浅谈Python单向链表的实现
链表由一系列不必在内存中相连的结构构成,这些对象按线性顺序排序。每个结构含有表元素和指向后继元素的指针。最后一个单元的指针指向NULL。为了方便链表的删除与插入操作,可以为链表添加一个表头。
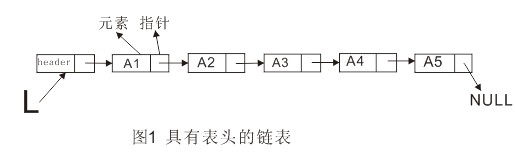
删除操作可以通过修改一个指针来实现。
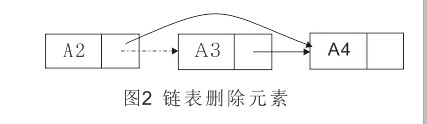
插入操作需要执行两次指针调整。

1. 单向链表的实现
1.1 Node实现
每个Node分为两部分。一部分含有链表的元素,可以称为数据域;另一部分为一指针,指向下一个Node。
class Node():
__slots__=['_item','_next'] #限定Node实例的属性
def __init__(self,item):
self._item=item
self._next=None #Node的指针部分默认指向None
def getItem(self):
return self._item
def getNext(self):
return self._next
def setItem(self,newitem):
self._item=newitem
def setNext(self,newnext):
self._next=newnext
1.2 SinglelinkedList的实现
class SingleLinkedList():
def __init__(self):
self._head=None #初始化链表为空表
self._size=0
1.3 检测链表是否为空
def isEmpty(self): return self._head==None
1.4 add在链表前端添加元素
def add(self,item): temp=Node(item) temp.setNext(self._head) self._head=temp
1.5 append在链表尾部添加元素
def append(self,item):
temp=Node(item)
if self.isEmpty():
self._head=temp #若为空表,将添加的元素设为第一个元素
else:
current=self._head
while current.getNext()!=None:
current=current.getNext() #遍历链表
current.setNext(temp) #此时current为链表最后的元素
1.6 search检索元素是否在链表中
def search(self,item):
current=self._head
founditem=False
while current!=None and not founditem:
if current.getItem()==item:
founditem=True
else:
current=current.getNext()
return founditem
1.7 index索引元素在链表中的位置
def index(self,item):
current=self._head
count=0
found=None
while current!=None and not found:
count+=1
if current.getItem()==item:
found=True
else:
current=current.getNext()
if found:
return count
else:
raise ValueError,'%s is not in linkedlist'%item
1.8 remove删除链表中的某项元素
def remove(self,item):
current=self._head
pre=None
while current!=None:
if current.getItem()==item:
if not pre:
self._head=current.getNext()
else:
pre.setNext(current.getNext())
break
else:
pre=current
current=current.getNext()
1.9 insert链表中插入元素
def insert(self,pos,item):
if pos<=1:
self.add(item)
elif pos>self.size():
self.append(item)
else:
temp=Node(item)
count=1
pre=None
current=self._head
while count<pos:
count+=1
pre=current
current=current.getNext()
pre.setNext(temp)
temp.setNext(current)
全部代码
class Node():
__slots__=['_item','_next']
def __init__(self,item):
self._item=item
self._next=None
def getItem(self):
return self._item
def getNext(self):
return self._next
def setItem(self,newitem):
self._item=newitem
def setNext(self,newnext):
self._next=newnext
class SingleLinkedList():
def __init__(self):
self._head=None #初始化为空链表
def isEmpty(self):
return self._head==None
def size(self):
current=self._head
count=0
while current!=None:
count+=1
current=current.getNext()
return count
def travel(self):
current=self._head
while current!=None:
print current.getItem()
current=current.getNext()
def add(self,item):
temp=Node(item)
