Python进行数据提取的方法总结
准备工作
首先是准备工作,导入需要使用的库,读取并创建数据表取名为loandata。
import numpy as np
import pandas as pd
loandata=pd.DataFrame(pd.read_excel('loan_data.xlsx'))

设置索引字段
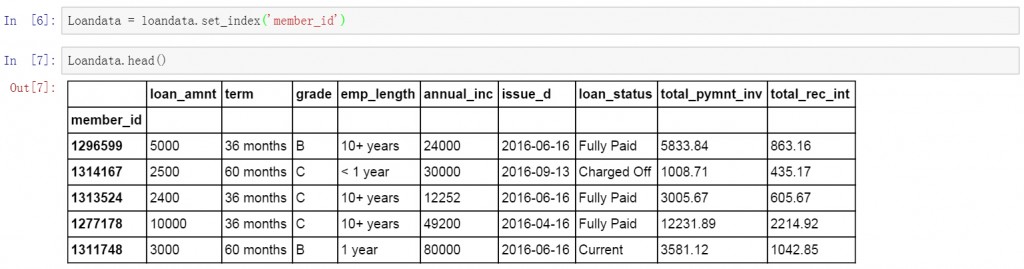
在开始提取数据前,先将member_id列设置为索引字段。然后开始提取数据。
Loandata = loandata.set_index('member_id')
按行提取信息
第一步是按行提取数据,例如提取某个用户的信息。下面使用ix函数对member_id为1303503的用户信息进行了提取。
loandata.ix[1303503]

按列提取信息
第二步是按列提取数据,例如提取用户工作年限列的所有信息,下面是具体的代码和提取结果,显示了所有用户的工作年龄信息。
loandata.ix[:,'emp_length']

按行与列提取信息
第三步是按行和列提取信息,把前面两部的查询条件放在一起,查询特定用户的特定信息,下面是查询member_id为1303503的用户的emp_length信息。
loandata.ix[1303503,'emp_length']

在前面的基础上继续增加条件,增加一行同时查询两个特定用户的贷款金额信息。具体代码和查询结果如下。结果中分别列出了两个用户的代码金额。
loandata.ix[[1303503,1298717],'loan_amnt']

在前面的代码后增加sum函数,对结果进行求和,同样是查询两个特定用户的贷款进行,下面的结果中直接给出了贷款金额的汇总值。
loandata.ix[[1303503,1298717],'loan_amnt'].sum()

除了增加行的查询条件以外,还可以增加列的查询条件,下面的代码中查询了一个特定用户的贷款金额和年收入情况,结果中分别显示了这两个字段的结果。
loandata.ix[1303503,['loan_amnt','annual_inc']]

多个列的查询也可以进行求和计算,在前面的代码后增加sum函数,对这个用户的贷款金额和年收入两个字段求和,并显示出结果。
loandata.ix[1303503,['loan_amnt','annual_inc']].sum()

提取特定日期的信息
数据提取中还有一种很常见的需求就是按日期维度对数据进行汇总和提取,如按月,季度的汇总数据提取和按特定时间段的数据提取等等。
设置索引字段
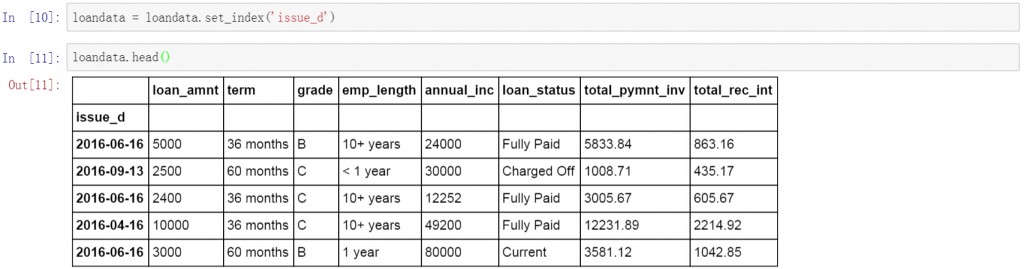
首先将索引字段改为数据表中的日期字段,这里将issue_d设置为数据表的索引字段。按日期进行查询和数据提取。
loandata = loandata.set_index('issue_d')
按日期提取信息
下面的代码查询了所有2016年的数据。
loandata['2016']

