MySql执行流程与生命周期详解
目录
- 一、MySQL 客户端
- 二、MySQL 服务端
- 1. 查询缓存
- 2. SQL 解析器
- 3. 查询优化器
- 4. SQL 执行器
- 总结
我们经常会在一起讨论怎样优化 SQL、怎样优化数据库,那么请问你知道执行一条 SQL 的过程中都经过了哪些动作吗?如果不知道的话,又怎么去优化 SQL、优化数据库呢?为了更好地优化 MySQL 数据库,接下来我们就来讨论一下执行一条 SQL 都经过哪些步骤。
为了方便理解,在介绍 SQL 执行流程之前,我们先通过一张图,来详细阐述一下 SQL 执行流程。
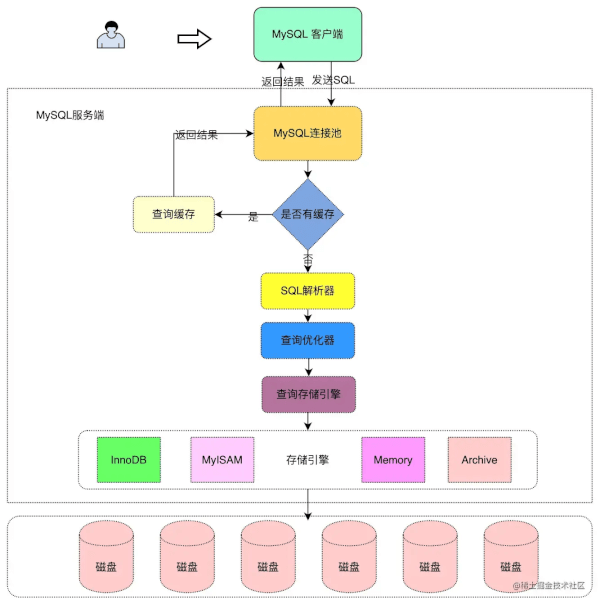
由上图,可以得出:在 MySQL 中,我们大致可以分为三个部分,分别是MySQL 客户端、MySQL 服务端和存储层。其中,存储层主要是硬件层面,不在今天讨论的范围内,所以这里我们主要讨论前两者。
一、MySQL 客户端
我们应该都听说过 MySQL 数据库支持很多编程语言的 API 接口,其实这句话底层的含义是很多编程语言是内置 MySQL 客户端。除此之外,MySQL 还有一个常用的客户端就是 MySQL 数据库自带的一个 mysql 命令,这个命令使用如下:
$ mysql -u$username -p$password -h$host -P$port
备注:
- username 是用户名
- password 是密码
- host 是 MySQL 服务端地址
- port 是 MySQL 服务端端口
复制代码
一条 SQL 执行的第一步是由 MySQL 客户端发送到 MySQL 服务端。在这个步骤中直接影响数据速度的是网络,所以,数据库服务端和客户端之间最好要有良好的网络环境。不过,网络不属于本次讨论的重点,这里不做过多的讨论。我们重点讨论一下 MySQL 中的各个模块对于数据库速度的影响。
严格来说,MySQL 连接池属于 MySQL 服务端的模块,因其跟 MySQL 客户端关系密切,我将其拿到 MySQL 客户端中来介绍。
MySQL 客户端成功连接 MySQL 服务端之后,MySQL 服务端的连接池会对客户端的连接进行权限验证,当权限验证通过之后,MySQL 服务端会将客户端的链接记录在服务端的连接池中,之后的各种操作将不再进行权限认证。
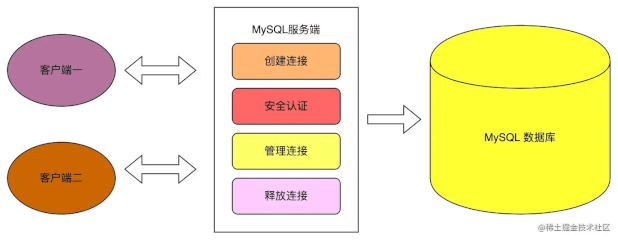
这里你肯定会有疑问:为什么 MySQL 要增加一个连接池模块呢?直接连接 MySQL 服务端不是更简单且高效吗?下面我们就来分析一下。
每一次操作数据库,都需要有一个 MySQL 客户端和服务端之间的链接,创建一个链接就会有一定的时间消耗;当在高并发的情况下,每一次访问数据都会创建一个链接,这样就会持续创建很多重复的数据库链接,很没有必要而且大量的创建链接可能会导致数据库内存溢出等问题。
为了解决这个问题,MySQL 数据库就提供了一个链接池模块,主要用来保存和安全校验连接过来的客户端,当一个客户端连接成功之后,并不会立即释放该连接,而是会将该链接保存在连接池中,这样下一次同一个客户端连接过来就不需要再重复创建连接和安全验证了,可以在很大程度上降低数据库的资源消耗并且减少连接数据的延时。
二、MySQL 服务端
在 MySQL 服务端中,SQL 执行过程中是需要经过很多模块的,其中比较重要的模块是缓存、SQL 解析器、查询优化器以及 SQL 执行器等模块。下面我来详细介绍一下。
1. 查询缓存
在 MySQL 数据库中,如果开启了缓存查询,每一次的查询都会在缓存器中以 KV 形式缓存一份。一条 SQL 在执行过程中,如果命中了缓存,就会跳过 SQL 解析器、查询优化器以及 SQL 执行器,并且立即返回数据,这样做的目的主要是提高数据库的性能。
其实 MySQL 数据库是将缓存以哈希的形式保存在内存中的一个引用表中,并且把本次查询的 SQL、数据库名称以及协议的 hash 值作为 key,这样做的主要目的是下一次同一个查询过来之后可以直接命中查询。
不过缓存并不是永恒不变的,也会失效,我总结了以下几个缓存失效的情况:
- 该条缓存对应的数据、数据表发生变化时,缓存就会自动失效;
- 查询过程中有变化的数据时,是不会创建缓存的,例如 now()。
所以,在使用 MySQL 数据库查询的时候,要尽量避免更改数据和使用有变化的数据。
那么,既然缓存能够提高 MySQL 数据的性能,应该怎么设置开启缓存呢?首先,我们可以使用SHOW VARIABLES LIKE '%query_cache%';来查询缓存的配置项:
