Sql Server查询性能优化之不可小觑的书签查找介绍
小小程序猿SQL Server认知的成长
1.没毕业或工作没多久,只知道有数据库、SQL这么个东东,浑然分不清SQL和Sql Server Oracle、MySql的关系,通常认为SQL就是SQL Server
2.工作好几年了,也写过不少SQL,却浑然不知道索引为何物,只知道数据库有索引这么个东西,分不清聚集索引和非聚集索引,只知道查询慢了建个索引查询就快了,到头来索引也建了不少,查询也确实快了,偶然问之:汝建之索引为何类型?答曰:。。。
3.终于受到刺激开始奋发图强,买书,gg查资料终于知道原来索引分为聚集索引和非聚集索引,顿时泪流满面,呜呼哀哉,吾终知索引为何物也。
4.再进一步学习之亦知聚集索引为物理索引、非聚集索引为逻辑索引,聚集索引为数据的存储顺序,非聚集索引是逻辑索引既对聚集索引的索引
5.再往后学会了查看执行计划,通过查询计划终于对查询过程有了大概了解,也知道了聚集索引扫描和表扫描没有用到索引,看到聚集索引、索引查找高兴的眉飞色舞,看到RID、键查找暗自窃喜,瞧,键查找肯定就是关键字查找了,用着索引呢,效率肯定高,于是每次写完sql都要观看下其执行计划,表扫描的干货统统不要,俺只要索引查找、键查找。
6.自信满满的过着悠哉的小日子,突然有一天迷茫了,为嘛俺明明在这个字段上建立了索引,它她妹的老给我显示聚集索引扫描的,难道查询优化器发烧了,实际执行下,发现实际的执行计划还是表扫描,这下彻底迷惑了,兴许是查询优化器显示的有问题吧。
7.继续深入学习终发现,数据库这潭水太深了,了解的太片面了,想想从猿到人的进化过程吧,恩恩,现在就是一个灵智初开的程序猿,向着伟大的程序员奋勇前进
恩恩,跑题了,进入我们的主题:数据库的书签查找
认识书签查找
书签查找这个词可能对于很多开发人员比较陌生,很多人都遇到过,但是却没引起足够的重视以至于一直都忽略它的存在了
定义:当查询优化器使用非聚集索引进行查找时,如果所选择的列或查询条件中的列只部分包含在使用的非聚集索引和聚集索引中时,就需要一个查找(lookup)来检索其他字段来满足请求。对一个有聚簇索引的表来说是一个键查找(key lookup),对一个堆表来说是一个RID查找(RID lookup),这种查找即是——书签查找(bookmark lookup)。简单的说就是当你使用的sql查询条件和select返回的列没有完全包含在索引列中时就会发生书签查找。
书签查找的重要性
1.书签查找发生条件:只有在使用非聚集索引进行数据查找时才会产生书签查找,聚集索引查找、聚集索引扫描和表扫描不会发生书签查找。
2.书签查找发生频率:书签查找发生频率非常高,甚至可以说大部分查询都会发生书签查找,我们知道一个表只能建立一个聚集索引,所以我们的查询更多的会使用非聚集索引,非聚集索引不可能覆盖所有的查询列,所以会经常性产生书签查找。
3.书签查找的影响:导致索引失效的主要原因之一。书签查找根据索引的行定位器从表中读取数据,除了索引页面的逻辑读取外,还需要数据页面的逻辑读取,如果查询的结果返回数据量较大会导致大量的逻辑读或者索引失效,这也是为什么我们查看查询计划时有时明明在查询列上建立了索引,查询优化器却依然使用表扫描的原因。
4.如何消除书签查找:
1.使用聚集索引查找,聚集索引的叶子节点就是数据行本身,因此不存在书签查找
2.聚集索引扫描、表扫描,说白了就是啥索引都不建直接全表扫描,肯定不会发生书签查找,不过效率吗。。。
