Python3.5 Pandas模块之DataFrame用法实例分析
本文实例讲述了Python3.5 Pandas模块之DataFrame用法。分享给大家供大家参考,具体如下:
1、DataFrame的创建
(1)通过二维数组方式创建
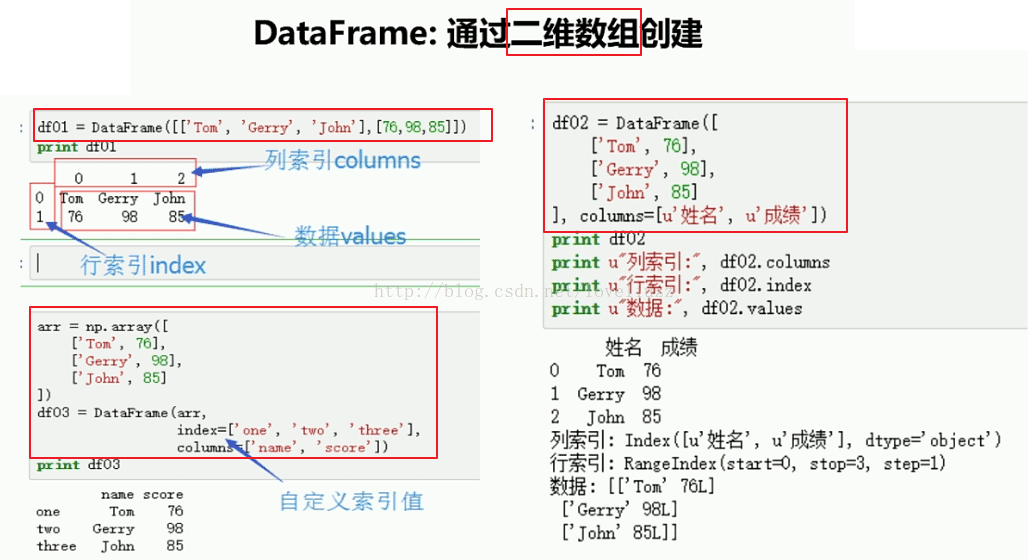
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#1.DataFrame通过二维数组创建
print("======DataFrame直接通过二维数组创建======")
d1 = DataFrame([["a","b","c","d"],[1,2,3,4]])
print(d1)
print("======DataFrame借助array二维数组创建======")
arr = np.array([
["jack",78],
["lili",86],
["amy",97],
["tom",100]
])
d2 = DataFrame(arr,index=["01","02","03","04"],columns=["姓名","成绩"])
print(d2)
print("========打印行索引========")
print(d2.index)
print("========打印列索引========")
print(d2.columns)
print("========打印值========")
print(d2.values)
运行结果:
======DataFrame直接通过二维数组创建======
0 1 2 3
0 a b c d
1 1 2 3 4
======DataFrame借助array二维数组创建======
姓名 成绩
