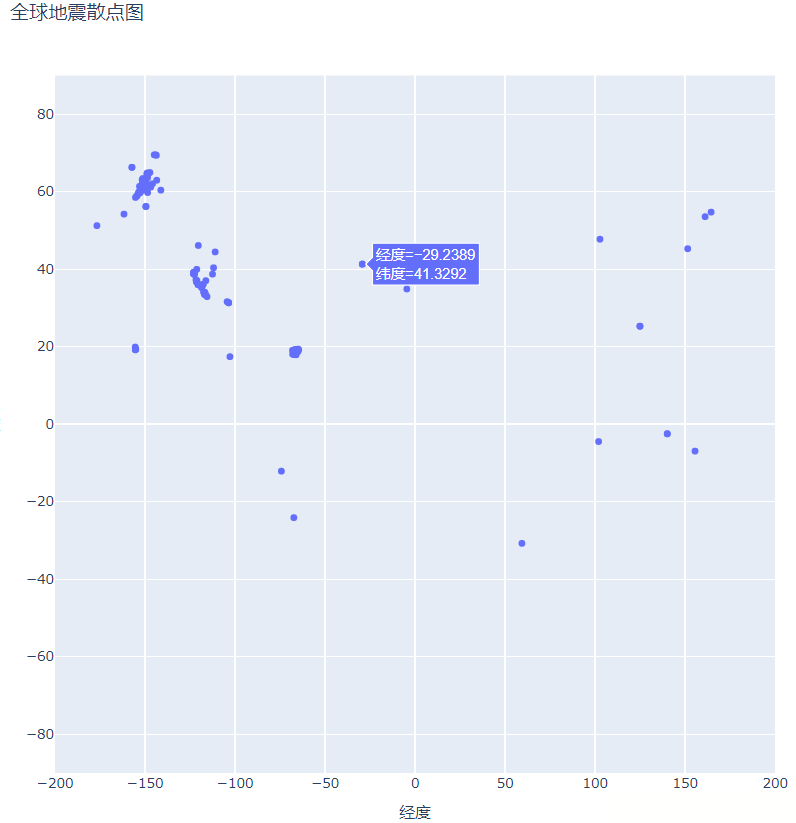
指定图表数据的方式
上面我们绘制地震散点图是通过手动配置经纬度,通过将x,y和经度,纬度建立联系:
x=lons,
y=lats,
labels={'x':'经度','y':'维度'},
但这在数据处理过程中并不是最简单的方式,下面我们介绍另一种图表指定数据的方式,需要结合我们上面所提到的pandas数据分析工具。
import pandas as pd#导入pandas模块x data=pd.DataFrame(data=zip(lons,lats,titles,mags),colums=['经度','纬度','位置','震级'])#使用DataFrame将需要处理的数据封装,注意:DataFrame后面的两个参数是可选的,如果这两个参数存在的话,这两个参数的长度要和DataFrame的长度匹配 #zip()函数的作用:将可迭代的对象中的对应元素打包为多个元祖,再返回由这些元祖组成的列表 data.head()
DataFrame()函数
它是Python中pandas库中的一种数据结构,和excel比较相似,它不仅可以设置列名columns和行名index,而且它的单元格可以存放数值,字符串等。
data.head():返回数据的前几行数据,默认是前五行,如果需要指定则写data.head(‘指定的行数’)
data.tail():返回data的后几行数据,默认为后五行,如果需要指定则写data.tail(‘指定的行数’)
数据封装好之后,参数的配置方式可修改为:
data, x='经度', y='纬度',
现在我们通过这种参数配置方式进行地震散点图的绘制:
#创建地震列表,提取数据
import json
filename='eq_data_1_day_m1.json'
with open(filename) as f:
all_eq_data=json.load(f)
all_eq_dicts=all_eq_data['features']
mags,titles,lons,lats=[],[],[],[]
for eq_dict in all_eq_dicts:
mag=eq_dict['properties']['mag']
title=eq_dict['properties']['title']
lon=eq_dict['geometry']['coordinates'][0]#提取coordinates键中索引值为0的数据
lat=eq_dict['geometry']['coordinates'][1]
mags.append(mag)
titles.append(title)
lons.append(lon)
lats.append(lat)
#参数配置设置
import pandas as pd
data=pd.DataFrame(