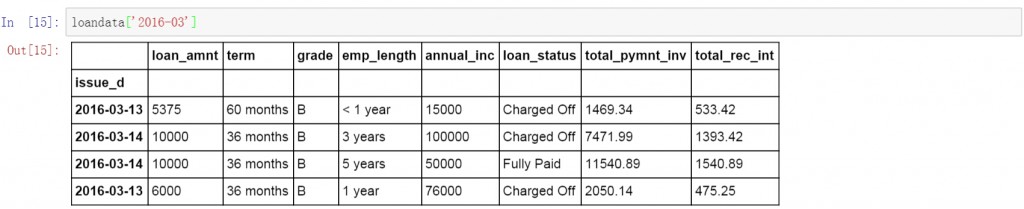
在前面代码的基础上增加月份,查询所有2016年3月的数据。
loandata['2016-03']
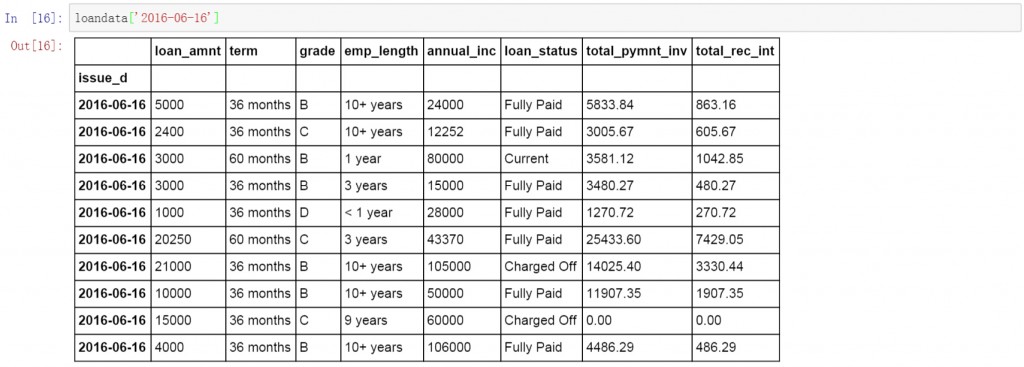
继续在前面代码的基础上增加日期,查询所有2016年6月16日的数据。
loandata['2016-06-16']
除了按单独日期查询以外,还可以按日期段进行数据查询,下面的代码中查询了所有2016年1月至5月的数据。下面显示了具体的查询结果,可以发现数据的日期都是在1-5月的,但是按日期维度显示的,这就需要我们对数据按月进行汇总。
loandata['2016-01':'2016-05']
按日期汇总信息
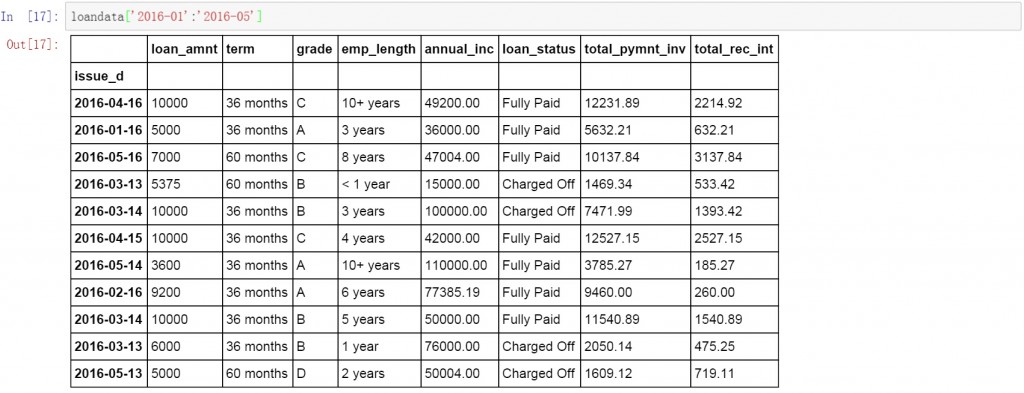
Pandas中的resample函数可以完成日期的聚合工作,包括按小时维度,日期维度,月维度,季度及年的维度等等。下面我们分别说明。首先是按周的维度对前面数据表的数据进行求和。下面的代码中W表示聚合方式是按周,how表示数据的计算方式,默认是计算平均值,这里设置为sum,进行求和计算。
loandata.resample('W',how=sum).head(10)
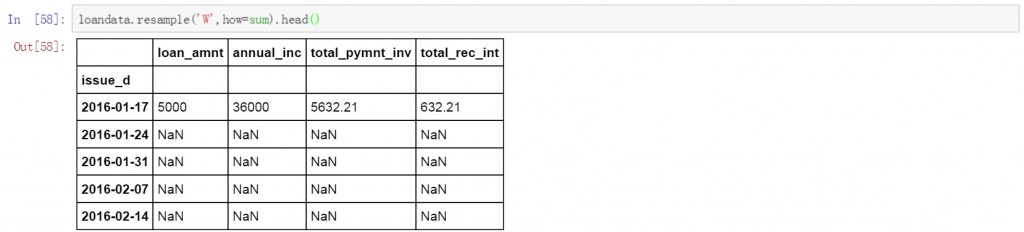
将W改为M,数据变成了按月聚合的方式。计算方式依然是求和。这里需要说明的是resample函数会显示出所有连续的时间段,例如前面按周的聚合操作会显示连续的周日期,这里的按月操作则会在结果中显示连续的月,如果某个时间段没有数据,会以NaN值显示。
loandata.resample('M',how=sum)
将前面代码中的M改为Q,则为按季度对数据进行聚合,计算方式依然为求和。从下面的数据表中看,日期显示的都是每个季度的最后一天,如果希望以每个季度的第一天显示,可以改为QS。
loandata.resample('Q',how=sum)