3.使用非聚集索引的键列包含所有查询或返回的列,这个不靠谱,非聚集索引最大键列数为16,最大索引键大小为900字节,就算你有勇气在16列上全部建立索引,那如果表的列数超过16列了你咋办,还有索引列长度之和不能超过900字节,所以不可能让非聚集索引包含所有列,而且索引涉及到得列越多维护索引的开销也就越大。
4.使用include,嗯,这是个好东东,索引做到只能包含16列且不能超过900字节,include不受此限制,最多可以包含1023列怎么也够你用了,而且对长度也没有限制你可以随心所欲的包含nvarchar(max)这也的列,当然了text之流就不要考虑了
5.其它,其它还有神马呢,这个我也不知道了,估计应该、可能、大概木有了吧,若有知道的兄弟可以告诉我声哈
可能上面说的有点抽象,我们开看看具体的例子
一般我们的数据库都会建上聚集索引(一般大家喜欢建表时有用没有肯定先来个自增ID列当主键,这个主键SQL Server默认就给你创建成聚集索引了),故我们这里都假设表上已经建立了聚集索引,不考虑堆表(就是没有聚集索引的表)
1.首先创建表Users、插入一些示例数据并建立聚集索引PK_UserID 非聚集索引IX_UserName
代码如下:
--懒得的肥兔 --创建表Users
Create table Users
(
UserID int identity,
UserName nvarchar(50),
Age int,
Gender bit,
CreateTime datetime
)
--在UserID列创建聚集索引PK_UserID
create unique clustered index PK_UserID on Users(UserID)
--在UserName创建非聚集索引IX_UserName
create index IX_UserName on Users(UserName)
--插入示例数据
insert into Users(UserName,Age,Gender,CreateTime)
select N'Bob',20,1,'2012-5-1'
union all
select N'Jack',23,0,'2012-5-2'
union all
select N'Robert',28,1,'2012-5-3'
union all
select N'Janet',40,0,'2012-5-9'
union all
select N'Michael',22,1,'2012-5-2'
union all
select N'Laura',16,1,'2012-5-1'
union all
select N'Anne',36,1,'2012-5-7'
2.执行以下查询并查看查询计划,可以看到第一个SQL执行聚集索引扫描,第二个SQL执行聚集索引查找都没有使用到书签查找
代码如下:
select * from Users
select * from Users where UserID=4

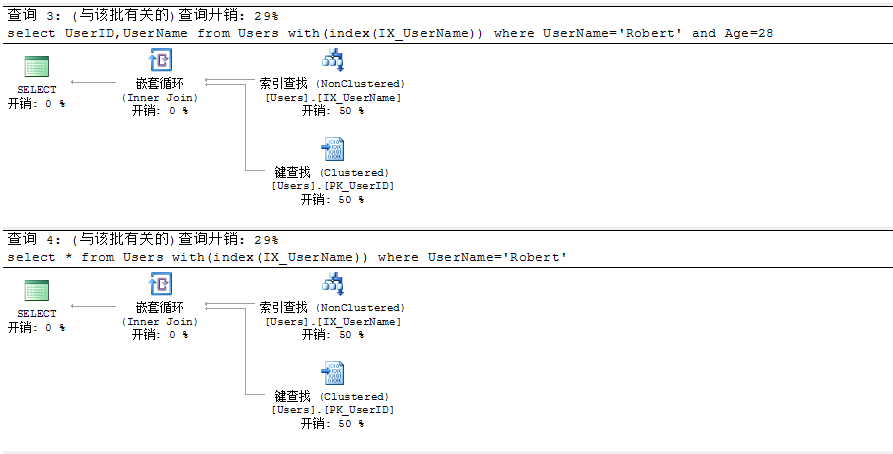
3.比较以下几个查询SQL,观察其查询计划,思考下为什么会发生书签查找
代码如下:
--查询1:使用索引IX_UserName,选择列UserID,UserName,查询条件列为UserName
select UserID,UserName from Users with(index(IX_UserName)) where UserName='Robert'
