使用python批量读取word文档并整理关键信息到excel表格的实例
目标
最近实验室里成立了一个计算机兴趣小组
倡议大家多把自己解决问题的经验记录并分享
就像在CSDN写博客一样
虽然刚刚起步
但考虑到后面此类经验记录的资料会越来越多
所以一开始就要做好模板设计(如下所示)
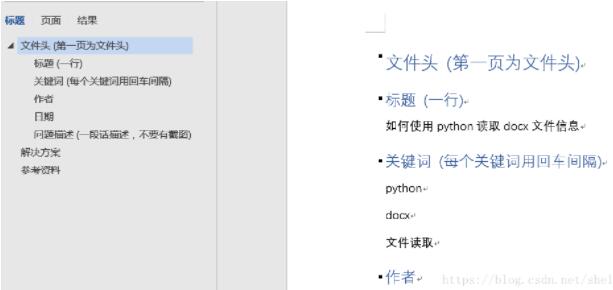
方便后面建立电子数据库
从而使得其他人可以迅速地搜索到相关记录
据说“人生苦短,我用python”
所以决定用python从docx文档中提取文件头的信息
然后把信息更新到一个xls电子表格中,像下面这样(直接po结果好了)
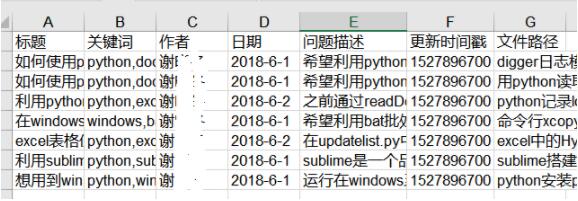
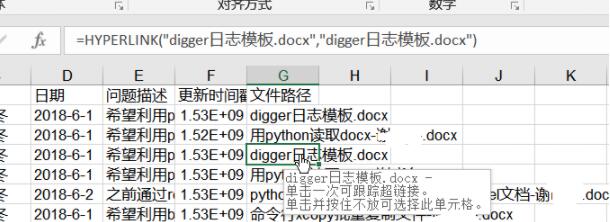
而且点击文件路径可以直接打开对应的文件(含超链接)
代码实现
1. 采集docx里面文件头信息
# -*- coding:utf-8 -*-
# 此程序可扫描Log中的docx文件并返回基本信息
import docx
from docx import Document
test_d = '../log/sublime搭建python的集成开发环境.docx'
def docxInfo(addr):
document = Document(addr)
info = {'title':[],
'keywords':[],
'author':[],
'date':[],
'question':[]}
lines = [0 for i in range(len(document.paragraphs))]
k = 0
for paragraph in document.paragraphs:
lines[k] = paragraph.text
k = k+1
index = [0 for i in range(5)]
k = 0
for line in lines:
if line.startswith('标题'):
index[0] = k
if line.startswith('关键词'):
index[1] = k
if line.startswith('作者'):
index[2] = k
if line.startswith('日期'):
index[3] = k
if line.startswith('问题描述'):
index[4] = k
k = k+1
info['title'] = lines[index[0]+1]
keywords = []
for line in lines[index[1]+1:index[2]]:
keywords.append(line)
info['keywords'] = keywords
info['author'] = lines[index[2]+1]
info['date'] = lines[index[3]+1]
info['question'] = lines[index[4]+1]
return info
if __name__ == '__main__':
print(docxInfo(test_d))
2. 遍历log文件夹,进行信息更新
# -*- coding:utf-8 -*-
# 此程序可以批量扫描log中的文件,如果碰到docx文档,
# 则调用readfile()提取文档信息,并将信息保存到digger
# 日志列表.xls之中,方便后期快速检索
import os,datetime
import time
import xlrd
from xlrd import xldate_as_tuple
import xlwt
from readfile import docxInfo
from xlutils.copy import copy
# 打开日志列表读取最近一条记录的更新日期
memo_d = '../log/digger日志列表.xls'
memo = xlrd.open_workbook(memo_d) #读取excel
sheet0 = memo.sheet_by_index(0) #读取第1张表
memo_date = sheet0.col_values(5) #读取第5列
memo_n = len(memo_date) #去掉标题
if memo_n>0:
xlsx_date = memo_date[memo_n-1] #读取最后一条记录的日期,
latest_date = sheet0.cell_value(memo_n-1,5)
# 返回时间戳
# 新建一个xlsx
memo_new = copy(memo)
sheet1 = memo_new.get_sheet(0)
# 重建超链接
hyperlinks = sheet0.col_values(6) # xlrd读取的也是text,造成超链接丢失
k = 1
n_hyperlink = len(hyperlinks)
for k in range(n_hyperlink):
link = 'HYPERLINK("%s";"%s")' %(hyperlinks[k],hyperlinks[k])
sheet1.write(k,6,xlwt.Formula(link))
k = k+1
# 判断文件后缀
def endWith(s,*endstring):
array = map(s.endswith,endstring)
if True in array:
return True
else:
return False