01 jack 78
02 lili 86
03 amy 97
04 tom 100
========打印行索引========
Index(['01', '02', '03', '04'], dtype='object')
========打印列索引========
Index(['姓名', '成绩'], dtype='object')
========打印值========
[['jack' '78']
['lili' '86']
['amy' '97']
['tom' '100']]
(2)通过字典方式创建
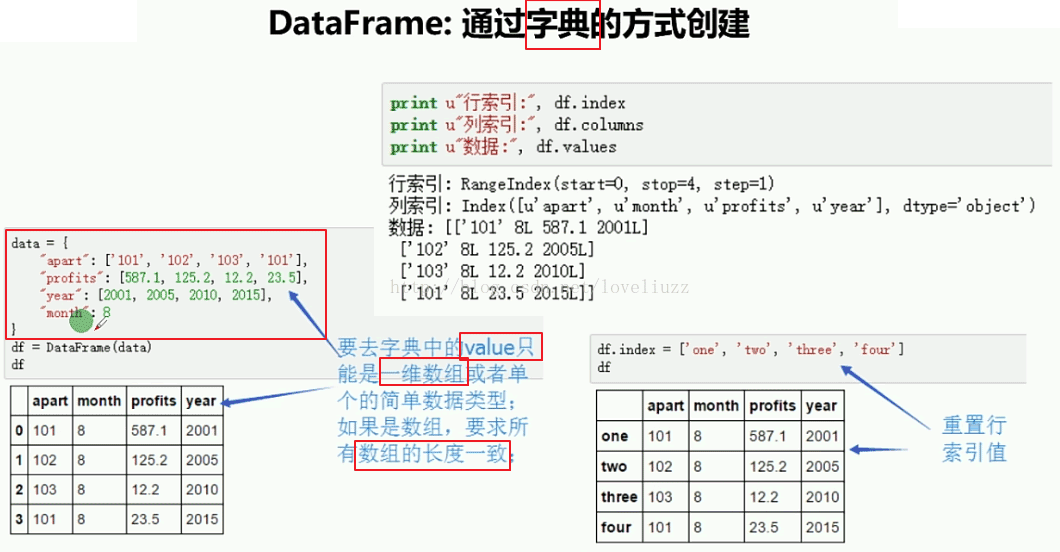
#2.DataFrame通过字典创建,键作为列索引,键值作为数据值,行索引值自动生成
data = {
"apart":['1101',"1102","1103","1104"],
"profit":[2000,4000,5000,3500],
"month":8
}
d3 = DataFrame(data)
print(d3)
print("========行索引========")
print(d3.index)
print("========列索引========")
print(d3.columns)
print("========数据值========")
print(d3.values)
运行结果:
apart month profit
0 1101 8 2000
1 1102 8 4000
2 1103 8 5000
3 1104 8 3500
========行索引========
RangeIndex(start=0, stop=4, step=1)
========列索引========
