详解C语言内核中的自旋锁结构
提到自旋锁那就必须要说链表,在上一篇《驱动开发:内核中的链表与结构体》文章中简单实用链表结构来存储进程信息列表,相信读者应该已经理解了内核链表的基本使用,本篇文章将讲解自旋锁的简单应用,自旋锁是为了解决内核链表读写时存在线程同步问题,解决多线程同步问题必须要用锁,通常使用自旋锁,自旋锁是内核中提供的一种高IRQL锁,用同步以及独占的方式访问某个资源。
首先以简单的链表为案例,链表主要分为单向链表与双向链表,单向链表的链表节点中只有一个链表指针,其指向后一个链表元素,而双向链表节点中有两个链表节点指针,其中Blink指向前一个链表节点Flink指向后一个节点,以双向链表为例。
#include <ntifs.h>
#include <ntstrsafe.h>
/*
// 链表节点指针
typedef struct _LIST_ENTRY
{
struct _LIST_ENTRY *Flink; // 当前节点的后一个节点
struct _LIST_ENTRY *Blink; // 当前节点的前一个结点
}LIST_ENTRY, *PLIST_ENTRY;
*/
typedef struct _MyStruct
{
ULONG x;
ULONG y;
LIST_ENTRY lpListEntry;
}MyStruct,*pMyStruct;
VOID UnDriver(PDRIVER_OBJECT driver)
{
DbgPrint("驱动卸载成功 \n");
}
// By: LyShark
NTSTATUS DriverEntry(IN PDRIVER_OBJECT Driver, PUNICODE_STRING RegistryPath)
{
DbgPrint("By:LyShark \n");
DbgPrint("Email:me@lyshark.com \n");
// 初始化头节点
LIST_ENTRY ListHeader = { 0 };
InitializeListHead(&ListHeader);
// 定义链表元素
MyStruct testA = { 0 };
MyStruct testB = { 0 };
MyStruct testC = { 0 };
testA.x = 100;
testA.y = 200;
testB.x = 1000;
testB.y = 2000;
testC.x = 10000;
testC.y = 20000;
// 分别插入节点到头部和尾部
InsertHeadList(&ListHeader, &testA.lpListEntry);
InsertTailList(&ListHeader, &testB.lpListEntry);
InsertTailList(&ListHeader, &testC.lpListEntry);
// 节点不为空 则 移除一个节点
if (IsListEmpty(&ListHeader) == FALSE)
{
RemoveEntryList(&testA.lpListEntry);
}
// 输出链表数据
PLIST_ENTRY pListEntry = NULL;
pListEntry = ListHeader.Flink;
while (pListEntry != &ListHeader)
{
// 计算出成员距离结构体顶部内存距离
pMyStruct ptr = CONTAINING_RECORD(pListEntry, MyStruct, lpListEntry);
DbgPrint("节点元素X = %d 节点元素Y = %d \n", ptr->x, ptr->y);
// 得到下一个元素地址
pListEntry = pListEntry->Flink;
}
Driver->DriverUnload = UnDriver;
return STATUS_SUCCESS;
}
链表输出效果如下:
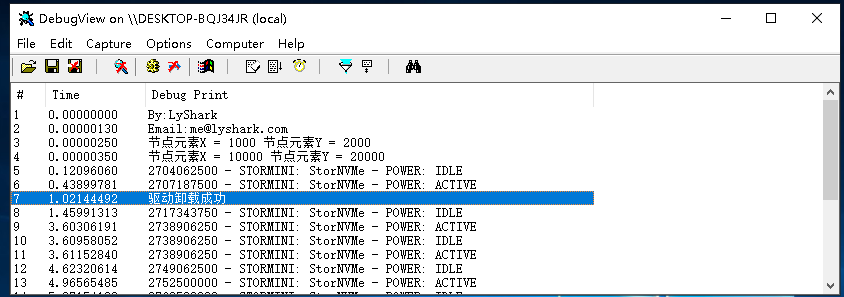
如上所述,内核链表读写时存在线程同步问题,解决多线程同步问题必须要用锁,通常使用自旋锁,自旋锁是内核中提供的一种高IRQL锁,用同步以及独占的方式访问某个资源。
#include <ntifs.h>
#include <ntstrsafe.h>
/*
// 链表节点指针
typedef struct _LIST_ENTRY
{
struct _LIST_ENTRY *Flink; // 当前节点的后一个节点
struct _LIST_ENTRY *Blink; // 当前节点的前一个结点
}LIST_ENTRY, *PLIST_ENTRY;
*/
typedef struct _MyStruct
{
ULONG x;
ULONG y;
LIST_ENTRY lpListEntry;
}MyStruct, *pMyStruct;