将前面代码中的Q改为A,就是按年对数据进行聚合,计算方式依然为求和。
loandata.resample('A',how=sum)

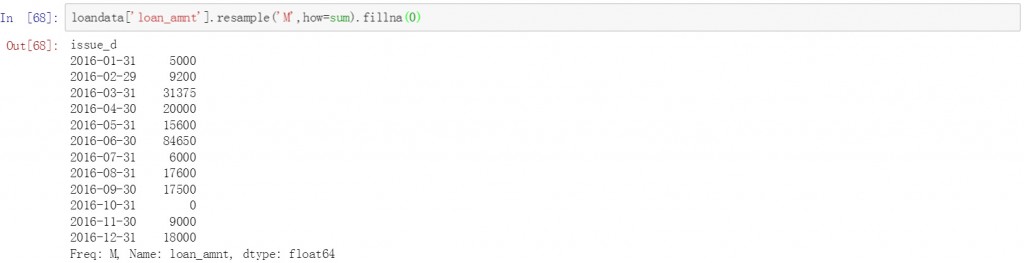
前面的方法都是对整个数据表进行聚合和求和操作,如果只需要对某一个字段的值进行聚合和求和,可以在数据表后增加列的名称。下面是将贷款金额字段按月聚合后求和,并用0填充空值。
loandata['loan_amnt'].resample('M',how=sum).fillna(0)
在前面代码的基础上再增加一个数值字段,并且在后面的计算方式中增加len用来计数。在下面的结果中分别对贷款金额和利息收入按月聚合,并进行求和和计数计算
loandata[['loan_amnt','total_rec_int']].resample('M',how=[len,sum])