--查询2:使用索引IX_UserName,选择列UserID,UserName,Age,查询条件列为UserName
select UserID,UserName,Age from Users with(index(IX_UserName)) where UserName='Robert'
--查询3:使用索引IX_UserName,选择列UserID,UserName,查询条件列为UserName,Age
select UserID,UserName from Users with(index(IX_UserName)) where UserName='Robert' and Age=28
--查询4:使用索引IX_UserName,选择列所有列,查询条件列为UserName
select * from Users with(index(IX_UserName)) where UserName='Robert'
分析:
查询1:选择的列UserID是聚集索引PK_UserID的键列,UserName为索引IX_UserName的键列,查询条件列为UserName,由于索引IX_UserName包含了查询用到得所有列,所以仅需要扫描索引即可返回查询结果,不需要再额外的去数据页获取数据,故不会发生书签查找
查询2:选择列Age不包含在聚集索引PK_UserID和IX_UserName中,故需要进行额外的书签查找
查询3:查询条件Age列不包含在聚集索引PK_UserID和IX_UserName中,故需要进行额外的书签查找
查询4:包含了所有的列,Age、Gender、CreateTime列均不在聚集索引PK_UserID和IX_UserName中,所以需要书签查找以定位数据
这里解释下:查询中用到的列无论是一列还是多列不在索引覆盖范围查询开销基本上一样,每条记录均只需要一次书签查找开销,不会说因为查询3只有一个Age列,查询4有Age、Gender、CreateTime 3列不在索引覆盖范围而导致额外的开销
分析:
查询1:选择的列UserID是聚集索引PK_UserID的键列,UserName为索引IX_UserName的键列,查询条件列为UserName,由于索引IX_UserName包含了查询用到得所有列,所以仅需要扫描索引即可返回查询结果,不需要再额外的去数据页获取数据,故不会发生书签查找
查询2:选择列Age不包含在聚集索引PK_UserID和IX_UserName中,故需要进行额外的书签查找
查询3:查询条件Age列不包含在聚集索引PK_UserID和IX_UserName中,故需要进行额外的书签查找
查询4:包含了所有的列,Age、Gender、CreateTime列均不在聚集索引PK_UserID和IX_UserName中,所以需要书签查找以定位数据
这里解释下:查询中用到的列无论是一列还是多列不在索引覆盖范围查询开销基本上一样,每条记录均只需要一次书签查找开销,不会说因为查询3只有一个Age列,查询4有Age、Gender、CreateTime 3列不在索引覆盖范围而导致额外的开销

书签查找是怎么发生的
和许多人一样看到大神们画的二叉树索引结构图就脑袋大,看得云里雾里,所以这里我们以表Users为例来说聚集索引(PK_UserID)和非聚集索引(IX_UserName)的结构可以简单的表示为下图
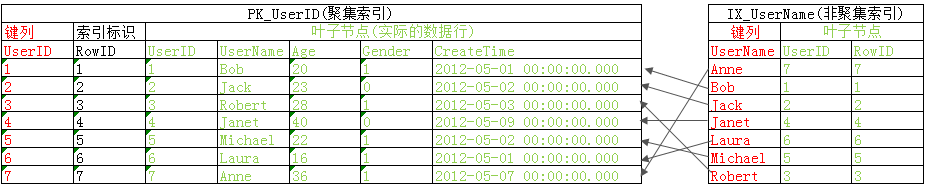