// 定义全局链表和全局锁
LIST_ENTRY my_list_header;
KSPIN_LOCK my_list_lock;
// 初始化
void Init()
{
InitializeListHead(&my_list_header);
KeInitializeSpinLock(&my_list_lock);
}
// 函数内使用锁
void function_ins()
{
KIRQL Irql;
// 加锁
KeAcquireSpinLock(&my_list_lock, &Irql);
DbgPrint("锁内部执行 \n");
// 释放锁
KeReleaseSpinLock(&my_list_lock, Irql);
}
VOID UnDriver(PDRIVER_OBJECT driver)
{
DbgPrint("驱动卸载成功 \n");
}
// By: LyShark
NTSTATUS DriverEntry(IN PDRIVER_OBJECT Driver, PUNICODE_STRING RegistryPath)
{
DbgPrint("By:LyShark \n");
DbgPrint("Email:me@lyshark.com \n");
// 初始化链表
Init();
// 分配链表空间
pMyStruct testA = (pMyStruct)ExAllocatePool(NonPagedPoolExecute, sizeof(pMyStruct));
pMyStruct testB = (pMyStruct)ExAllocatePool(NonPagedPoolExecute, sizeof(pMyStruct));
// 赋值
testA->x = 100;
testA->y = 200;
testB->x = 1000;
testB->y = 2000;
// 向全局链表中插入数据
if (NULL != testA && NULL != testB)
{
ExInterlockedInsertHeadList(&my_list_header, (PLIST_ENTRY)&testA->lpListEntry, &my_list_lock);
ExInterlockedInsertTailList(&my_list_header, (PLIST_ENTRY)&testB->lpListEntry, &my_list_lock);
}
function_ins();
// 移除节点A并放入到remove_entry中
PLIST_ENTRY remove_entry = ExInterlockedRemoveHeadList(&testA->lpListEntry, &my_list_lock);
// 输出链表数据
while (remove_entry != &my_list_header)
{
// 计算出成员距离结构体顶部内存距离
pMyStruct ptr = CONTAINING_RECORD(remove_entry, MyStruct, lpListEntry);
DbgPrint("节点元素X = %d 节点元素Y = %d \n", ptr->x, ptr->y);
// 得到下一个元素地址
remove_entry = remove_entry->Flink;
}
Driver->DriverUnload = UnDriver;
return STATUS_SUCCESS;
}
加锁后执行效果如下:

到此这篇关于详解C语言内核中的自旋锁结构的文章就介绍到这了,更多相关C语言内核 自旋锁内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解C语言内核字符串转换方法
在内核编程中字符串有两种格式ANSI_STRING与UNICODE_STRING,这两种格式是微软推出的安全版本的字符串结构体,也是微软推荐使用的格式,通常情况下ANSI_STRING代表的类型是char *也就是ANSI多字节模式的字符串,而UNICODE_STRING则代表的是wchar*也就是UNCODE类型的字符,如下文章将介绍这两种字符格式在内核中是如何转换的. 在内核开发模式下初始化字符串也需要调用专用的初始化函数,如下分别初始化ANSI和UNCODE字符串,我们来看看代码是如何实现
-
详解C语言内核中的链表与结构体
Windows内核中是无法使用vector容器等数据结构的,当我们需要保存一个结构体数组时,就需要使用内核中提供的专用链表结构LIST_ENTRY通过一些列链表操作函数对结构体进行装入弹出等操作,如下代码是本人总结的内核中使用链表存储多个结构体的通用案例. 首先实现一个枚举用户进程功能,将枚举到的进程存储到链表结构体内. #include <ntifs.h> #include <windef.h> extern PVOID PsGetProcessPeb(_In_ PEPROCES