temp.setNext(self._head)
self._head=temp
def append(self,item):
temp=Node(item)
if self.isEmpty():
self._head=temp #若为空表,将添加的元素设为第一个元素
else:
current=self._head
while current.getNext()!=None:
current=current.getNext() #遍历链表
current.setNext(temp) #此时current为链表最后的元素
def search(self,item):
current=self._head
founditem=False
while current!=None and not founditem:
if current.getItem()==item:
founditem=True
else:
current=current.getNext()
return founditem
def index(self,item):
current=self._head
count=0
found=None
while current!=None and not found:
count+=1
if current.getItem()==item:
found=True
else:
current=current.getNext()
if found:
return count
else:
raise ValueError,'%s is not in linkedlist'%item
def remove(self,item):
current=self._head
pre=None
while current!=None:
if current.getItem()==item:
if not pre:
self._head=current.getNext()
else:
pre.setNext(current.getNext())
break
else:
pre=current
current=current.getNext()
def insert(self,pos,item):
if pos<=1:
self.add(item)
elif pos>self.size():
self.append(item)
else:
temp=Node(item)
count=1
pre=None
current=self._head
while count<pos:
count+=1
pre=current
current=current.getNext()
pre.setNext(temp)
temp.setNext(current)
if __name__=='__main__':
a=SingleLinkedList()
for i in range(1,10):
a.append(i)
print a.size()
a.travel()
print a.search(6)
print a.index(5)
a.remove(4)
a.travel()
a.insert(4,100)
a.travel()
相关推荐
-
python单链表实现代码实例
链表的定义:链表(linked list)是由一组被称为结点的数据元素组成的数据结构,每个结点都包含结点本身的信息和指向下一个结点的地址.由于每个结点都包含了可以链接起来的地址信息,所以用一个变量就能够访问整个结点序列.也就是说,结点包含两部分信息:一部分用于存储数据元素的值,称为信息域:另一部分用于存储下一个数据元素地址的指针,称为指针域.链表中的第一个结点的地址存储在一个单独的结点中,称为头结点或首结点.链表中的最后一个结点没有后继元素,其指针域为空. python单链表实现代码: 复制代码
-
Python数据结构之单链表详解
本文实例为大家分享了Python数据结构之单链表的具体代码,供大家参考,具体内容如下 # 节点类 class Node(): __slots__=['_item','_next'] # 限定Node实例的属性 def __init__(self,item): self._item = item self._next = None # Node的指针部分默认指向None def getItem(self): return self._item def getNext(self): return s
-

python数据结构之链表详解
数据结构是计算机科学必须掌握的一门学问,之前很多的教材都是用C语言实现链表,因为c有指针,可以很方便的控制内存,很方便就实现链表,其他的语言,则没那么方便,有很多都是用模拟链表,不过这次,我不是用模拟链表来实现,因为python是动态语言,可以直接把对象赋值给新的变量. 好了,在说我用python实现前,先简单说说链表吧.在我们存储一大波数据时,我们很多时候是使用数组,但是当我们执行插入操作的时候就是非常麻烦,看下面的例子,有一堆数据1,2,3,5,6,7我们要在3和5之间插入4,如果用数组,我
-
Python实现的数据结构与算法之链表详解
本文实例讲述了Python实现的数据结构与算法之链表.分享给大家供大家参考.具体分析如下: 一.概述 链表(linked list)是一组数据项的集合,其中每个数据项都是一个节点的一部分,每个节点还包含指向下一个节点的链接. 根据结构的不同,链表可以分为单向链表.单向循环链表.双向链表.双向循环链表等.其中,单向链表和单向循环链表的结构如下图所示: 二.ADT 这里只考虑单向循环链表ADT,其他类型的链表ADT大同小异.单向循环链表ADT(抽象数据类型)一般提供以下接口: ① SinCycLin
-
Python单链表的简单实现方法
本文实例讲述了Python单链表的简单实现方法,分享给大家供大家参考.具体方法如下: 通常来说,要定义一个单链表,首先定义链表元素:Element.它包含3个字段: list:标识自己属于哪一个list datum:改元素的value next:下一个节点的位置 具体实现代码如下: class LinkedList(object): class Element(object): def __init__(self,list,datum,next): self._list = list self.