# 遍历log文件夹并进行查询
log_d = '../log'
logFiles = os.listdir(log_d)
for file in logFiles:
if endWith(file,'.docx'):
timestamp = os.path.getmtime(log_d+'/'+file)
if timestamp>latest_date:
info = docxInfo(log_d+'/'+file)
sheet1.write(memo_n,0,info['title'])
keywords_text = ','.join(info['keywords'])
sheet1.write(memo_n,1,keywords_text)
sheet1.write(memo_n,2,info['author'])
sheet1.write(memo_n,3,info['date'])
sheet1.write(memo_n,4,info['question'])
#获取当前时间
time_now = time.time() #浮点值,精确到毫秒
sheet1.write(memo_n,5, time_now)
link = 'HYPERLINK("%s";"%s")' %(file,file)
sheet1.write(memo_n,6,xlwt.Formula(link))
memo_n = memo_n+1
os.remove(memo_d)
memo_new.save(memo_d)
print('memo was updated!')
其实还有一些操作电子表格更好的模块,比如panda、xlsxwriter、openpyxl等。不过上述代码已经基本能实现功能,而且科研狗毕竟没那么多时间写代码做调试,所以后面有空再update吧!
致谢
在此过程中大量借鉴了CSDN论坛中各位大神的各种经验!!!
以上这篇使用python批量读取word文档并整理关键信息到excel表格的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

python读取word 中指定位置的表格及表格数据
1.Word文档如下: 2.代码 # -*- coding: UTF-8 -*- from docx import Document def readSpecTable(filename, specText): document = Document(filename) paragraphs = document.paragraphs allTables = document.tables specText = specText.encode('utf-8').decode('utf-8') f
-
Python读取word文本操作详解
本文研究的主要问题时Python读取word文本操作,分享了相关概念和实现代码,具体如下. 一,docx模块 Python可以利用python-docx模块处理word文档,处理方式是面向对象的.也就是说python-docx模块会把word文档,文档中的段落.文本.字体等都看做对象,对对象进行处理就是对word文档的内容处理. 二,相关概念 如果需要读取word文档中的文字(一般来说,程序也只需要认识word文档中的文字信息),需要先了解python-docx模块的几个概念. 1,Docume
-
python读取word文档,插入mysql数据库的示例代码
表格内容如下: 1.实现批量导入word文档,取文档标题中的数字作为编号 2.除取上面打钩的内容需要匹配出来入库入库,其他内容全部直接入库mysql # wuyanfeng # -*- coding:utf-8 -*- # 读取docx中的文本代码示例 import docx import pymysql import re import os # 创建数据库链接 conn = pymysql.connect( host='rm-bp1vu5d84dg12c6d59o.mysql.rds.ali
-
Python实现批量读取word中表格信息的方法
本文实例讲述了Python实现批量读取word中表格信息的方法.分享给大家供大家参考.具体如下: 单位收集了很多word格式的调查表,领导需要收集表单里的信息,我就把所有调查表放一个文件里,写了个python小程序把所需的信息打印出来 #coding:utf-8 import os import win32com from win32com.client import Dispatch, constants from docx import Document def parse_doc(f):
-
python读取word文档的方法
本文实例讲述了python读取word文档的方法.分享给大家供大家参考.具体如下: 首先下载安装win32com from win32com import client as wc word = wc.Dispatch('Word.Application') doc = word.Documents.Open('c:/test') doc.SaveAs('c:/test.text', 2) doc.Close() word.Quit() 这种方式产生的text文档,不能用python用普通的r方
-
Python读取Word(.docx)正文信息的方法