-
详解C语言内核字符串拷贝与比较
在上一篇文章<驱动开发:内核字符串转换方法>中简单介绍了内核是如何使用字符串以及字符串之间的转换方法,本章将继续探索字符串的拷贝与比较,与应用层不同内核字符串拷贝与比较也需要使用内核专用的API函数,字符串的拷贝往往伴随有内核内存分配,我们将首先简单介绍内核如何分配堆空间,然后再以此为契机简介字符串的拷贝与比较. 首先内核中的堆栈分配可以使用ExAllocatePool()这个内核函数实现,此外还可以使用ExAllocatePoolWithTag()函数,两者的区别是,第一个函数可以直接分配内
-
详解C语言内核中的自旋锁结构
提到自旋锁那就必须要说链表,在上一篇<驱动开发:内核中的链表与结构体>文章中简单实用链表结构来存储进程信息列表,相信读者应该已经理解了内核链表的基本使用,本篇文章将讲解自旋锁的简单应用,自旋锁是为了解决内核链表读写时存在线程同步问题,解决多线程同步问题必须要用锁,通常使用自旋锁,自旋锁是内核中提供的一种高IRQL锁,用同步以及独占的方式访问某个资源. 首先以简单的链表为案例,链表主要分为单向链表与双向链表,单向链表的链表节点中只有一个链表指针,其指向后一个链表元素,而双向链表节点中有两个链表节
-
详解C 语言项目中.h文件和.c文件的关系
详解C 语言项目中.h文件和.c文件的关系 在编译器只认识.c(.cpp))文件,而不知道.h是何物的年代,那时的人们写了很多的.c(.cpp)文件,渐渐地,人们发现在很多.c(.cpp)文件中的声明语句就是相同的,但他们却不得不一个字一个字地重复地将这些内容敲入每个.c(.cpp)文件.但更为恐怖的是,当其中一个声明有变更时,就需要检查所有的.c(.cpp)文件. 于是人们将重复的部分提取出来,放在一个新文件里,然后在需要的.c(.cpp)文件中敲入#include XXXX这样的语句.这样即
-
详解C语言编程中预处理器的用法
预处理最大的标志便是大写,虽然这不是标准,但请你在使用的时候大写,为了自己,也为了后人. 预处理器在一般看来,用得最多的还是宏,这里总结一下预处理器的用法. #include <stdio.h> #define MACRO_OF_MINE #ifdef MACRO_OF_MINE #else #endif 上述五个预处理是最常看见的,第一个代表着包含一个头文件,可以理解为没有它很多功能都无法使用,例如C语言并没有把输入输入纳入标准当中,而是使用库函数来提供,所以只有包含了stdio.h这个头文
-
详解C语言数组中是以列优先吗
如果我们按照C语言的方式存储它,也就是行优先存储的话,那么在内存中,它的形状是这样的: 这种存储方式又被称作C contiguous array. C语言数组结构列优先顺序存储的实现 (GCC编译). 从行优先转换为列优先存储方式,与行优先相比,不同之处在于改变了数组维界基址的先后顺序, 从而改变了映像函数常量基址. /** * @brief C语言 数组 列优先 实现 * @author wid * @date 2013-11-02 * * @note 若代码存在 bug 或程序缺陷, 请留言
-
详解C语言编程中的函数指针以及函数回调
函数指针: 就是存储函数地址的指针,就是指向函数的指针,就是指针存储的值是函数地址,我们可以通过指针可以调用函数. 我们先来定义一个简单的函数: //定义这样一个函数 void easyFunc() { printf("I'm a easy Function\n"); } //声明一个函数 void easyFunc(); //调用函数 easyFunc(); //定义这样一个函数 void easyFunc() { printf("I'm a easy Function\n
-
详解Go语言中关于包导入必学的 8 个知识点
1. 单行导入与多行导入 在 Go 语言中,一个包可包含多个 .go 文件(这些文件必须得在同一级文件夹中),只要这些 .go 文件的头部都使用 package 关键字声明了同一个包. 导入包主要可分为两种方式: 单行导入 import "fmt" import "sync" 多行导入 import( "fmt" "sync" ) 如你所见,Go 语言中 导入的包,必须得用双引号包含,在这里吐槽一下. 2. 使用别名 在一些场
-
详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归.但是,流行病学研究中感兴趣的结果通常是事件发生时间.使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型. 时间依赖性ROC定义 令 Mi为用于死亡率预测的基线(时间0)标量标记. 当随时间推移观察到结果时,其预测性能取决于评估时间 t.直观地说,在零时间测量的标记值应该