-- 查询缓存配置项 mysql> SHOW VARIABLES LIKE '%query_cache%'; +------------------------------+---------+ | Variable_name | Value | +------------------------------+---------+ | have_query_cache | YES | | query_cache_limit | 1048576 | | query_cache_min_res_unit | 4096 | | query_cache_size | 1048576 | | query_cache_type | OFF | | query_cache_wlock_invalidate | OFF | +------------------------------+---------+ 6 rows in set (0.01 sec)
其中,query_cache_type有三个选项,分别是:
- OFF(0):关闭缓存。
- ON(1):开启缓存。
- DEMAND(2):按需开启缓存,加上 SQL_CACHE 关键字才会缓存。
所以,要开启查询缓存可以在 MySQL 数据库的配置文件 my.cnf 中添加query_cache_type = 1即可。如果需要使用 DEMAND 的话,就需要配置成query_cache_type = 2。如果需要缓存的话,就需要增加SQL_CACHE关键字,具体操作如下:
mysql> select SQL_CACHE * from info; +----+--------------+ | id | name | +----+--------------+ | 1 | 小仙女 | | 2 | 小帅哥 | | 3 | 铁锤妹妹 | +----+--------------+ 3 rows in set, 1 warning (0.00 sec)
2. SQL 解析器
当没有命中缓存时,这个时候 MySQL 数据库就得去查询数据了。在查询之前必须解析客户端发送过来的以一系列字符串和空格组成的 SQL,此时就必须用到 MySQL 数据库中的另一个模块:SQL 解析器。
SQL 解析器的主要功能是解析客户端发送过来的 SQL,就比如匹配到 SQL 中是以 select 开头的,那就可以认定其为查询语句;以 insert 开头的 SQL,就可以认定其为插入语句。但如果在判断的过程中,出现了匹配不到的这种情况,就会报出ERROR 1064 (42000): You have an error in your SQL syntax;的错误。具体如下:
mysql> elect * from info; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'elect * from info' at line 1
一般情况下,具体的错误信息都是在最后边的单引号内,具体问题具体对待。
3. 查询优化器
查询优化器,顾名思义就是优化 SQL 的执行效率,也就是说查询优化器的具体功能是为了找到 SQL 的最佳执行方案。
在 MySQL 数据库中的查询优化器优化 SQL 具体有两个方面,分别是逻辑层面和物理层面。
物理层面主要是跟硬件有关,很难通过逻辑去优化,所以这里我们从逻辑层面说明一下。
逻辑层面的优化主要有命中索引优化、顺序优化、排序优化等。例如连表查询,具体如下:
mysql> select * from province inner join city on city.fid = province.id where province.id = 1; +----+-----------+----+--------------+------+ | id | name | id | name | fid | +----+-----------+----+--------------+------+ | 1 | 上海市 | 1 | 徐汇区 | 1 | | 1 | 上海市 | 2 | 浦东新区 | 1 | +----+-----------+----+--------------+------+ 2 rows in set (0.00 sec)
上面的 SQL 连接 province 和 city 两个数据表,在内存中,有如下两种情况。
- 第一种情况:首先查询 province 表中 id 为 1 的数据,然后再查询 city 表中 fid 为 1 的数据。
- 第二种情况:首先查询 city 表中的所有数据,然后再判断 city 表中的 fid 是否等于 1。
这两种情况的结果是一样的,这个时候查询优化器内部通过算法的方式判断哪个方案的效率更高,进而选择哪个方案。
4. SQL 执行器
