Python 第三方库 Pandas 数据分析教程
目录
- Pandas导入
- Pandas与numpy的比较
- Pandas的Series类型
- Pandas的Series类型的创建
- Pandas的Series类型的基本操作
- pandas的DataFrame类型
- pandas的DataFrame类型创建
- Pandas的Dataframe类型的基本操作
- pandas索引操作
- pandas重新索引
- pandas删除索引
- pandas数据运算
- 算术运算
- Pandas数据分析
- pandas导入与导出数据
- 导入数据
- 导出数据
- Pandas查看、检查数据
- Pandas数据选取
- pandas数据清理
- Pandas数据处理
- Pandas数据合并
- Pandas数据统计
Pandas导入
Pandas是Python第三方库,提供高性能易用数据类型和分析工具 Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用 两个数据类型:Series, DataFrame
import pandas as pd
Pandas与numpy的比较

Pandas的Series类型
由一组数据及与之相关的数据索引组成

Pandas的Series类型的创建
Series类型可以由如下类型创建:
Python列表,index与列表元素个数一致 标量值,index表达Series类型的尺寸 Python字典,键值对中的“键”是索引,index从字典中进行选择操作 ndarray,索引和数据都可以通过ndarray类型创建 其他函数,range()函数等


Pandas的Series类型的基本操作
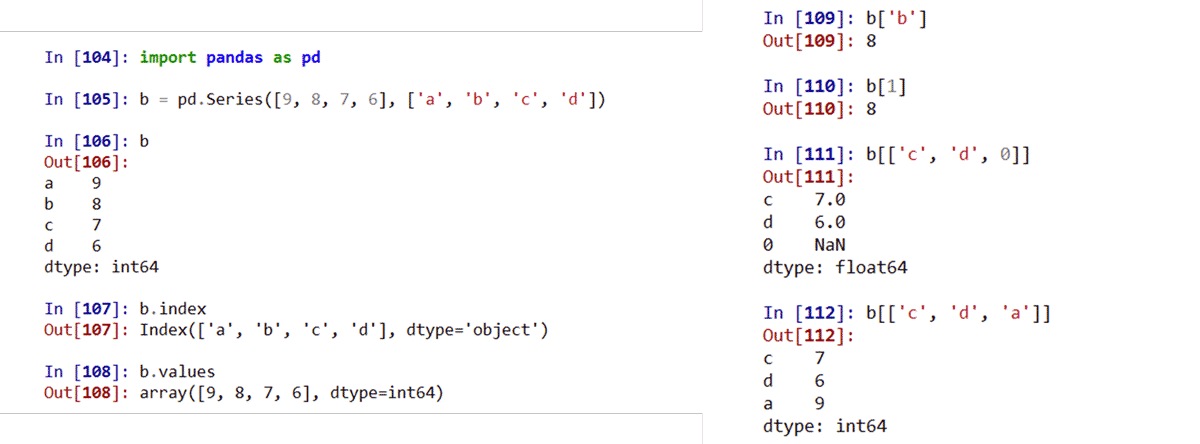
Series类型包含index和values两个部分:
index 获得索引 values 获得数据
由ndarray或字典创建的Series,操作类似ndarray或字典类型
pandas的DataFrame类型
DataFrame类型由共用相同索引的一组列组成
DataFrame是一个表格型的数据类型,每列值类型可以不同
DataFrame既有行索引、也有列索引
DataFrame常用于表达二维数据,但可以表达多维数据
DataFrame是二维带“标签”数组
DataFrame基本操作类似Series,依据行列索引