data=zip(lons,lats,titles,mags),columns=['经度','纬度','位置','震级']
)
data.head()
#绘制散点图
import plotly.express as px
fig = px.scatter(
data,
x='经度',
y='纬度',
range_x=[-200, 200],
range_y=[-90, 90],
width=800,
height=800,
title="全球地震散点图",
)
fig.write_html('global_earthquake.html')
fig.show()
配置完成后,下面我们在程序目录下寻找我们保存的可视化图(global_earthquakes.html),再使用浏览器打开该html文件如下图所示:
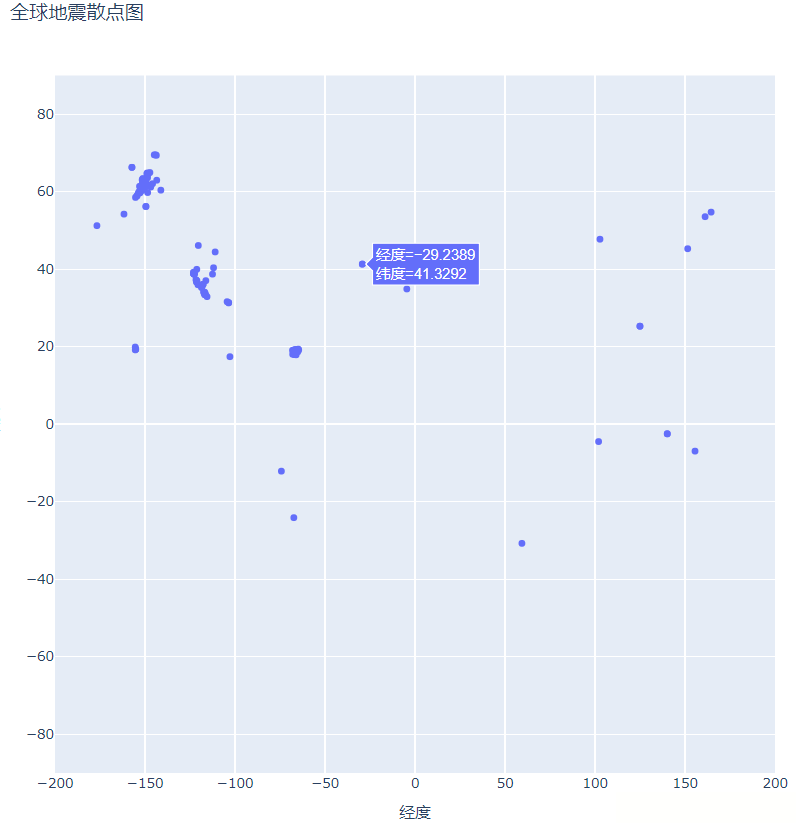
通过输出结果,我们可得出,无论使用那种参数配置方式,其输出结果都是相同的,但第二种这种以键值对的方式,更加清晰。
设计标记点的尺寸
和我们上篇文章提到的与温度有关的散点图相类似,我们希望知道最高温度和最低温度等这些特殊且重要的信息,那么震源散点图也是如此,上图我们所设计的震源散点图只是将纬度和经度在图上呈现出来了,但震源并没有体现。
下面,我们将震级也呈现在散点图上:
方法:使用size参数设计散点图中每个尺寸的大小:
size='震级', size_max=10,
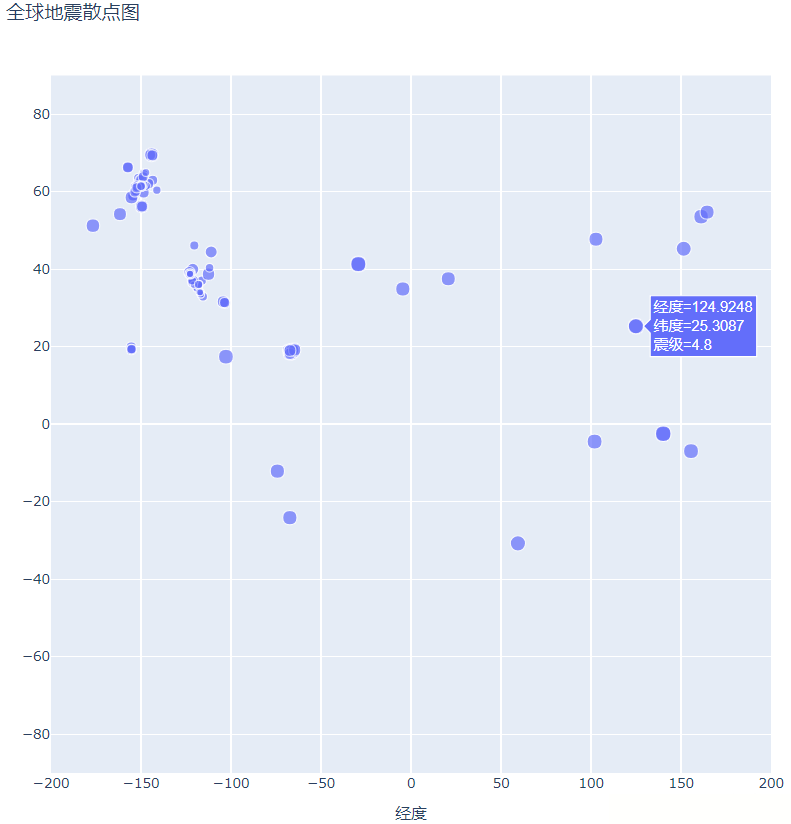
对比上面的两幅图,我们会发现散点图中关于地震的信息还增加了震级,不仅如此,散点的尺寸大小也与震级的大小有关,震级越大,散点的尺寸越大,这样一来,我们很容易观察到不同地方的地震强度,但这还不够直观,为了能够更加直白的呈现地震的情况,我们还设计散点的颜色以便更加清晰的显示。
设计标记的颜色
方法:
color='震级', #默认渐变色的范围是从蓝到红再到黄,数值越小标记越蓝,而数值越大则标记越黄。
把在网上下载好的近30天的数据文件复制到该程序目录下,将参数color添加其中,再绘制散点图。,注意修改文件名。
如下图所示:

美化后的散点图,不仅在颜色上漂亮了许多,渐变的颜色也更加清晰的反映了地震的严重程度。
获取Plotly Express中所有的渐变色:
不仅如此,Plotly Express还为我们提供了许多的渐变色,而这些渐变色是在px.colors.named_colorscales()中定义的,下面来获取这些渐变色:
import plotly.express as px
for key in px.colors.named_colorscales():
print(key,end='/')
输出结果如下:
aggrnyl/agsunset/blackbody/bluered/blues/blugrn/bluyl/brwnyl/bugn/bupu/burg/burgyl/cividis
/darkmint/electric/emrld/gnbu/greens/greys/hot/inferno/jet/magenta/magma/mint/orrd/oranges
/oryel/peach/pinkyl/plasma/plotly3/pubu/pubugn/purd/purp/purples/purpor/rainbow/rdbu/rdpu
/redor/reds/sunset/sunsetdark/teal/tealgrn/turbo/viridis/ylgn/ylgnbu/ylorbr/ylorrd/algae
/amp/deep/dense/gray/haline/ice/matter/solar/speed/tempo/thermal/turbid/armyrose/brbg/earth
/fall/geyser/prgn/piyg/picnic/portland/puor/rdgy/rdylbu/rdylgn/spectral/tealrose/temps/tropic
/balance/curl/delta/oxy/edge/hsv/icefire/phase/twilight/mrybm/mygbm/
此外,我们还可将对应配色列表进行反转:
方法:
px.colors.diverging.RdYlGn[::-1]
此外,Plotly除了有px.colors.diverging表示连续的配色方案,还有px.colors.sequential和px.colors.qualitative表示离散变量。每个渐变色都有起始色和终止色,有些渐变色还定义了一个或多个中间色。
添加鼠标指向时显示的文本:
方法,使用参数hover_name,参数配置为data的‘位置’
hover_name='位置',
修改后,散点图的输出如下所示:
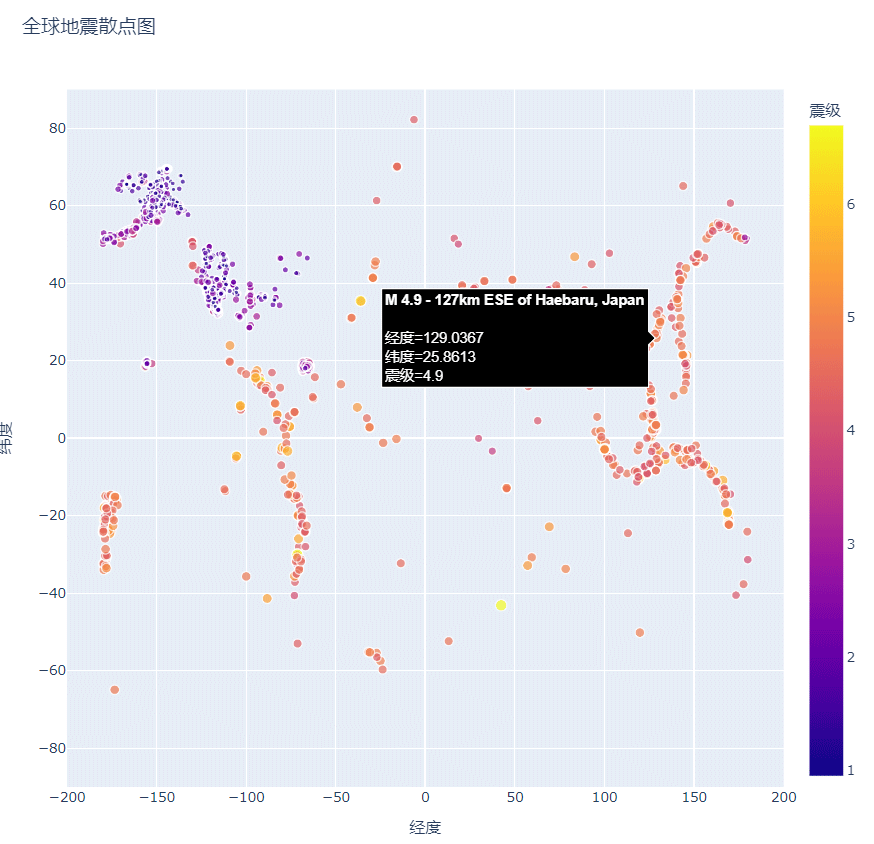
我们发现,对比于前面的图表,此时又增加了位置信息,此时,我们就完整的绘制了一副关于地震信息的散点图。
到此这篇关于Python数据可视化制作全球地震散点图的文章就介绍到这了,更多相关Python地震散点图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python可视化分析绘制散点图和边界气泡图
目录 一.绘制散点图 二.绘制边界气泡图 一.绘制散点图 实现功能: python绘制散点图,展现两个变量间的关系,当数据包含多组时,使用不同颜色和形状区分. 实现代码: import numpy as np import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns import warnings warnings.filterwarnings(action