当分析完 SQL 并且选择合适的方案之后,就开始执行 SQL 了,执行 SQL 就需要使用 MySQL 数据库提供的 SQL 执行器模块。
SQL 执行模块首先会判断当前用户是否对该表有相关的操作权限(如果命中了缓存,将会在返回缓存数据之前进行权限认证)。权限判断通过之后才会调用存储引擎去操作对应的数据表,然后将操作的结果返回。
总结
在这篇文章中,我们按照 SQL 的执行顺序介绍了一条 SQL 从客户端到返回数据期间经过的各个模块。这里我简单将各个要点汇总一下。
- MySQL 客户端主要是用来将 SQL 发送至服务端的一个模块。
- 连接池主要是用来保存成功连接 MySQL 服务端的链接的,这样做的好处是可以防止数据库连接短时间内不断重复创建,减少了资源浪费,提高了数据库的访问速度。
- 数据库缓存模块是将之前访问过的数据保存在内存中,这样做的好处是避免相同的一个任务重复执行的问题,可以提高数据库速度,并且也可以降低数据库资源消耗。
- SQL 解析器主要是用于解析 SQL 的,搞清楚这条 SQL 的具体目的——查询还是更新数据。
- SQL 优化器是通过内部的算法选择执行这条 SQL 效率最高的方案。
- 搞清了 SQL 的具体操作,也选择了最优的执行方案,最后就开始执行 SQL,SQL 执行器的主要作用除了调用存储引擎接口获取数据之外,还有权限认证的作用。
至此,一条 SQL 的生命周期就结束了。
在实际应用中,我建议 SQL 缓存最好设置成按需开启(默认是关闭状态) ,原因是 MySQL 中的某一个表更新会导致与这个表相关的所有缓存全部失效,这样更新数据库时的开销就会额外增加很多。
到此这篇关于MySql执行流程与生命周期详解的文章就介绍到这了,更多相关MySql生命周期内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

SQL语句执行深入讲解(MySQL架构总览->查询执行流程->SQL解析顺序)
前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序来探讨一下其中的知识. 一.MySQL架构总览: 架构最好看图,再配上必要的说明文字. 下图根据参考书籍中一图为原本,再在其上添加上了自己的理解. 从上图中我们可以看到,整个架构分为两层,上层是MySQLD的被称为的'SQL Layer',下层是各种各样对上提供接口的存储引擎,被称为'Storage Engin
-
Mysql表连接的执行流程详解
目录 1. 前言 1.1 mysql连接的原理 1.2 show warnings命令 2. 准备工作 3. inner join内连接on.where的区别 4. left join左连接on.where的区别 4.1 where驱动表过滤条件 4.2 on驱动表过滤条件 4.3 on被驱动表过滤条件 4.4 where被驱动表过滤条件 5. 总结 1. 前言 对于连接操作,驱动表和被驱动表的关联条件我们放在on后面,如果额外增加对驱动表和被驱动表的过滤条件,放到on或者where后面都不会报
-
MySql执行流程与生命周期详解
目录 一.MySQL 客户端 二.MySQL 服务端 1. 查询缓存 2. SQL 解析器 3. 查询优化器 4. SQL 执行器 总结 我们经常会在一起讨论怎样优化 SQL.怎样优化数据库,那么请问你知道执行一条 SQL 的过程中都经过了哪些动作吗?如果不知道的话,又怎么去优化 SQL.优化数据库呢?为了更好地优化 MySQL 数据库,接下来我们就来讨论一下执行一条 SQL 都经过哪些步骤. 为了方便理解,在介绍 SQL 执行流程之前,我们先通过一张图,来详细阐述一下 SQL 执行流程. 由上
-
基于asp.net MVC 应用程序的生命周期(详解)
首先我们知道http是一种无状态的请求,他的生命周期就是从客户端浏览器发出请求开始,到得到响应结束.那么MVC应用程序从发出请求到获得响应,都做了些什么呢? 本文我们会详细讨论MVC应用程序一个请求的生命周期,从一个控件到另一个控件是怎样被处理的.我们还会详细介绍一下整个请求的生命周期中,用到的相关组件.因为在平常的开发过程中,我们可能知道怎样去使用MVC框架来处理相关的请求,大部分的时候我们只是在controller和action方法之间做相关的处理,对于真正内在的运行机制可能不是很了解.其实
-
Java开发学习之Bean的作用域和生命周期详解
目录 一.Bean 的作用域 二.Spring 的执行流程 三.Bean 的生命周期 一.Bean 的作用域 在之前学习Java基础的时候,有接触到作用域这样的概念.一个变量并不一定在任何区域都是有效的,限定这个变量的可用性的代码范围就是该变量的作用域. 但是在这里 Bean 的作用域的概念和以前所认为的作用域有所不同. Bean 的作用域是指 Bean 在 Spring 整个框架中的某种行为模式. 接下来,将会举一个案例来讲讲什么是作用域,什么是行为模式 案例概要: 创建一个共有的 Bean