pandas的DataFrame类型创建
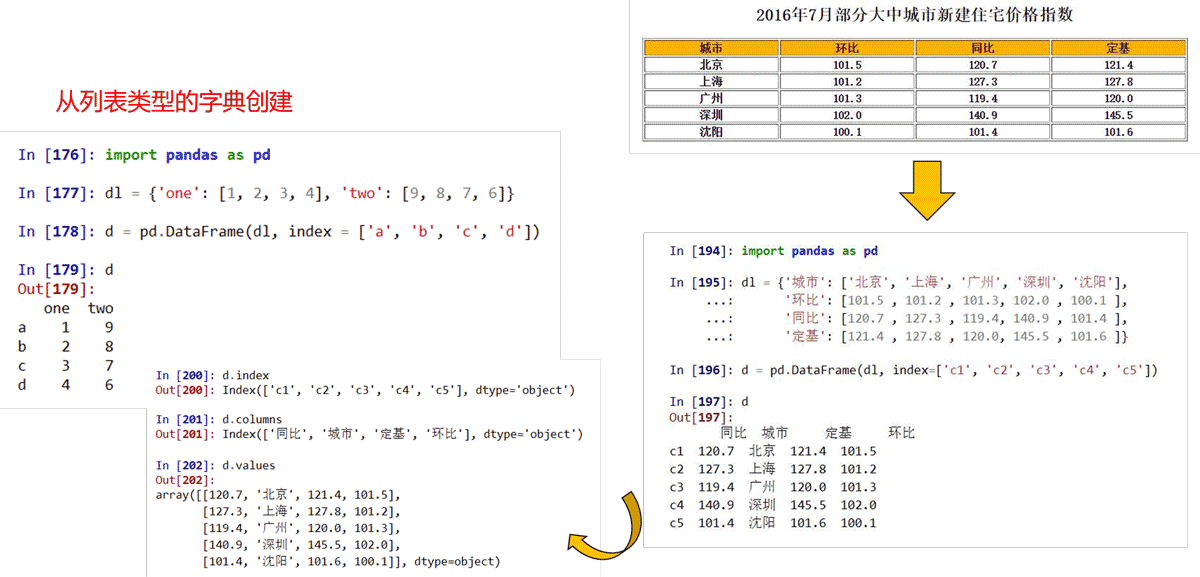
DataFrame类型可以由如下类型创建:
二维ndarray对象 由一维ndarray、列表、字典、元组或Series构成的字典 Series类型 其他的DataFrame类型

Pandas的Dataframe类型的基本操作
pandas索引操作
pandas重新索引
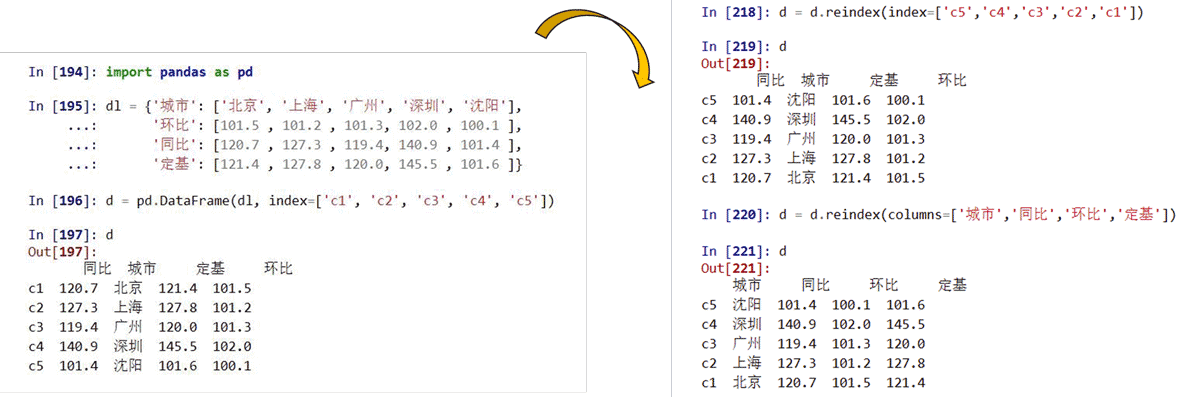
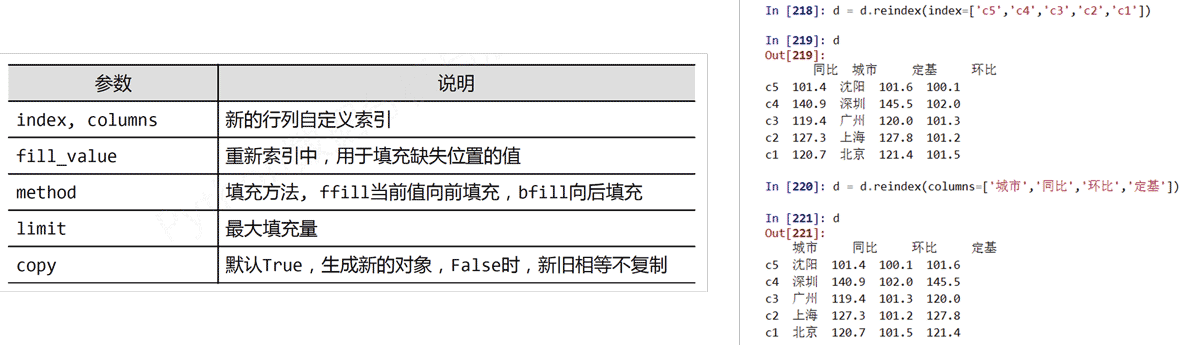
reindex()能够改变或重排Series和DataFrame索引
reindex(index=None, columns=None, …)的参数
pandas删除索引
drop()能够删除Series和DataFrame指定行或列索引