首先我们来看聚集索引PK_UserID,对于聚集索引来说数据行就是其叶子节点,故当执行聚集索引查找时找到了具体的键值后就可以直接去叶子节点获取所有需要的数据不需要进行额外的逻辑读,比如select * from Users where UserID=2,根据值2在索引PK_UserID中找到UserID为2的值后去叶子节点就可以拿到所需数据,然后返回查询结果
然后看非聚集索引IX_UserName,上面我们说过非聚集索引覆盖的列为非聚集索引的键列+包含的列+聚集索引的键列,对于IX_UserName来说就是如图中所示键列UserName保存在索引的二叉树节点中,聚集索引的列包含在其叶子节点中,这也就形成了对列(UserName,UserID)的覆盖,对于查询1(select UserID,UserName from Users with(index(IX_UserName)) where UserName='Robert')来说查询只用到了UserName,UserID列,这样只需要扫描索引IX_UserName即可拿到所有数据然后进行结果返回,而对于查询2、查询3来说由于需要用到Age列,而索引IX_UserName中并没有包含Age列,这时就需要个书签查找(bookmark lookup)根据叶节点中的RowID去定位到具体的数据行获取Age列值,对于示例查询来说先根据索引IX_UserName定位Robert所在行,然后根据RowID=3去数据表里获取Age值,然后完成查询,对于查询4来说需要更多的列(Age,Gender,CreateTime),同样定位到Robert所在行RowID=3,去数据表一次性拿到Age,Gender,CreateTime数据然后返回,这样就形成了书签查找(查询计划中显示为键查找或RID查找)
书签查找的对查询性能的影响
--这是我们现在使用的索引create index IX_UserName on Users(UserName)
--set statistics io onselect * from Users where UserName like 'ja%'select * from Users with(index(IX_UserName)) where UserName like 'ja%'
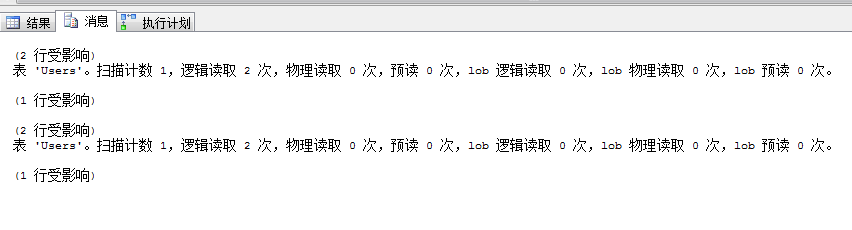
两个查询都返回2条数据,聚集索引扫描仅仅2次逻辑读,使用索引IX_UserName却达到了6次的逻辑读

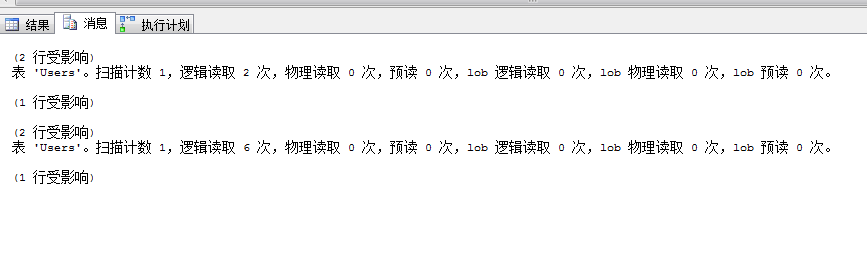
我们示例的数据量比较小,所以感受不明显,不过我们却也看到了我们在UserName列上市建立了索引 IX_UserName,默认情况下查询优化器并没有使用我们的索引,而是选择了表扫描,仅仅需要2次逻辑读就拿到了我们需要的数据,在我们使用索引提示强制查询优化器使用索引IX_UserName后,同样也是返回2条数据,逻辑读缺达到了惊人的6次,看查询计划使用IX_UserName后发生了书签查找,而这个开销主要是有书签查找造成的,而且随着我们返回数据量的增加,由书签查找导致的逻辑读将会成直线上升,造成的结果就是查询开销比进行全表扫描还要大的多,最终导致索引失效
使用覆盖索引避免书签查找