有时我们需要只对某一时间段的数据进行聚合和计算,下面的代码中对2016年1月至5月的数据按月进行了聚合,并计算求和。用0填充空值。
loandata['2016-01':'2016-05'].resample('M',how=sum).fillna(0)
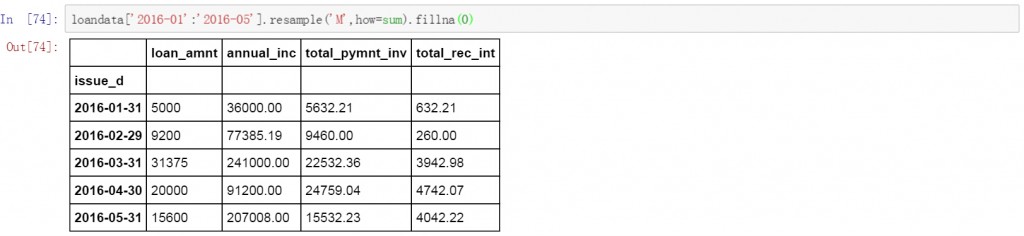
或者只对某些符合条件的数据进行聚合和计算。下面的代码中对于贷款金额大于5000的按月进行聚合,并计算求和。空值以0进行填充。
loandata[loandata['loan_amnt']>5000].resample('M',how=sum).fillna(0)

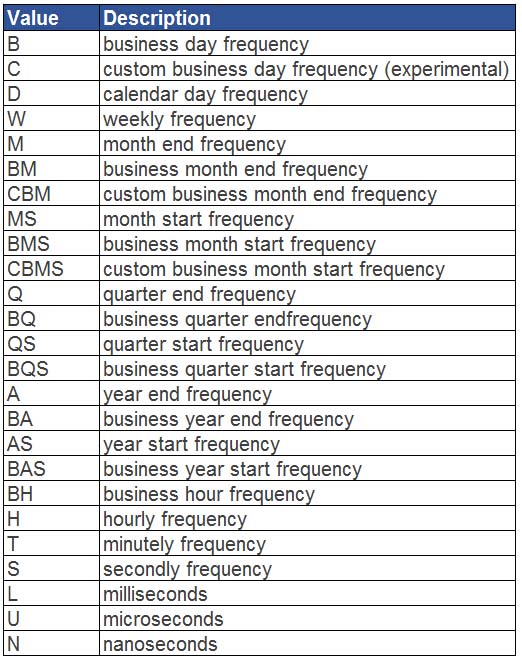
除了按周,月,季度和年以外,resample函数还可以按以下方式对日期进行聚合。
下面给出了具体的对应表和说明。
总结
以上就是利用python按特定的维度或条件对数据进行提取的全部内容,希望本文的内容对大家学习使用Python能有所帮助。
相关推荐
-
python 把数据 json格式输出的实例代码
有个要求需要在python的标准输出时候显示json格式数据,如果缩进显示查看数据效果会很好,这里使用json的包会有很多操作 import json date = {u'versions': [{u'status': u'CURRENT', u'id': u'v2.3', u'links': [{u'href': u'http://controller:9292/v2/', u'rel': u'self'}]}, {u'status': u'SUPPORTED', u'id': u'v2.2'
-