-
Python+Pyecharts实现散点图的绘制
目录 第1关:Scatter:散点图(一) 编程要求 代码 测试说明 第2关:Scatter:散点图(二) 编程要求 代码 测试说明 第3关:Scatter:散点图(三) 编程要求 代码 测试说明 第1关:Scatter:散点图(一) 编程要求 根据以上介绍,在右侧编辑器补充代码,绘制给定数据的散点图,要求: 画布大小初始化为宽 1600 像素,高 1000 像素 X 轴数据设置为 x_data 添加 Y 轴数据.系列名称设置为空,数据使用 y_data,标记的大小设置为20,不显示标签 X 轴
-
python可视化分析绘制带趋势线的散点图和边缘直方图
目录 一.绘制带趋势线的散点图 二.绘制边缘直方图 一.绘制带趋势线的散点图 实现功能: 在散点图上添加趋势线(线性拟合线)反映两个变量是正相关.负相关或者无相关关系. 实现代码: import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns import warnings warnings.filterwarnings(action='once') plt.s
-
python matplotlib库绘图实战之绘制散点图
目录 一.导入库 二.设置文字 三.设置坐标轴参数 四.绘制点 五.对点的继续处理 1.自定义颜色 2.颜色映射 补充1 补充2 补充3 总结 一.导入库 import matplotlib.pyplot as plt 二.设置文字 plt.title("double number", fontsize=24) plt.xlabel("number", fontsize=14) plt.ylabel("double", fontsize=14)
-
Python中Matplotlib的点、线形状、颜色以及绘制散点图
目录 常用颜色: 常用标记点形状: 常用线形: 绘制散点图 补充:Python散点图教程 总结 我们在Python中经常使用会用到matplotlib画图,有些曲线和点的形状.颜色信息长时间不用就忘了,整理一下便于查找. 安装matplotlib后可以查看官方说明(太长不贴出来了) from matplotlib import pyplot as plt help(plt.plot) 常用颜色: 'b' 蓝色'g' 绿色'r' 红色'c'
-
Python绘制散点图之可视化神器pyecharts
目录 散点图 什么是散点图? 散点图有什么用处? 散点图的基本构成要素 散点图模板系列 简单散点图 多维数据散点图 散点图显示分割线 散点图凸出大小(二维) 3D散点图展示 动态涟漪散点图 箭头标志散点图 散点图 什么是散点图? 散点图是指在数理统计回归分析中,数据点在直角坐标系平面上的分布图, 散点图表示因变量随自变量而变化的大致趋势,由此趋势可以选择合适的函数进行经验分布的拟合,进而找到变量之间的函数关系. 散点图有什么用处? 1.数据用图表来展示,显然比较直观,在工作汇报等场合能起到事