覆盖索引是指非聚集索引上的列(键列+包含列) + 聚集索引的键列包含了查询中用到的所有列,对于索引IX_UserName来说索引覆盖列就是(UserName,UserID)。若查询中只用到了索引所覆盖的列,那么只需扫描索引即可完成查询,若用到了索引覆盖范围以外的列就需要书签查找来获取数据,当这种查找发生次较多时就会导致索引失效从而导致表扫描,因为查询优化器是基于开销的优化器,当其发现使用非聚集索引引发的书签查找开销比表扫描开销还大时就会放弃使用索引,转向表扫描。
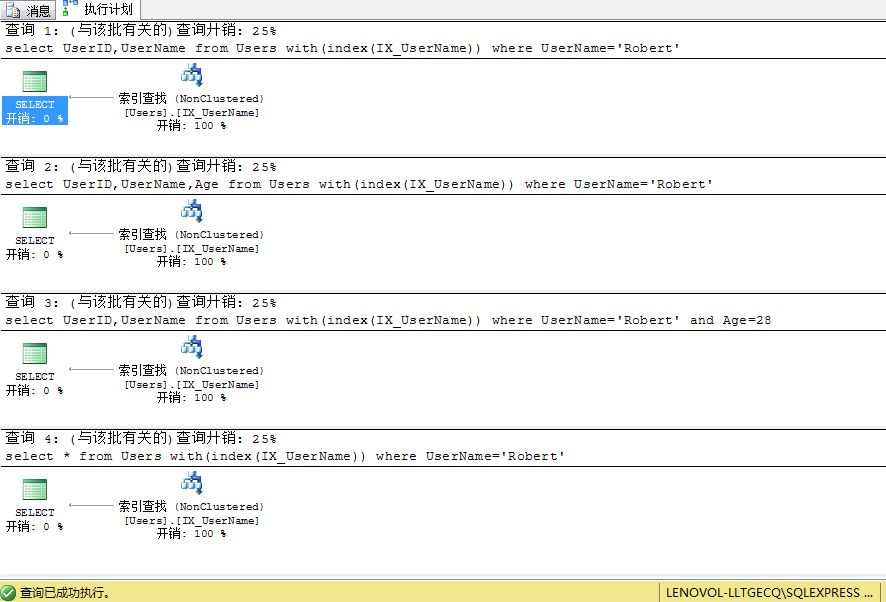
1.在UserName,Age列上重建索引IX_UserName,这时对于索引IX_UserName来说覆盖列变为(UserName,Age,UserID),再次执行上面的查询SQL可以发现查询计划已经发生变化
代码如下:
drop index IX_UserName on Userscreate index IX_UserName on Users(UserName,Age)
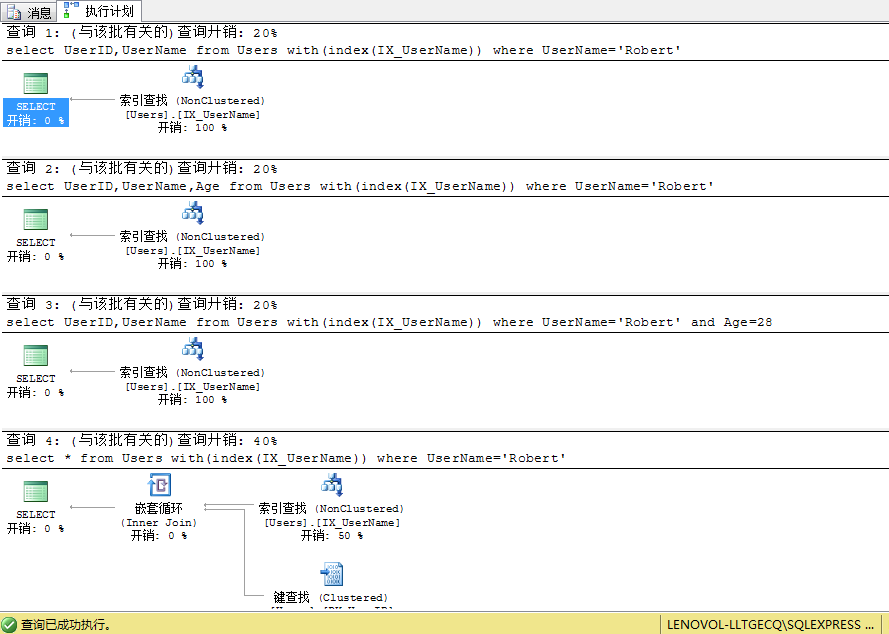
我们可以看到查询2、查询3的书签查找已经消失,因为索引IX_UserName包含了查询中用到得所有列(UserID,UserName,Age),查询4因为选择返回所有列我们的索引没有包含Gender和CreateTime列,故还是会进行书签查找
这时索引IX_UserName结构表示如下
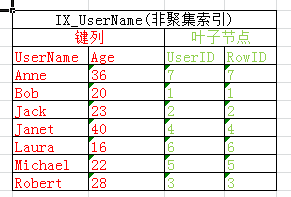
可见对于查询2、查询3仅仅通过索引IX_UserName既可以拿到需要的列UserName,Age,UserID,而对于查询4索引并没有全部覆盖还是需要进行书签查找
2.继续修改我们的索引IX_UserName,使用include包含非键列(键列就是索引上的列,非键列就是索引之外的列,对于include来说就是存放于非聚集索引叶子节点上的列,聚集索引的列也放在非聚集索引的叶子节点上)
代码如下:
drop index IX_UserName on Userscreate index IX_UserName on Users(UserName,Age) include(Gender,CreateTime)
可以看到我们修改索引使用include包含了Gender,CreateTime后,索引IX_UserName达到了对数据表Users的所有列的全覆盖,这时候毫无疑问的查询2、查询3没有出现书签查找,查询4的书签查找也消失了。
此时索引IX_UserName 结构如下

索引IX_UserName已经达到了对Users表的全覆盖,对于我们的查询2、查询3、查询4来说,仅通过索引IX_UserName即可完成查询,不需要进行书签查找。
这时我们再来看一下这两个查询的开销及查询计划,可以看到不需要我们进行索引提示,查询优化器已经自动选择了我们的索引,逻辑读也降至了2次
select * from Users where UserName like 'ja%'select * from Users with(index(IX_UserName)) where UserName like 'ja%'

关于Include请参考 SQL Server 索引中include的魅力(具有包含性列的索引)