-
Tomcat生命周期详解
目录 引言 1.LifeCycle接口设计 1.1 生命周期的方法 1.2 相关的状态处理 2.监听器和事件的设计 3.LifecycleBase 3.1 事件处理 3.2 生命周期方法 引言 在上篇文章中我们看到了Tomcat架构中的核心组件,而且各个组件都有各自的作用,各司其职,而且相互之间也有对应的父子关系,那么这些对象的创建,调用,销毁等操作是怎么处理呢? 也就是在Tomcat中的组件的对象生命周期是怎么管理的呢?针对这个问题,在Tomcat中设计了Lifecycle接口来统一管理Tom
-
Spring 中 Bean 的生命周期详解
目录 前言 1.Bean 生命周期 2.代码演示 总结 前言 Java 中的公共类称之为 Bean 或 Java Bean,而 Spring 中的 Bean 指的是将对象的生命周期,交个 Spring IoC 容器来管理的对象.所以 Spring 中的 Bean 对象在使用时,无需通过 new 来创建对象,只需要通过 DI(依赖注入),从 Spring 中取出要使用的对象即可. 那么 Spring 中,Bean 的生命周期又有哪些呢?接下来,我们一起来看. 1.Bean 生命周期 Spring
-
Spring配置使用之Bean生命周期详解
基本概念 Spring 中的 Bean 的生命周期,指的是 Bean 从创建到销毁的过程. 下面来探究下几个有关 Bean 生命周期配置的属性. lazy-init lazy-init 表示延迟加载 Bean,默认在 Spring IoC 容器初始化时会实例化所有在配置文件定义的 Bean,若启用了 lazy-init 则在调用 Bean 时才会去创建 Bean. 定义 Bean: public class Animals { public Animals(){ System.out.print
-
基于Listener监听器生命周期(详解)
一.Listener生命周期 listener是web三大组件之一,是servlet监听器,用来监听请求,监听服务端的操作. listener分为:(都是接口类,必须实现相应方法) 1.生命周期监听器(3个) ServletContextListener requestDestroyed 在容器启动时被调用(在servlet被实例化前执行) requestInitialized 在容器销毁时调用(在servlet被销毁后执行) HttpSessionListener sessionCreated
-
Android入门教程之组件Activity的生命周期详解
目录 返回栈 Activity 状态 1. 运行状态 2. 暂停状态 3. 停止状态 4. 销毁状态 Activity 的生存期 onCreate() onStart() onResume() onPause() onStop() onDestroy() onRestart() 完整生存期 可见生存期 前台生存期 Activity 回收处理 返回栈 Android 中的 Activity 是可以层叠的,我们每启动一个新的 Activity,就会覆盖在原有的 Activity 之上,然后点击 Ba
-
JavaWEB中Servlet的生命周期详解
目录 一.什么是Servlet 生命周期? 二.Servlet 是由谁来维护的? 三.Servlet 对象 是什么时候创建的? 四.测试 Tomcat 什么时候被销毁? 总结 一.什么是Servlet 生命周期? Servlet 对象什么时候被创建? Servlet对象什么时候被销毁? Servlet 对象创建了几个? Servlet 对象的声明周期表示:Servlet 对象从出生到销毁的过程是怎样的 二.Servlet 是由谁来维护的? Servlet 是由 Tomcat 服务器全权负责的,程
-
Java开发学习之Bean的生命周期详解
目录 一.什么是生命周期 二.环境准备 三.生命周期设置 步骤1:添加初始化和销毁方法 步骤2:配置生命周期 步骤3:运行程序 四.close关闭容器 五.注册钩子关闭容器 六.bean生命周期总结 一.什么是生命周期 首先理解下什么是生命周期? 从创建到消亡的完整过程,例如人从出生到死亡的整个过程就是一个生命周期. bean生命周期是什么? bean对象从创建到销毁的整体过程. bean生命周期控制是什么? 在bean创建后到销毁前做一些事情. 二.环境准备 环境搭建: 创建一个Maven项目