pandas数据运算
算术运算根据行列索引,补齐后运算,运算默认产生浮点数 补齐时缺项填充NaN (空值) 二维和一维、一维和零维间为广播运算 采用+ ‐ * /符号进行的二元运算产生新的对象

算术运算


不同维度间为广播运算,一维Series默认在轴1参与运算 使用运算方法可以令一维Series参与轴0运算
Pandas数据分析
pandas导入与导出数据
导入数据
pd.read_csv(filename):从CSV文件导入数据
pd.read_table(filename):从限定分隔符的文本文件导入数据
pd.read_excel(filename):从Excel文件导入数据
pd.read_sql(query, connection_object):从SQL表/库导入数据
pd.read_json(json_string):从JSON格式的字符串导入数据
pd.read_html(url):解析URL、字符串或者HTML文件,抽取其中的tables表格
pd.read_clipboard():从你的粘贴板获取内容,并传给read_table()
pd.DataFrame(dict):从字典对象导入数据,Key是列名,Value是数据
导出数据
df.to_csv(filename):导出数据到CSV文件
df.to_excel(filename):导出数据到Excel文件
df.to_sql(table_name, connection_object):导出数据到SQL表
df.to_json(filename):以Json格式导出数据到文本文件
Pandas查看、检查数据
df.head(n):查看DataFrame对象的前n行
df.tail(n):查看DataFrame对象的最后n行
df.shape():查看行数和列数
http://df.info():查看索引、数据类型和内存信息
df.describe():查看数值型列的汇总统计
s.value_counts(dropna=False):查看Series对象的唯一值和计数
df.apply(pd.Series.value_counts):查看DataFrame对象中每一列的唯一值和计数
Pandas数据选取
df[col]:根据列名,并以Series的形式返回列
df[[col1, col2]]:以DataFrame形式返回多列
s.iloc[0]:按位置选取数据
s.loc['index_one']:按索引选取数据
df.iloc[0,:]:返回第一行
df.iloc[0,0]:返回第一列的第一个元素
pandas数据清理
df.columns = ['a','b','c']:重命名列名
pd.isnull():检查DataFrame对象中的空值,并返回一个Boolean数组
pd.notnull():检查DataFrame对象中的非空值,并返回一个Boolean数组
df.dropna():删除所有包含空值的行
df.dropna(axis=1):删除所有包含空值的列
df.dropna(axis=1,thresh=n):删除所有小于n个非空值的行
df.fillna(x):用x替换DataFrame对象中所有的空值
s.astype(float):将Series中的数据类型更改为float类型
s.replace(1,'one'):用‘one’代替所有等于1的值
s.replace([1,3],['one','three']):用'one'代替1,用'three'代替3
df.rename(columns=lambda x: x + 1):批量更改列名
df.rename(columns={'old_name': 'new_ name'}):选择性更改列名
df.set_index('column_one'):更改索引列
df.rename(index=lambda x: x + 1):批量重命名索引
Pandas数据处理
df.columns = ['a','b','c']:重命名列名
pd.isnull():检查DataFrame对象中的空值,并返回一个Boolean数组
pd.notnull():检查DataFrame对象中的非空值,并返回一个Boolean数组
df.dropna():删除所有包含空值的行
df.dropna(axis=1):删除所有包含空值的列
df.dropna(axis=1,thresh=n):删除所有小于n个非空值的行