这里说明下书签查找对查询性能有着较大的影响并且基本上不可避免,这并不意味着书签查找就是洪水猛兽,原来我们不是也不知道啥叫书签查找么,查询性能一样也不差,是吧,呵呵。书签查找也说明了为什么我们不推荐写sql时使用select *,也解释了为什么有时候我们的索引会失效,同时可以作为优化查询性能考虑的一个方面,在设计表和索引时尽量规避书签查找带来的负面影响,比如非聚集索引尽量选择高选择性的列即返回尽量少的行,需要大批量数据查询时尽量使用聚集索引等。
本文中为了便于演示仅仅使用了有几条数据的表,而且查询中为了使用索引都用了索引提示,实际开发中请不要使用索引提示,查询优化器大多数情况下会为我们生成最优(最优不代表开销最小,只要开销足够小即认为最优)的执行计划,索引结构里面用到得RowID也仅仅是为了演示虚构出来的,我们只要认为它是对于数据行的一个标识位就行了。
此文旨在让我们认识书签查找并意识到书签查找的意义,从而对于索引失效原因有清晰的认识,更好的理解查询计划。
相关推荐
-

SQL Server里书签查找的性能伤害
在我的博客上,以前我经常谈到SQL Serverl里的书签查找,还有它们带来的很多问题.在今天的文章里,我想从性能角度进一步谈下书签查找,还有它们如何拉低你整个SQL Server性能. 书签查找--反复循环 如果你的非聚集索引不是个覆盖非聚集索引,SQL Server的查询优化器会引入书签查找.对于从非聚集索引你返回的每一行,SQL Server需要在聚集索引里或堆表里进行额外的查找操作. 例如当你的的聚集索引包含3层,为了返回必要的信息,对于每一行,你需要3页额外的读取.因此,查询优化器再执
-
Sql Server查询性能优化之不可小觑的书签查找介绍
小小程序猿SQL Server认知的成长 1.没毕业或工作没多久,只知道有数据库.SQL这么个东东,浑然分不清SQL和Sql Server Oracle.MySql的关系,通常认为SQL就是SQL Server 2.工作好几年了,也写过不少SQL,却浑然不知道索引为何物,只知道数据库有索引这么个东西,分不清聚集索引和非聚集索引,只知道查询慢了建个索引查询就快了,到头来索引也建了不少,查询也确实快了,偶然问之:汝建之索引为何类型?答曰:... 3.终于受到刺激开始奋发图强,买书,gg查资料终于知道
-
Sql Server 查询性能优化之走出索引的误区分析
据了解绝大多数开发人员对于索引的理解都是一知半解,局限于大多数日常工作没有机会.也什么没有必要去关心.了解索引,实在哪天某个查询太慢了找到查询条件建个索引就ok,哪天又有个查询慢了,再建立个索引就是,或者干脆把整个查询SQL直接发给DBA,让DBA直接帮忙优化了,所以造成的状况就是开发人员对于索引的理解.认识很局限,以下就把我个人对于索引的理解及浅薄认识和大家分享下,希望能解除一些大家的疑惑,一起走出索引的误区 误区1.在表上建立了索引,在查询时用到了索引的列,索引就一定会生效 首先明确下这样的
-
SQL Server数据库性能优化技术第1/2页
设计1个应用系统似乎并不难,但是要想使系统达到最优化的性能并不是一件容易的事.在开发工具.数据库设计.应 用程序的结构.查询设计.接口选择等方面有多种选择,这取决于特定的应用需求以及开发队伍的技能.本文以SQL Server为例,从后台数据库的角度讨论应用程序性能优化技巧,并且给出了一些有益的建议. 1 数据库设计 要在良好的SQL Server方案中实现最优的性能,最关键的是要有1个很好的数据库设计方案.在实际工作中,许多SQL Server方案往往是由于数据库设计得不好导致性能很差.
