Java CopyOnWriteArrayList源码超详细分析
目录
- 一、概述
- 二、类图
- 三、核心方法
- 1.add()
- 2.set()
- 3.remove()
- 4.get()
- 5.size()
- 四、总结
一、概述
CopyOnWriteArrayList是基于写时复制技术实现的,适用于读多写少场景下的线程安全的并发容器。读操作永远不会加锁,读读、读写都不会冲突,只有写写需要等待。写操作时,为了不影响其它线程的读取,它会进行一次自我复制,待数据写入完成后再替换array数组。array数组是被volatile修饰的,它被修改后可以被其他线程立刻发现。
public class copyOnwriteArrayList<E>
implements List<E>,RandomAccess,Cloneable,java.io.Serializable {
//加锁: ReentrantLock
final transient ReentrantLock lock = new ReentrantLock( ) ;
// volatile:保证可见性
private transient volatile object[ ] array;
//获取数组
final object[] getArray() ireturn array ;
}
//存入数组
final void setArray(object[ ] a) iarray = a;
}
//无参构造方法:初始化数组,容量为日public CopyOnwriteArrayList( ) i
setArray( new object[e]);
}
//有参构造方法:传入集合
public CopyOnwriteArrayList(collection< ? extends E> c) {
object[] elements;
//判断传入的集合是否是CopyOnwriteArrayList类型if (c.getclass() == copyonwriteArrayList.class)
//获取数组
elements = ((copyOnwriteArrayList<?>)c).getArray();else i
//将集合转为数组
elements = c.toArray();
// c.toArray might (incorrectly) not return object[] (see 6260652)1/判断数组是否是object[]
if (elements.getclass() i= object[].class)
//复制数组
elements = Arrays.copyof(elements,elements.length,object[ ].c1
}
setArray(elements) ;
}
setArray(elements ) ;
}
二、类图
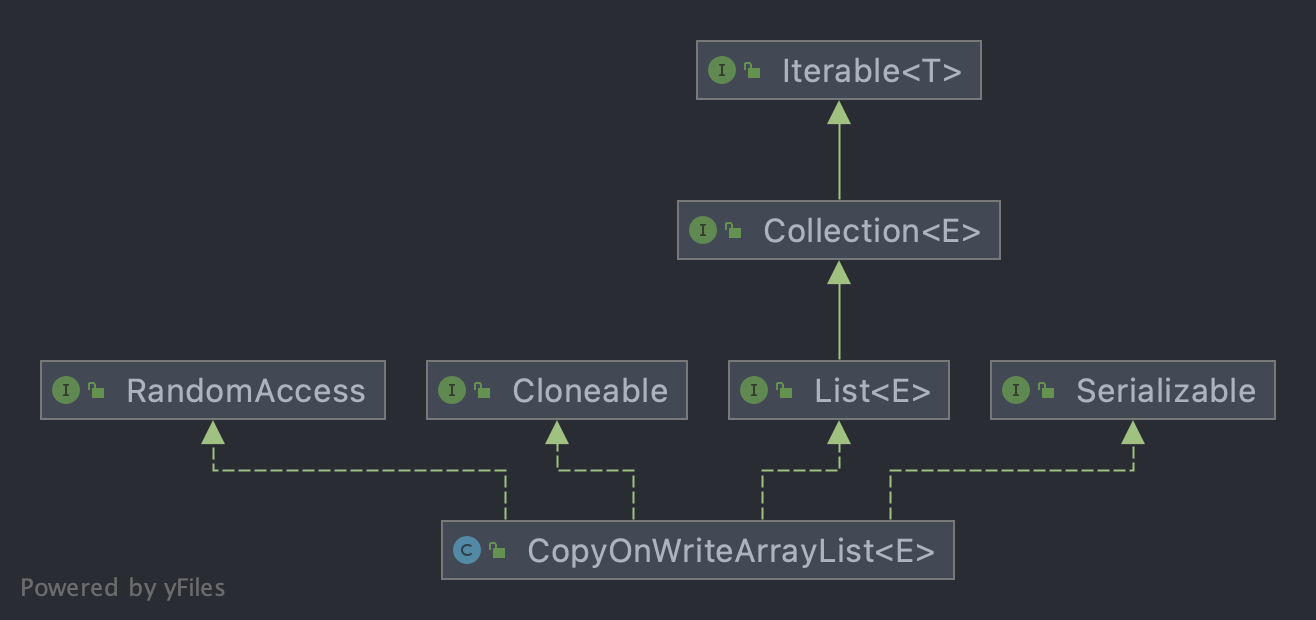
- 实现了RandomAccess接口,代表它支持快速随机访问,因为它底层数据结构是数组,支持通过下标快速访问;
- 实现了Cloneable接口,代表它支持克隆,使用的是浅拷贝模式;
- 实现了List接口,代表它是一个有序的列表容器,支持迭代遍历等操作。
三、核心方法
1.add()
向容器中添加元素时,需要竞争锁,同一时刻最多只有一个线程可以操作。因为是写时复制,写入数据时不应该影响其他线程的读取,因此不会直接在array数组上操作,而是拷贝一个新的数组,元素设置完成后再覆盖旧数组。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 拷贝一个长度+1的数组,将元素放到末尾
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 填充要追加的元素e
newElements[len] = e;
// 覆盖旧数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
2.set()
set方法用来给指定下标设置值,同时会返回旧值。它也是一个写入操作,因此也需要竞争到锁才能执行。为了不影响其它线程读取,它会拷贝一个同样长度的新数组,然后做数据拷贝,在新数组上完成新值的设置,最终再写回array。