Index(['apart', 'month', 'profit'], dtype='object')
========数据值========
[['1101' 8 2000]
['1102' 8 4000]
['1103' 8 5000]
['1104' 8 3500]]
2、DataFrame数据获取


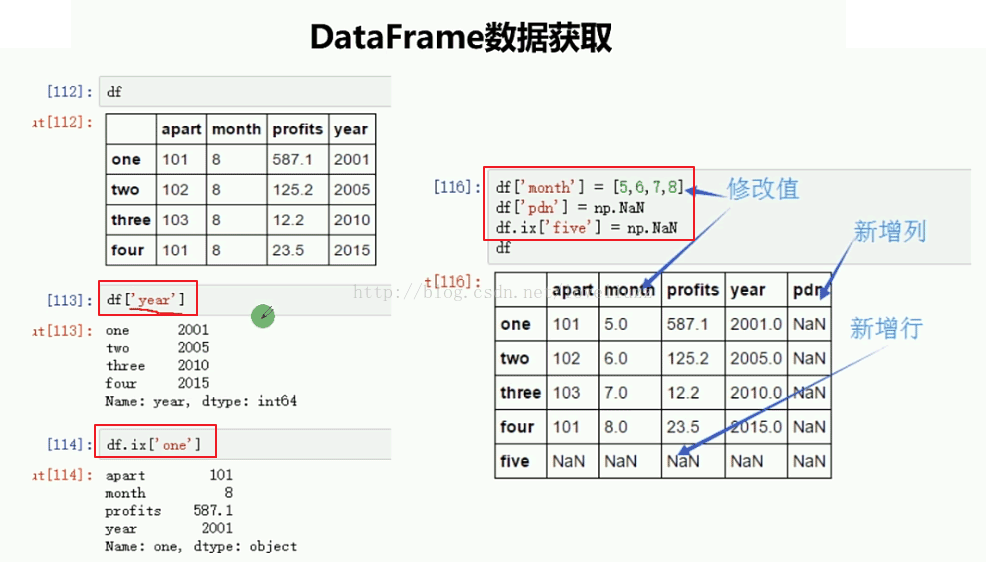
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#3.DataFrame获取数据
data = {
"apart":['1101',"1102","1103","1104"],
"profit":[2000,4000,5000,3500],
"month":8
}
d3 = DataFrame(data)
print(d3)
print("======获取一列数据======")
print(d3["apart"])
print("======获取一行数据======")
print(d3.ix[1])
print("======修改数据值======")
d3["month"] = [7,8,9,10] #修改值
d3["year"] = [2001,2001,2003,2004] #新增列
d3.ix["4"] = np.NaN
print(d3)
运行结果:
apart month profit
0 1101 8 2000
1 1102 8 4000
2 1103 8 5000
3 1104 8 3500
======获取一列数据======
0 1101
1 1102
2 1103
3 1104
Name: apart, dtype: object
======获取一行数据======
apart 1102
