SQL Server 索引介绍
一,索引的概述
1,概念: 数据库索引是对数据表中一个或多个列的值进行排序的结构,就像一本书的目录一样,索引提供了在行中快速查询特定行的能力.
2,优缺点:
2.1优点: 1,大大加快搜索数据的速度,这是引入索引的主要原因.
2,创建唯一性索引,保证数据库表中每一行数据的唯一性.
3,加速表与表之间的连接,特别是在实现数据的参考完整性方面特别有意义.
4,在使用分组和排序子句进行数据检索时,同样可以减少其使用时间.
2,2缺点: 1,索引需要占用物理空间,聚集索引占的空间更大.
2,创建索引和维护索引需要耗费时间,这种时间会随着数据量的增加而增加.
3,当向一个包含索引的列的数据表中添加或者修改记录时,SQL server 会修改和维护相应的索引,这样增加系统的额外开销,降低处理速度。
3,索引的分类:
1,按存储结构可分为:
a,聚集索引:指物理存储顺序与索引顺序完全相同,它由上下两层组成,上层为索引页,下层为数据页,只有一种排序方式,因此每个表中只能创建一个聚集索引。
b,非聚集索引:指存储的数据顺序一般和表的物理数据的存储结构不同。通过下表我们可以分析出:(其中在学号上建立非聚集索引)
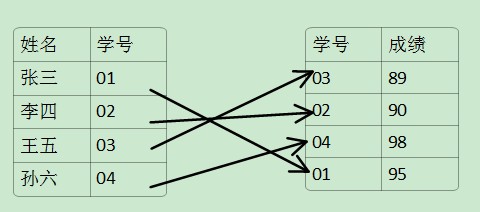
2,根基索引键值是否唯一,可以判定是否为唯一索引;基于多个字段的组合创建索引的为组合索引。二,索引的操作:
1,创建:(1),原则:a,只有表的所有者可以在同一个表中创建索引;
b,每个表中只可以创建一个聚集索引;
c,每个表中最多可以创建249个非聚集索引;
d,在经常查询的字段上建立索引;
e,定义text,image和bit数据类型的裂伤不能创建索引;
f,在外键列上可以创建索引,主键上一定要有索引;
g,在那些重复值比较多的,查询较少的列上不要建立索引。
(2),方法:a,使用SQL server Management Studio创建索引。
b,使用T-SQL语句中的create Index语句创建索引
c,使用Create table或者alter Table语句为表列定义主键约束或者唯一性约束时,会自动创建主键索引和惟一索引。
这里说说T-sql语句创建索引:
语法:
create relational index create[unique][clustered|nonclustered] index index_name on<object>(cloumn[asc|desc][,……n]) [include (column_name[,……n])] [with(<relational_index_option>[,……n])] [onfilegroup_name]
说明:1,include (column_name[,……n])指定要添加到非聚集索引的叶级别的非键列。
2,on filegroup_name,为指定文件组创建指定索引。
例如:在course表中,对“课程代号”列创建聚集索引zindex.
use db_student create clustered index zindex on course(课程代号)
2,查看索引:(1),使用SQL ServerManagement Studio查看索引信息
(2),使用系统存储过程查询索引信息,用SP_helpindex可以返回表中的所有索引信息
例如:查看course表的索引信息
use db_student execsp_helpindex course[/code]3,修改索引:
(1),在SQL Server Management Studio 中修改索引
(2),使用Alter Index语句修改索引
在这里为大家举一个例子:
在course数据表中,修改所有的索引,并指定选项
use db_student alterindex all on course rebuild with (fillfactor=80,sort_in_tempdb=on,statistics_norecompute=on)
4,删除索引:
(1),使用SQL Server Management Studio 删除索引
(2),使用Drop index语句删除索引
例如:在course表中,删除zindex索引
use db_student drop index course.zindex
三,索引的分析和维护:
分析:1,使用showplan 语句
语法:set showplan_all{on|off},set showplan_next{on|off}
例子:显示表course的课程代号,课程类型,课程内容,并显示查询过程
use db_student set showplan_all on select 课程代号,课程类型 课程内容 from course where 课程内容='loving'
2,使用statistics io语句
语法:statistics io{on|off} on和off分别为显示和不显示,使用方法和上一样。
维护: 1,使用dbcc showcontig语句,显示指定表的数据和索引的碎片信息。当对表中进行大量修改或添加数据后,应该执行此语句查看有无碎片。
语法:dbcc showcontig[{table_name|table_id|view_name|view_id},index_name|index_id] with fast
2,使用dbcc dbreindex语句,意思是重建数据库中表的一个或多个索引。
语法:
dbcc dbreindex (['database.owner.table_name'[,index_name[,fillfactor]]]) [withno_infomsgs]
说明: database.owner.table_name,重新建立索引的表名
index_name,是要重建的索引名
fillfactor,要创建索引时每个索引页上要用于存储数据的空间百分比。
with no_infomsgs,禁止显示所有信息性消息
3,使用dbcc indexdefrag,整理指定的表或视图的聚集索引和辅助索引碎片。
语法:
dbcc indexdefrag ({database_name|database_id|0},{table_name|table_id|'view_name'|view_id},{index_name|index_id}) with no_infomsgs
总结,只有我们对索引有了充分了熟悉;我们掌握了索引的增删改查四项基本操作,学会利用SQL Server ManagerSdudio去实现这些功能,和学会利用T-SQL语句去实现(自我感觉利用SQL Server Manager Sdudio 简单一些);当然还要懂得学会分析和维护索引,这样才会更好的让它为咱们服务!