-
python使用seaborn绘图直方图displot,密度图,散点图
目录 一.直方图distplot() 二.密度图 2.1 单个样本数据分布密度图 一.直方图distplot() import numpy as np import seaborn as sns import matplotlib.pyplot as plt import matplotlib import pandas as pd fig = plt.figure(figsize=(12, 5)) ax1 = plt.subplot(121) rs = np.random.RandomStat
-
Python绘制简单散点图的方法
散点图,顾名思义是一些散乱的点构成的图.那么这些散乱的点有什么作用呢?散点图通过用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式. 绘制方法大体上与折线图一致,只是对点不需要去拟合折线,使用plt.scatter()函数替代plt.plot()即可.例如绘制三月份与十一月份的气温散点图,代码如下: ''' 绘制散点图,要点:plt.scatter(x,y) ''' # 导入模块 from matplotlib import pyplot a
-
Python数据分析之 Matplotlib 散点图绘制
前言: 散点图,又称散点分布图,是使用多个坐标点的分布反映数据点分布规律.数据关联关系的图表,Matplotlib 中可以通过以下方式绘制散点图: 使用plt.plot方法: 在上篇文章Python数据分析之 Matplotlib 折线图绘制中,我们介绍了可以使用plt.plot()方法绘制折线图,该方法同样可以绘制散点图,如下: import random x = range(15) y = [i + random.randint(-2,2) for i in x] plt.plot(x, y
-
Python数据可视化制作全球地震散点图
目录 查看JSON数据 参数indent 创建地震列表 提取震级 提取位置数据 绘制震级散点图 指定图表数据的方式 DataFrame()函数 设计标记点的尺寸 设计标记的颜色 前言: 为了制作全球地震散点图,我在网上下载了一个数据集,其中记录了一个月内全球发生的所有地震,但这些数据是以JSON格式存储的,因此需要用json模块来进行处理. 查看JSON数据 首先我们先打开下载好的数据集浏览一下: 你会发现其中的数据密密麻麻,根本不是人读的,因此,接下来我们将对数据进行处理,让它变得简单易读.