详解Python 数据库 (sqlite3)应用
Python自带一个轻量级的关系型数据库SQLite.这一数据库使用SQL语言.SQLite作为后端数据库,可以搭配Python建网站,或者制作有数据存储需求的工具.SQLite还在其它领域有广泛的应用,比如HTML5和移动端.Python标准库中的sqlite3提供该数据库的接口. 我将创建一个简单的关系型数据库,为一个书店存储书的分类和价格.数据库中包含两个表:category用于记录分类,book用于记录某个书的信息.一本书归属于某一个分类,因此book有一个外键(foreign key)
-
Python实现并行抓取整站40万条房价数据(可更换抓取城市)
写在前面 这次的爬虫是关于房价信息的抓取,目的在于练习10万以上的数据处理及整站式抓取. 数据量的提升最直观的感觉便是对函数逻辑要求的提高,针对Python的特性,谨慎的选择数据结构.以往小数据量的抓取,即使函数逻辑部分重复,I/O请求频率密集,循环套嵌过深,也不过是1~2s的差别,而随着数据规模的提高,这1~2s的差别就有可能扩展成为1~2h. 因此对于要抓取数据量较多的网站,可以从两方面着手降低抓取信息的时间成本. 1)优化函数逻辑,选择适当的数据结构,符合Pythonic的编程习惯.例如,
-
python实现爬虫数据存到 MongoDB
在以上两篇文章中已经介绍到了 Python 爬虫和 MongoDB , 那么下面我就将爬虫爬下来的数据存到 MongoDB 中去,首先来介绍一下我们将要爬取的网站, readfree 网站,这个网站非常的好,我们只需要每天签到就可以免费下载三本书,良心网站,下面我就将该网站上的每日推荐书籍爬下来. 利用上面几篇文章介绍的方法,我们很容易的就可以在网页的源代码中寻找到书籍的姓名和书籍作者的信息. 找到之后我们复制 XPath ,然后进行提取即可.源代码如下所示 # coding=utf-8 imp
-
python中json格式数据输出的简单实现方法
主要使用json模块,直接导入import json即可. 小例子如下: #coding=UTF-8 import json info={} info["code"]=1 info["id"]=1900 info["name"]='张三' info["sex"]='男' list=[info,info,info] data={} data["code"]=1 data["id"]=190
-
使用Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. 先来简单介绍一下,网络爬虫的基本实现原理吧.一个爬虫首先要给它一个起点,所以需要精心选取一些URL作为起点,然后我们的爬虫从这些起点出发,抓取并解析所抓取到的页面,将所需要的信息提取出来,同时获得的新的URL插入到队列中作为下一次爬取的起点.这样不断地循环,一直到获得你想得到的所有的信息爬虫的任务
-
Python 爬虫多线程详解及实例代码
python是支持多线程的,主要是通过thread和threading这两个模块来实现的.thread模块是比较底层的模块,threading模块是对thread做了一些包装的,可以更加方便的使用. 虽然python的多线程受GIL限制,并不是真正的多线程,但是对于I/O密集型计算还是能明显提高效率,比如说爬虫. 下面用一个实例来验证多线程的效率.代码只涉及页面获取,并没有解析出来. # -*-coding:utf-8 -*- import urllib2, time import thread
-
Python操作Access数据库基本步骤分析
本文实例分析了Python操作Access数据库基本步骤.分享给大家供大家参考,具体如下: Python编程语言的出现,带给开发人员非常大的好处.我们可以利用这样一款功能强大的面向对象开源语言来轻松的实现许多特定功能需求.比如Python操作Access数据库的功能实现等等.在Python操作Access数据库之前,首先,你应安装了Python和Python for Windows extensions. 步骤之1.建立数据库连接 import win32com.client conn = wi
-
Python连接DB2数据库
在工作中遇到了这样的情况,项目中需要连接IBM的关系型数据库(DB2),关于这方面的库比较稀少,其中 ibm_db 是比较好用的一个库,网上也有教程,但是好像不准确,也不太详细,错误百出,没办法只能拿到后自己分析源码,总算搞定. 安装 环境需求: 首先是数据库DB2,下载连接直接百度,我下载是这两个文件: 只下载箭头所指即可,我还没在linux上做测试. 数据库API(这个东西找了好久,终于找到了合适的)(找不到搜:SQLAPI.zip) Python2.7 VCForPython2.7 ibm
-
Python 爬虫学习笔记之多线程爬虫
XPath 的安装以及使用 1 . XPath 的介绍 刚学过正则表达式,用的正顺手,现在就把正则表达式替换掉,使用 XPath,有人表示这太坑爹了,早知道刚上来就学习 XPath 多省事 啊.其实我个人认为学习一下正则表达式是大有益处的,之所以换成 XPath ,我个人认为是因为它定位更准确,使用更加便捷.可能有的人对 XPath 和正则表达式的区别不太清楚,举个例子来说吧,用正则表达式提取我们的内容,就好比说一个人想去天安门,地址的描述是左边有一个圆形建筑,右边是一个方形建筑,你去找吧,而使
-
python爬取NUS-WIDE数据库图片
实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需要一个小爬虫程序来爬取这些图片.在图片的下载过程中建议使用VPN.由于一些URL已经失效,所以会下载一些无效的图片. # PYTHON 2.7 Ubuntu 14.04 nuswide = "$NUS-WIDE-urls_ROOT" #the location of your nus-wi
-
python实现简单爬虫功能的示例
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度.好吧-!其实你很厉害的,右键查看页面源代码. 我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地.下面就看看如何使用python来实现这样一个功能. 一,获取整个页面数据 首先我们