-
Python单链表简单实现代码
本文实例讲述了Python单链表简单实现代码.分享给大家供大家参考,具体如下: 用Python模拟一下单链表,比较简单,初学者可以参考参考 #coding:utf-8 class Node(object): def __init__(self, data): self.data = data self.next = None class NodeList(object): def __init__(self, node): self.head = node self.head.next = No
-
Python数据结构与算法之列表(链表,linked list)简单实现
Python 中的 list 并不是我们传统(计算机科学)意义上的列表,这也是其 append 操作会比 insert 操作效率高的原因.传统列表--通常也叫作链表(linked list)--通常是由一系列节点(node)来实现的,其每一个节点(尾节点除外)都持有一个指向下一个节点的引用. 其简单实现: class Node: def __init__(value, next=None): self.value = value self.next = next 接下来,我们就可使用链表的结构来
-
浅谈Python单向链表的实现
链表由一系列不必在内存中相连的结构构成,这些对象按线性顺序排序.每个结构含有表元素和指向后继元素的指针.最后一个单元的指针指向NULL.为了方便链表的删除与插入操作,可以为链表添加一个表头. 删除操作可以通过修改一个指针来实现. 插入操作需要执行两次指针调整. 1. 单向链表的实现 1.1 Node实现 每个Node分为两部分.一部分含有链表的元素,可以称为数据域:另一部分为一指针,指向下一个Node. class Node(): __slots__=['_item','_next'] #限定N
-
浅谈python中copy和deepcopy中的区别
在下是个编程爱好者,最近将魔爪伸向了Python编程.....遇到copy和deepcopy感到很困惑,现在针对这两个方法进行区分,一种是浅复制(copy),一种是深度复制(deepcopy). 首先说一下deepcopy,所谓的深度复制,在这里我理解的是完全复制然后变成一个新的对象,复制的对象和被复制的对象没有任何关系,彼此之间无论怎么改变都相互不影响. 然后说一下copy,在这里我分为两类来说,一种是字典数据类型的copy函数,一种是copy包的copy函数. 一.字典数据类型的copy函数
-
浅谈python中列表、字符串、字典的常用操作
列表操作如此下: a = ["haha","xixi","baba"] 增:a.append[gg] a.insert[1,gg] 在下标为1的地方,新增 gg 删:a.remove(haha) 删除列表中从左往右,第一个匹配到的 haha del a.[0] 删除下标为0 对应的值 a.pop(0) 括号里不写内容,默认删除最后一个,写了,就删除对应下标的内容 改:a.[0] = "gg" 查:a[0] a.index(&q
-
浅谈Python数据类型之间的转换
Python数据类型之间的转换 函数 描述 int(x [,base]) 将x转换为一个整数 long(x [,base] ) 将x转换为一个长整数 float(x) 将x转换到一个浮点数 complex(real [,imag]) 创建一个复数 str(x) 将对象 x 转换为字符串 repr(x) 将对象 x 转换为表达式字符串 eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象 tuple(s) 将序列 s 转换为一个元组 list(s) 将序列 s 转换为一个
-
浅谈Python 字符串格式化输出(format/printf)
Python 字符串格式化使用 "字符 %格式1 %格式2 字符"%(变量1,变量2),%格式表示接受变量的类型.简单的使用例子如下: # 例:字符串格式化 Name = '17jo' print 'www.%s.com'%Name >> www.17jo.com Name = '17jo' Zone = 'com' print 'www.%s.%s'%(Name,Zone) >> www.17jo.com 字符串格式化时百分号后面有不同的格式符号,代表
-
浅谈Python基础之I/O模型
一.I/O模型 IO在计算机中指Input/Output,也就是输入和输出.由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口. 同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别? 这个问题其实不同的人给出的答案都可能不同,比如wiki,就认为asynchronous IO和non-blockin
-
浅谈python for循环的巧妙运用(迭代、列表生成式)
介绍 我们可以通过for循环来迭代list.tuple.dict.set.字符串,dict比较特殊dict的存储不是连续的,所以迭代(遍历)出来的值的顺序也会发生变化. 迭代(遍历) #!/usr/bin/env python3 #-*- coding:utf-8 -*- vlist=['a','b','c'] vtuple=('a','b','c') vdict={'a': 1, 'b': 2, 'c': 3} vset={'a','b','c'} vstr='abc' for x in vl
-
浅谈Python中函数的参数传递
1.普通的参数传递 >>> def add(a,b): return a+b >>> print add(1,2) 3 >>> print add('abc','123') abc123 2.参数个数可选,参数有默认值的传递 >>> def myjoin(string,sep='_'): return sep.join(string) >>> myjoin('Test') 'T_e_s_t' >>>
-
浅谈Python中用datetime包进行对时间的一些操作
1. 计算给出两个时间之间的时间差 import datetime as dt # current time cur_time = dt.datetime.today() # one day pre_time = dt.date(2016, 5, 20) # eg: 2016.5.20 delta = cur_time - pre_time # if you want to get discrepancy in days print delta.days # if you want to get
-
浅谈python 四种数值类型(int,long,float,complex)
Python支持四种不同的数值类型,包括int(整数)long(长整数)float(浮点实际值)complex (复数),本文章向码农介绍python 四种数值类型,需要的朋友可以参考一下. 数字数据类型存储数值.他们是不可改变的数据类型,这意味着改变数字数据类型的结果,在一个新分配的对象的值. Number对象被创建,当你给他们指派一个值.例如: var1 = 1 var2 = 10 您也可以删除数字对象的参考,使用del语句. del语句的语法是: del var1[,var2[,var3[