-
Python数据可视化Pyecharts制作Heatmap热力图
目录 HeatMap:热力图 1.基本设置 2.热力图数据项 Demo 举例 1.基础热力图 本文介绍基于 Python3 的 Pyecharts 制作 Heatmap(热力图 时需要使用的设置参数和常用模板案例,可根据实际情况对案例中的内容进行调整即可. 使用 Pyecharts 进行数据可视化时可提供直观.交互丰富.可高度个性化定制的数据可视化图表.案例中的代码内容基于 Pyecharts 1.x 版本 . HeatMap:热力图 1.基本设置 class HeatMap( # 初始化配置项
-
Python数据可视化之用Matplotlib绘制常用图形
一.散点图 散点图用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式. 特点:判断变量之间是否存在数量关联趋势,表示离群点的分布规律. 散点图绘制: plt.scatter(x,y) # 以默认的形状颜色绘制散点图 实例: 假设我们获取到了上海2020年5,10月份每天白天的最高气温(分别位于列表a.b),那么此时如何观察气温和随时间变化的某种规律. # 绘制图形所需的数据 y_5 = [11,17,16,11,12,11,12,13,10,14,8
-
学会Python数据可视化必须尝试这7个库
目录 一.Seaborn 二.Plotly 三.Geoplotlib 四.Gleam 五.ggplot 六.Bokeh 七.Missingo 一.Seaborn Seaborn 建于 matplotlib 库的之上.它有许多内置函数,使用这些函数,只需简单的代码行就可以创建漂亮的绘图.它提供了多种高级的可视化绘图和简单的语法,如方框图.小提琴图.距离图.关节图.成对图.热图等. 安装 ip install seaborn 主要特征: 可用于确定两个变量之间的关系. 在分析单变量或双变量分布时进行
-
python数据可视化之matplotlib.pyplot基础以及折线图
不论是数据挖掘还是数据建模,都免不了数据可视化的问题.对于Python来说,Matplotlib是最著名的绘图库,它主要用于二维绘图,当然它也可以进行简单的三维绘图(基于spyder). - 模块引用 import matplotlib.pyplot as plt #引用画图库中的pyplot模块 -折线条图 语法 import matplotlib.pyplot as plt data=[1,2,3,4,5,4,2,4,6,7] #随便创建了一个数据 plt.plot(data) #引用画图库
-
Python 数据可视化实现5种炫酷的动态图
本文将介绍 5 种基于 Plotly 的可视化方法,你会发现,原来可视化不仅可用直方图和箱形图,还能做得如此动态好看甚至可交互. 那么,Plotly 有哪些好处?Plotly 的整合能力很强:可与 Jupyter Notebook 一起使用,可嵌入网站,并且完整集成了 Dash——一种用于构建仪表盘和分析应用的出色工具. 启动 如果你还没安装 Plotly,只需在你的终端运行以下命令即可完成安装: pip install plotly 安装完成后,就开始使用吧! 动画 在研究这个或那个指标的演变
-
详解Python数据可视化编程 - 词云生成并保存(jieba+WordCloud)
思维导图: 效果(语句版): 源码: # -*- coding: utf-8 -*- """ Created on Tue Mar 5 17:59:29 2019 @author: dell """ # ============================================================================= # 步骤: # 分割aaa = jieba.cut(str,cut_all=True/Fa
-
Python数据可视化实现漏斗图过程图解
项目实现知识点: Pandas库及pyecharts库 Pandas:数据分析和处理工具. pd.read_csv():读取csv文件. pyecharts:绘图库,提供30多种图标,超过400个以上的地图文件,支持原生百度地图,为地理数据可视化提供支持. pyecharts.charts:提供了基本的图表,例如条形图.直方图等. Python数据可视化:漏斗图的制作 项目实现过程: 1.导入模块 2.打开文件 3.读取数据 4.整理数据 5.创建漏斗图 6.添加组件 7.显示漏斗并设置名称 8
-
Python数据可视化之基于pyecharts实现的地理图表的绘制
一.例子:百度迁徙 百度地图春节人口迁徙大数据(简称百度迁徙),是百度在2014年春运期间推出的一项技术项目.百度迁徙利用大数据,对其拥有的LBS(基于地理位置的服务)大数据进行计算分析,采用的可视化呈现方式,动态.即时.直观地展现中国春节前后人口大迁徙的轨迹与特征. 网址:https://qianxi.baidu.com/2021/ 二.基础语法介绍 语法 说明 from pyecharts.charts import Geo 导入地图库 Geo() Pyecharts地理图表绘制 .add_
-
如何用Python数据可视化来分析用户留存率
关于"漏斗图" 漏斗图常用于用户行为的转化率分析,例如通过漏斗图来分析用户购买流程中各个环节的转化率.当然在整个分析过程当中,我们会把流程优化前后的漏斗图放在一起,进行比较分析,得出相关的结论,今天小编就用"matplotlib"."plotly"以及"pyecharts"这几个模块来为大家演示一下怎么画出好看的漏斗图首先我们先要导入需要用到的模块以及数据, import matplotlib.pyplot as plt im