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
// 先获取旧元素
E oldValue = get(elements, index);
if (oldValue != element) {
int len = elements.length;
// 拷贝一个一样的数组,替换下标元素,并写入array
Object[] newElements = Arrays.copyOf(elements, len);
newElements[index] = element;
setArray(newElements);
} else {
// 即使元素没有变化,也要写入array,确保volatile的写语义
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}
3.remove()
remove也是写操作,只有竞争到锁的线程才能执行。它先是取出对应下标的旧元素,然后新建了一个原数组长度减1的新数组,完成数据拷贝后,再写回array,整个过程依然不影响其它线程读。
public E remove(int index) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 要移除的旧元素
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
// 删除的是最后一个元素,直接拷贝一个长度-1的数组写回array即可
setArray(Arrays.copyOf(elements, len - 1));
else {
// 删除的是中间元素,拷贝一个长度-1的数组
Object[] newElements = new Object[len - 1];
// 拷贝前半段元素
System.arraycopy(elements, 0, newElements, 0, index);
// 拷贝后半段元素
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
// 写回array
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();
}
}
4.get()
通过下标获取元素,直接从array数组中取。因为是写时复制的,可能在访问时已经有新的元素加入,或者有元素被删除,这是会存在延迟的,不是实时的,这是它的一个缺点。
public E get(int index) {
// getArray()获取的就是array
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}
5.size()
获取元素的数量直接取数组的长度即可。因为CopyOnWriteArrayList的数组是不可变数组,它始终是一个被填充满的数组对象,没有扩容的操作,因此也没有必要像ArrayList一样,额外使用一个int size来记录数量。
public int size() {
return getArray().length;
}
四、总结
CopyOnWriteArrayList 具有以下特性:
- 在保证并发读取的前提下,确保了写入时的线程安全;
- 由于每次写入操作时,进行了Copy复制原数组,所以无需扩容;
- 适合读多写少的应用场景。由于 add() 、 set() 、 remove() 等修改操作需要复制整 个数组,所以会有内存开销大的问题;
- CopyOnWriteArrayList 由于只在写入时加锁,所以只能保证数据的最终一致性,不能 保证数据的实时一致性。
到此这篇关于Java CopyOnWriteArrayList源码超详细分析的文章就介绍到这了,更多相关Java CopyOnWriteArrayList内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java源码解析CopyOnWriteArrayList的讲解
本文基于jdk1.8进行分析. ArrayList和HashMap是我们经常使用的集合,它们不是线程安全的.我们一般都知道HashMap的线程安全版本为ConcurrentHashMap,那么ArrayList有没有类似的线程安全的版本呢?还真有,它就是CopyOnWriteArrayList. CopyOnWrite这个短语,还有一个专门的称谓COW. COW不仅仅是java实现集合框架时专用的机制,它在计算机中被广泛使用. 首先看一下什么是CopyOnWriteArrayList,它的类前面