相关推荐
-
SQLSERVER 创建索引实现代码
什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K.为了加快查找的速度,汉语字(词)典一般都有按拼音.笔画.偏旁部首等排序的目录(索引),我们可以选择按拼音或笔画查找方式,快速查找到需要的字(词). 同理,SQL Server允许用户在表中创建索引,指定按某列预先排序,从而大大提高查询速度. • SQL Server中的数据也是按页(4KB)存放 • 索引:是SQL Server编排数据的内部方法.它
-

SQLSERVER聚集索引和主键(Primary Key)的误区认识
很多人会把Primary Key和聚集索引搞混起来,或者认为这是同一个东西.这个概念是非常错误的. 主键是一个约束(constraint),他依附在一个索引上,这个索引可以是聚集索引,也可以是非聚集索引. 所以在一个(或一组)字段上有主键,只能说明他上面有个索引,但不一定就是聚集索引. 例如下面: 复制代码 代码如下: USE [pratice] GO CREATE TABLE #tempPKCL ( ID INT PRIMARY KEY CLUSTERED --聚集索引 ) ---------
-
sqlserver索引的原理及索引建立的注意事项小结
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上.就好像参考手册将所有主题按顺序编排一样.一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据. SQL Server中的索引使用标准的B-树来存储他们的信息,如下图所示,B-树通过查找索引中的一个关键之来提供对于数据的快速访问,B-树以相似的键记录聚合在一起,B不代表二叉(binary),而是代表balanced(平衡的),而B-树的一个核心作用就
-
SQL Server 聚集索引和非聚集索引的区别分析
聚集索引:物理存储按照索引排序非聚集索引:物理存储不按照索引排序优势与缺点聚集索引:插入数据时速度要慢(时间花费在"物理存储的排序"上,也就是首先要找到位置然后插入)查询数据比非聚集数据的速度快 汉语字典的正文本身就是一个聚集索引.比如,我们要查"安"字,就会很自然地翻开字典的前几页,因为"安"的拼音是"an",而按照拼音排序汉字的字典是以英文字母"a"开头并以"z"结尾的,那么&quo
-
SQL SERVER 2008 R2 重建索引的方法
参考sys.dm_db_index_physical_stats 检查索引碎片情况 1.SELECT 2.OBJECT_NAME(object_id) as objectname, 3.object_id AS objectid, 4.index_id AS indexid, 5.partition_number AS partitionnum, 6.avg_fragmentation_in_percent AS fra 7.FROM sys.dm_db_index_physical_stats
-
提升SQL Server速度 整理索引碎片
凭经验,这是索引碎片问题.检查索引碎片DBCC SHOWCONTIG(表),得到如下结果: DBCC SHOWCONTIG 正在扫描 'A' 表... 表: 'A'(884198200):索引 ID: 1,数据库 ID: 13 已执行 TABLE 级别的扫描. - 扫描页数.....................................: 3127 - 扫描扩展盘区数...............................: 403 - 扩展盘区开关数..............
-
sqlserver 索引的一些总结
1.1.1 摘要 如果说要对数据库进行优化,我们主要可以通过以下五种方法,对数据库系统进行优化. 1. 计算机硬件调优 2. 应用程序调优 3. 数据库索引优化 4. SQL语句优化 5. 事务处理调优 在本篇博文中,我们将想大家讲述数据库中索引类型和使用场合,本文以SQL Server为例,对于其他技术平台的朋友也是有参考价值的,只要替换相对应的代码就行了! 索引使数据库引擎执行速度更快,有针对性的数据检索,而不是简单地整表扫描(Full table scan). 为了使用有效的索引,我们必须
-
SqlServer索引的原理与应用详解
索引的概念 索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法. 索引是什么:数据库中的索引类似于一本书的目录,在一本书中使用目录可以快速找到你想要的信息,而不需要读完全书.在数据库中,数据库程序使用索引可以重啊到表中的数据,而不必扫描整个表.书中的目录是一个字词以及各字词所在的页码列表,数据库中的索引是表中的值以及各值存储位置的列表. 索引的利弊:查询执行的大部分开销是I/O,使用索引提高性能的一个主要目标是避免全表扫描,因
-
SQL Server全文索引服务
SQL 7的全文检索和Index Server的检索方式非常类似. Contains AND, OR, NOT 可以在Contains中很方便使用逻辑表达式 Example: Select username from member where contains(userinfo,'"作家" AND "木匠"') Select username from member where contains(userinfo,'"作家" OR "
-
SQLSERVER全文目录全文索引的使用方法和区别讲解
先介绍一下SQLSERVER中的存储类对象,哈哈,先介绍一下概念嘛,让新手老手都有一个认知SQLSERVER Management Studio将[全文目录].[分区函数]以及[分区方案]节点纳入其[对象资源管理器]的[存储]节点之中,如下图所示: 全文目录 数据库[存储]|[全文目录]节点是用于保存和管理[全文索引]的节点.全文目录通常是由同一数据库中的零个或多个数据表的全文索引构成的.需要注意的是,只能为每个数据表创建一个全文索引.因此,一旦在某个数据表上创建了全文索引,那么该数据表将只能隶