df.fillna(x):用x替换DataFrame对象中所有的空值
s.astype(float):将Series中的数据类型更改为float类型
s.replace(1,'one'):用‘one’代替所有等于1的值
s.replace([1,3],['one','three']):用'one'代替1,用'three'代替3
df.rename(columns=lambda x: x + 1):批量更改列名
df.rename(columns={'old_name': 'new_ name'}):选择性更改列名
df.set_index('column_one'):更改索引列
df.rename(index=lambda x: x + 1):批量重命名索引
df[df[col] > 0.5]:选择col列的值大于0.5的行
df.sort_values(col1):按照列col1排序数据,默认升序排列
df.sort_values(col2, ascending=False):按照列col1降序排列数据
df.sort_values([col1,col2], ascending=[True,False]):先按列col1升序排列,后按col2降序排列数据
df.groupby(col):返回一个按列col进行分组的Groupby对象
df.groupby([col1,col2]):返回一个按多列进行分组的Groupby对象
df.groupby(col1)[col2]:返回按列col1进行分组后,列col2的均值
df.pivot_table(index=col1, values=[col2,col3], aggfunc=max):创建一个按列col1进行分组,并计算col2和col3的最大值的数据透视表
df.groupby(col1).agg(np.mean):返回按列col1分组的所有列的均值
data.apply(np.mean):对DataFrame中的每一列应用函数np.mean
data.apply(np.max,axis=1):对DataFrame中的每一行应用函数np.max
Pandas数据合并
df1.append(df2):将df2中的行添加到df1的尾部
df.concat([df1, df2],axis=1):将df2中的列添加到df1的尾部
df1.join(df2,on=col1,how='inner'):对df1的列和df2的列执行SQL形式的join
Pandas数据统计
df.describe():查看数据值列的汇总统计
df.mean():返回所有列的均值
df.corr():返回列与列之间的相关系数
df.count():返回每一列中的非空值的个数
df.max():返回每一列的最大值
df.min():返回每一列的最小值
df.median():返回每一列的中位数
df.std():返回每一列的标准差
到此这篇关于Python 第三方库 Pandas 数据分析教程的文章就介绍到这了,更多相关Python Pandas 数据分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python数据分析:手把手教你用Pandas生成可视化图表的教程
大家都知道,Matplotlib 是众多 Python 可视化包的鼻祖,也是Python最常用的标准可视化库,其功能非常强大,同时也非常复杂,想要搞明白并非易事.但自从Python进入3.0时代以后,pandas的使用变得更加普及,它的身影经常见于市场分析.爬虫.金融分析以及科学计算中. 作为数据分析工具的集大成者,pandas作者曾说,pandas中的可视化功能比plt更加简便和功能强大.实际上,如果是对图表细节有极高要求,那么建议大家使用matplotlib通过底层图表模块进行编码.当然,我
-
Python数据分析模块pandas用法详解
本文实例讲述了Python数据分析模块pandas用法.分享给大家供大家参考,具体如下: 一 介绍 pandas(Python Data Analysis Library)是基于numpy的数据分析模块,提供了大量标准数据模型和高效操作大型数据集所需要的工具,可以说pandas是使得Python能够成为高效且强大的数据分析环境的重要因素之一. pandas主要提供了3种数据结构: 1)Series,带标签的一维数组. 2)DataFrame,带标签且大小可变的二维表格结构. 3)Panel,带标
-