-
Java并发包之CopyOnWriteArrayList类的深入讲解
前言 大家在学习Java的过程中,或者工作中,始终都绕不开集合.在单线程环境下,ArrayList就可以满足要求.多线程时,我们可以使用CopyOnWriteArrayList来保证数据安全.下面我们一起来看看CopyOnWriteArrayList类中的一些值得学习的方法. CopyOnWriteArrayList是一个线程安全的ArrayList,对其进行的修改操作都是在底层的一个复制的数组(快照)上进行的,也就是使用了写时复制策略实现的. 说明:代码部分,均基于JDK1.8 一.添加元素
-

java并发容器CopyOnWriteArrayList实现原理及源码分析
CopyOnWriteArrayList是Java并发包中提供的一个并发容器,它是个线程安全且读操作无锁的ArrayList,写操作则通过创建底层数组的新副本来实现,是一种读写分离的并发策略,我们也可以称这种容器为"写时复制器",Java并发包中类似的容器还有CopyOnWriteSet.本文会对CopyOnWriteArrayList的实现原理及源码进行分析. 实现原理 我们都知道,集合框架中的ArrayList是非线程安全的,Vector虽是线程安全的,但由于简单粗暴的锁同步机制,
-
java中CopyOnWriteArrayList源码解析
目录 简介 继承体系 源码解析 属性 构造方法 add(Ee)方法 add(intindex,Eelement)方法 addIfAbsent(Ee)方法 get(intindex) remove(intindex)方法 size()方法 提问 总结 简介 CopyOnWriteArrayList是ArrayList的线程安全版本,内部也是通过数组实现,每次对数组的修改都完全拷贝一份新的数组来修改,修改完了再替换掉老数组,这样保证了只阻塞写操作,不阻塞读操作,实现读写分离. 继承体系 public
-
Java concurrency集合之 CopyOnWriteArrayList_动力节点Java学院整理
CopyOnWriteArrayList介绍 它相当于线程安全的ArrayList.和ArrayList一样,它是个可变数组:但是和ArrayList不同的时,它具有以下特性: 1. 它最适合于具有以下特征的应用程序:List 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突. 2. 它是线程安全的. 3. 因为通常需要复制整个基础数组,所以可变操作(add().set() 和 remove() 等等)的开销很大. 4. 迭代器支持hasNext(), next()等不可
-
Java CopyOnWriteArrayList源码超详细分析
目录 一.概述 二.类图 三.核心方法 1.add() 2.set() 3.remove() 4.get() 5.size() 四.总结 一.概述 CopyOnWriteArrayList是基于写时复制技术实现的,适用于读多写少场景下的线程安全的并发容器.读操作永远不会加锁,读读.读写都不会冲突,只有写写需要等待.写操作时,为了不影响其它线程的读取,它会进行一次自我复制,待数据写入完成后再替换array数组.array数组是被volatile修饰的,它被修改后可以被其他线程立刻发现. publi
-
Android用于加载xml的LayoutInflater源码超详细分析
1.在view的加载和绘制流程中:文章链接 我们知道,定义在layout.xml布局中的view是通过LayoutInflate加载并解析成Java中对应的View对象的.那么具体的解析过程是哪样的. 先看onCreate方法,如果我们的Activity是继承自AppCompactActivity.android是通过getDelegate返回的对象setContentView,这个mDelegate 是AppCompatDelegateImpl的实例. @Override protected
-
Java 栈与队列超详细分析讲解