-
SQL Server查询结果导出到EXCEL表格的图文教程
需求: 将查询的两列数据导出到excel中 1.选择数据库,右键任务→导出数据,打开导入导出向导,单击下一步 2.在打开的SQL Server导入和导出的向导中,选择服务器名称.代表本机,身份验证使用SQL Server身份验证,输入用户名,密码,选择数据库,单击下一步 3.选择目标为Mircosoft Excel,选择Excel需要保存的路径,单击下一步 4.选择编写查询以指定要传输的数据,单击下一步 5.复制SQL语句到对话框中,单击下一步 6.可以编辑映射,查看预览,剩余的一直下一步,直至
-
windows server 2019 性能优化和安全配置小结
最近机器都升级到了windows server 2019 数据中心版,之前我们小编已经为大家分享了windows2008,2016 server的安全设置,其实2019与2016类似都是基于win10的服务器,所以这里就简单介绍一下 一般拿到服务器第一步不要安装更新就是 安装步骤 1.安装iis+php运行环境 2.安装mysql或者sqlserver(mysql安装zip版,sqlserver 可以安装2016或2019) 3.然后可以升级补丁,因为怕安全设置好以后打补丁会出问题或者打不上补丁
-
sql server查询语句阻塞优化性能
在生产环境下,有时公司客服反映网页半天打不到,除了在浏览器按F12的Network响应来排查,确定web服务器无故障后.就需要检查数据库是否有出现阻塞 当时数据库的生产环境中主表数据量超过2000w,子表数据量超过1亿,且更新和新增频繁.再加上做了同步镜像,很消耗资源. 这时就要新建一个会话,大概需要了解以下几点: 1.当前活动会话量有多少? 2.会话运行时间? 3.会话之间有没有阻塞? 4.阻塞时间 ? 查询阻塞的方法有很多.有sql 2000 的sp_lock, 有sql 2005及以上的d
-
SQL SERVER使用表分区优化性能
目录 1.简介 2.表分区 2.1分区范围 2.2分区键 2.3索引分区 3.创建表分区 3.1创建文件组 3.2指定文件组存放路径 3.3创建分区函数 3.4创建分区方案 3.5创建分区表 3.6创建分区索引 4.表分区的优缺点 1.简介 当一个表数据量很大时候,很自然我们就会想到将表拆分成很多小表,在执行查询时候就到各个小表去查,最后汇总数据集返回给调用者加快查询速度.比如电商平台订单表,库存表,由于长年累月读写较多,积累数据都是异常庞大的,这时候,我们可以想到表分区这个做法,降低运维和维护
-
sql server排查死锁优化性能
一.概述 记得以前客户在使用软件时,有偶发出现死锁问题,因为发生的时间不确定,不好做问题的重现,当时解决问题有点棘手了.现总结下查看死锁的常用二种方式. 1.1 第一种是图形化监听: sqlserver -->工具--> sql server profiler 登录后在跟踪属性中选择如下图: 监听到的死锁图形如下图 这里的描述大致是:有二个进程 一个进程ID是96, 另一个ID是348. 系统自动kill 掉了进程ID:96,保留了进程ID:348 的事务Commit. 上面死锁是由于批量更新
-
教你如何看懂SQL Server查询计划
对于SQL Server的优化来说,优化查询可能是很常见的事情.由于数据库的优化,本身也是一个涉及面比较的广的话题,因此本文只谈优化查询时如何看懂SQL Server查询计划.毕竟我对SQL Server的认识有限,如有错误,也恳请您在发现后及时批评指正. 首先,打开[SQL Server Management Studio],输入一个查询语句看看SQL Server是如何显示查询计划的吧. 说明:本文所演示的数据库,是我为一个演示程序专用准备的数据库,可以在此网页中下载. select v.O
-
MySQL查询性能优化索引下推
目录 前言 1. 索引下推的作用 2. 案例实践 3. 索引下推配置 4. 索引下推原理剖析 5. 索引下推应用范围 前言 前面已经讲了MySQL的其他查询性能优化方式,没看过可以去了解一下: MySQL查询性能优化七种方式索引潜水 MySQL查询性能优化武器之链路追踪 今天要讲的是MySQL的另一种查询性能优化方式 — 索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本增加的特性. 1. 索引下推的作用 主要作用有两个: 减少回表查询的次数 减少存