Python数据分析之pandas比较操作
一.比较运算符和比较方法 比较运算符用于判断是否相等和比较大小,Python中的比较运算符有==.!=.<.>.<=.>=六个,Pandas中也一样. 在Pandas中,DataFrame和Series还支持6个比较方法,详见下表. 方法 英文全称 用途 eq equal to 等于 ne not equal to 不等于 lt less than 小于 gt greater than 大于 le less than or equal to 小于等于 ge greater than
-
基于Python数据分析之pandas统计分析
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据 import numpy as np import pandas as pd np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 1
-
Python数据分析pandas模块用法实例详解
本文实例讲述了Python数据分析pandas模块用法.分享给大家供大家参考,具体如下: pandas pandas10分钟入门,可以查看官网:10 minutes to pandas 也可以查看更复杂的cookbook pandas是非常强大的数据分析包,pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包.就好比 Numpy的核心是 ndarray,pandas 围绕着 Series 和 DataFrame 两个核心数据结构展开 .Series和DataFrame 分
-
Python数据分析Pandas Dataframe排序操作
目录 1.索引的排序 2.值的排序 前言: 数据的排序是比较常用的操作,DataFrame 的排序分为两种,一种是对索引进行排序,另一种是对值进行排序,接下来就分别介绍一下. 1.索引的排序 DataFrame 提供了sort_index()方法来进行索引的排序,通过axis参数指定对行索引排序还是对列索引排序,默认为0,表示对行索引排序,设置为1表示对列索引进行排序:ascending参数指定升序还是降序,默认为True表示升序,设置为False表示降序, 具体使用方法如下: 对行索引进行降序
-
Python Pandas数据分析之iloc和loc的用法详解
Pandas 是一套用于 Python 的快速.高效的数据分析工具.它可以用于数据挖掘和数据分析,同时也提供数据清洗功能.本篇目录如下: 一.iloc 1.定义 iloc索引器用于按位置进行基于整数位置的索引或者选择. 2.语法 df.iloc [row selection, column selection] 3.代码示例 (1)导入数据 (2)选择单行或单列 (3)选择多行或多列 (4)注意 iloc选择一行时返回Series,选择多行返回DataFrame,通过传递列表可转为DataFra
-
Python数据分析之如何利用pandas查询数据示例代码
前言 在数据分析领域,最热门的莫过于Python和R语言,本文将详细给大家介绍关于Python利用pandas查询数据的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 示例代码 这里的查询数据相当于R语言里的subset功能,可以通过布尔索引有针对的选取原数据的子集.指定行.指定列等.我们先导入一个student数据集: student = pd.io.parsers.read_csv('C:\\Users\\admin\\Desktop\\student.csv')
-
Python数据分析库pandas基本操作方法
pandas是什么? 是它吗? ....很显然pandas没有这个家伙那么可爱.... 我们来看看pandas的官网是怎么来定义自己的: pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language. 很显然,pandas是python的一个非常强大的数据分析库! 让我们来学习一下它吧! 1.pandas序列 import nump
-
Python数据分析库pandas高级接口dt的使用详解
Series对象和DataFrame的列数据提供了cat.dt.str三种属性接口(accessors),分别对应分类数据.日期时间数据和字符串数据,通过这几个接口可以快速实现特定的功能,非常快捷. 今天翻阅pandas官方文档总结了以下几个常用的api. 1.dt.date 和 dt.normalize(),他们都返回一个日期的 日期部分,即只包含年月日.但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的. 这里先简单