目录 一.栈(Stack) 1.什么是栈? 2.栈的常见方法 3.自己实现一个栈(底层用一个数组实现) 二.队列(Queue) 1.什么是队列? 2.队列的常见方法 3.队列的实现(单链表实现) 4.循环队列 一.栈(Stack) 1.什么是栈? 栈其实就是一种数据结构 - 先进后出(先入栈的数据后出来,最先入栈的数据会被压入栈底) 什么是java虚拟机栈? java虚拟机栈只是JVM当中的一块内存,该内存一般用来存放 例如:局部变量当调用函数时,我们会为函数开辟一块内存,叫做 栈帧,在 jav
-
React超详细分析useState与useReducer源码
目录 热身准备 为什么会有hooks hooks执行时机 两套hooks hooks存储 初始化 mount useState mountWorkInProgressHook 更新update updateState updateReducer updateWorkInProgressHook 总结 热身准备 在正式讲useState,我们先热热身,了解下必备知识. 为什么会有hooks 大家都知道hooks是在函数组件的产物.之前class组件为什么没有出现hooks这种东西呢? 答案很简单,
-
Redis对象与redisObject超详细分析源码层
目录 一.对象 二.对象的类型及编码 redisObject 结构体 三.不同对象编码规则 四.redisObject结构各字段使用范例 4.1 类型检查(type字段) 4.2 多态命令的实现(encoding) 4.3 内存回收和共享对象(refcount) 4.4 对象的空转时长(lru) 五.对象在源码中的使用 5.1 字符串对象 5.1.1字符串对象创建 5.1.2 字符串对象编码 5.1.3 字符串对象解码 5.1.4 redis对象引用计数及自动清理 六.总结 以下内容是基于Red
-
Java超详细分析泛型与通配符
目录 1.泛型 1.1泛型的用法 1.1.1泛型的概念 1.1.2泛型类 1.1.3类型推导 1.2裸类型 1.3擦除机制 1.3.1关于泛型数组 1.3.2泛型的编译与擦除 1.4泛型的上界 1.4.1泛型的上界 1.4.2特殊的泛型上界 1.4.3泛型方法 1.4.4类型推导 2.通配符 2.1通配符的概念 2.2通配符的上界 2.3通配符的下界 题外话: 泛型与通配符是Java语法中比较难懂的两个语法,学习泛型和通配符的主要目的是能够看懂源码,实际使用的不多. 1.泛型 1.1泛型的用法
-
非常适合新手学生的Java线程池超详细分析
目录 线程池的好处 创建线程池的五种方式 缓存线程池CachedThreadPool 固定容量线程池FixedThreadPool 单个线程池SingleThreadExecutor 定时任务线程池ScheduledThreadPool ThreadPoolExecutor创建线程池(十分推荐) ThreadPoolExecutor的七个参数详解 workQueue handler 如何触发拒绝策略和线程池扩容? 线程池的好处 可以实现线程的复用,避免重新创建线程和销毁线程.创建线程和销毁线程对
-
Java超详细分析@Autowired原理
目录 @Autowired使用 @Autowired源码分析 1.查找所有@Autowired 2. 注入 2.1 字段注入(AutowiredFieldElement) 2.2 方法注入(AutowiredMethodElement) @Autowired使用 构造函数注入 public Class Outer { private Inner inner; @Autowired public Outer(Inner inner) { this.inner = inner; } } 属性注入 p
-
java集合类源码分析之Set详解
Set集合与List一样,都是继承自Collection接口,常用的实现类有HashSet和TreeSet.值得注意的是,HashSet是通过HashMap来实现的而TreeSet是通过TreeMap来实现的,所以HashSet和TreeSet都没有自己的数据结构,具体可以归纳如下: •Set集合中的元素不能重复,即元素唯一 •HashSet按元素的哈希值存储,所以是无序的,并且最多允许一个null对象 •TreeSet按元素的大小存储,所以是有序的,并且不允许null对象 •Set集合没有ge