本文介绍用Python简单读取*.docx文件信息,一些python-word库就是对这种方法的扩展. 介绍分两部分: Word(*.docx)文件简述 Python提取Word信息 Word(*.docx)文件简述 大约在2008年以前,Office产品中Word用.doc文件格式,这种二进制格式很难与其他软件兼容. 为了跟上时代,微软采用类XML格式标准定义其新版Word文件.docx. .docx实际上是一个zip的压缩文件,比如我们有一个test.docx的文件: 其内容如下: 改变其后
-
使用python批量读取word文档并整理关键信息到excel表格的实例
目标 最近实验室里成立了一个计算机兴趣小组 倡议大家多把自己解决问题的经验记录并分享 就像在CSDN写博客一样 虽然刚刚起步 但考虑到后面此类经验记录的资料会越来越多 所以一开始就要做好模板设计(如下所示) 方便后面建立电子数据库 从而使得其他人可以迅速地搜索到相关记录 据说"人生苦短,我用python" 所以决定用python从docx文档中提取文件头的信息 然后把信息更新到一个xls电子表格中,像下面这样(直接po结果好了) 而且点击文件路径可以直接打开对应的文件(含超链接) 代码
-
Python批量对word文档进行操作步骤
目录 导读 应用 细节介绍 导读 前面几章我们以经介绍了怎么批量对excel和ppt操作今天我们说说对word文档的批量操作 应用 python-docx允许您创建新文档以及对现有文档进行更改.实际上,它只允许您对现有文档进行更改:只是如果您从一个没有任何内容的文档开始,一开始可能会觉得您是从头开始创建一个文档. 这个特性是一个强大的特性.文档的外观很大程度上取决于删除所有内容时留下的部分.样式.页眉和页脚等内容与主要内容分开包含,允许您在起始文档中进行大量自定义,然后出现在您生成的文档中. 让
-
Python快速优雅的批量修改Word文档样式
需求描述 手上现有若干份财务分析报告的Word文档,如下: 每一份Word文档中的内容如下: 为了方便后续审阅,需要将所有文档中所有含有资金的语句标红加粗,如图所示 步骤分析和前置知识 为了解决这个需求简单复习一下相关知识.Word文档一般而言由文档(document) - 段落(paragraph) - 文字块(run) 三级结构组成: 从需求反馈中可以看出,本质上我们需要做的就是对所有含有资金的文字块Run进行样式调整 因此,本需求的逻辑如下: 1.创建一个空文件夹(用于存放修改后的财务报告
-
Python 读取 Word 文档操作
目录 前言 Python 读取 Word 文档 安装 python-docx库 前言 Word 文档 (.docx) 是另一种主要用于存储文本的常见文档.它们通常由 Microsoft Office 创建和编辑,但也可以使用其他工具生成兼容文件.它们通常是共享可编辑文件的最常见格式,同时在分发文档时也非常常见. Python 读取 Word 文档 安装 python-docx库 在本节中,我们将学习如何使用 Python 从 Word 文档中提取文本信息.我们主要使用 python-docx 库
-
运用Python巧妙处理Word文档的方法详解
目录 工具 生成Word案例 读取操作word文档 总结 工具 python3.7 Pycharm Excel python-docx 生成Word案例 创建一个demo.doc文档,代码如下: from docx import Document from docx.shared import Cm,Pt from docx.document import Document as Doc #构建doc对象 document = Document() #操作文档标题 document.add_he
-
使用Python 自动生成 Word 文档的教程
当然要用第三方库啦 :) 使用以下命令安装: pip install python-docx 使用该库的基本步骤为: 1.建立一个文档对象(可自动使用默认模板建立,也可以使用已有文件). 2.设置文档的格式(默认字体.页面边距等). 3.在文档对象中加入段落文本.表格.图像等,并指定其样式. 4.保存文档. 注:本库仅支持生成Word2007以后版本的文档类型,即扩展名为.docx 的. 下面分步介绍其基本使用方法: 步骤一: from docx import Document doc = Do
-
php通过baihui网API实现读取word文档并展示
项目中遇到一个小问题,想实现php 如何读取word文档,并将其内容原样显示 可以 使用API 可以看看baihui.com 的写写应用 的API 申请一个 APPKEY 就能使用,你可以看看 ... 对免费版本有限制 比如 excel 支持,可以参考我这个 appkey是我申请的,可以使用吧 ... 保存成本地的一个html文件 打开后直接使用 word 的类似 <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN&q
-
PHP读取word文档的方法分析【基于COM组件】
本文实例讲述了PHP读取word文档的方法.分享给大家供大家参考,具体如下: php开发 过程中可能会word文档的读取问题,这里可以利用com组件来完成此项操作 一.先开启php.ini的COM,操作如下 1. extension=php_com_dotnet.dll 2. com.allow_dcom = true 二.开启之后就可以试下如下操作 1.建立一个指向新COM组件的索引 $word = new COM("word.application") or die("C