month 8
profit 4000
Name: 1, dtype: object
======修改数据值======
apart month profit year
0 1101 7.0 2000.0 2001.0
1 1102 8.0 4000.0 2001.0
2 1103 9.0 5000.0 2003.0
3 1104 10.0 3500.0 2004.0
4 NaN NaN NaN NaN
3、pandas基本功能

(1)pandas数据文件读取
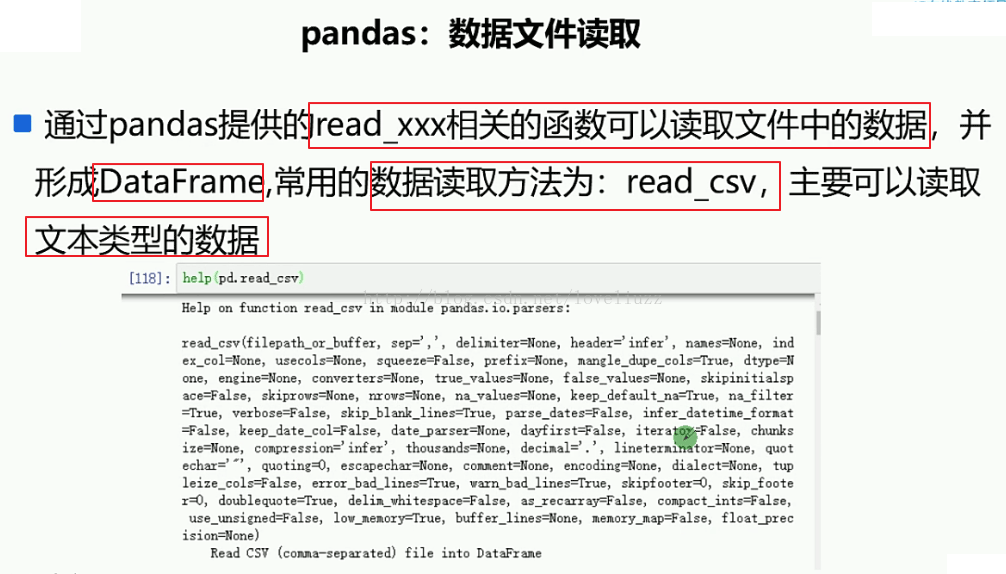
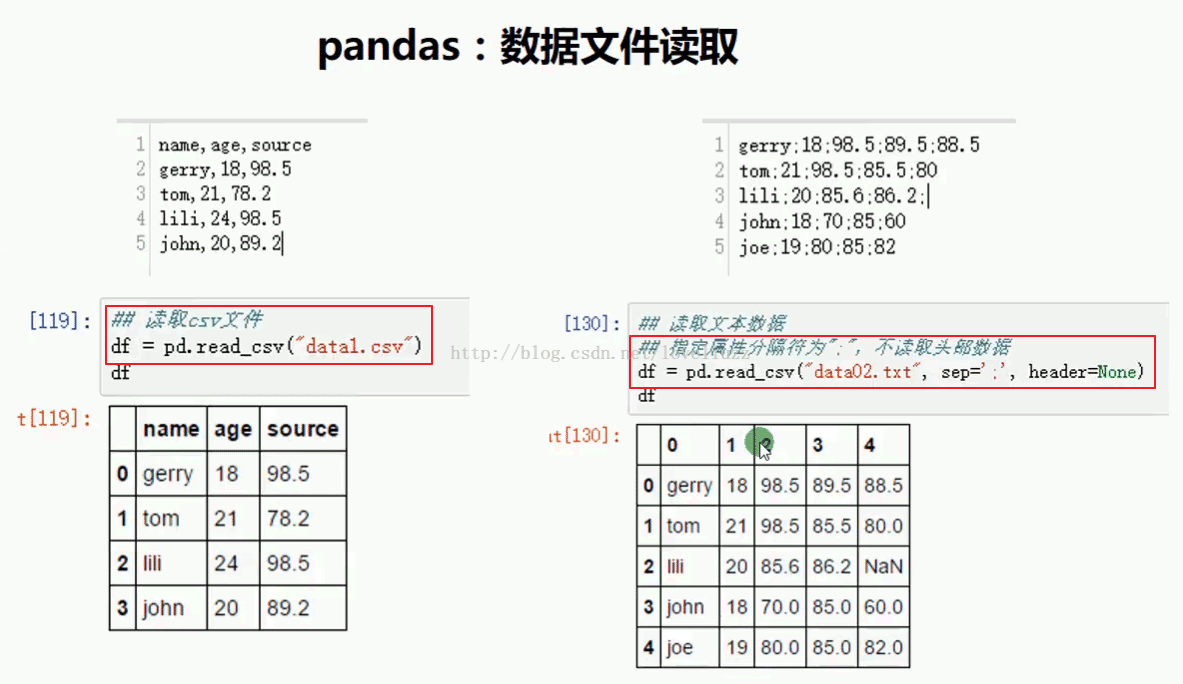
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#pandas基本操作
#1.数据文件读取
df = pd.read_csv("data.csv")
print(df)
运行结果:
name age source
0 gerry 18 98.5
1 tom 21 78.2
2 lili 24 98.5
3 john 20 89.2
(2)数据过滤获取
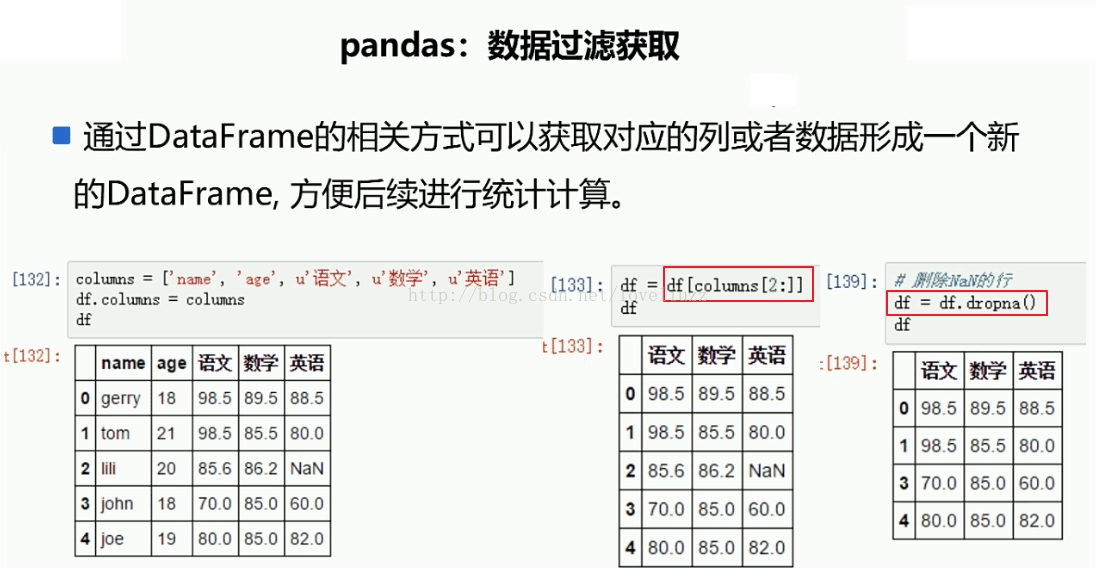
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#pandas基本操作
#1.数据文件读取
df = pd.read_csv("data.csv")
print(df)
#2.数据过滤获取
columns = ["姓名","年龄","成绩"]
df.columns = columns #更改列索引
print("=======更改列索引========")
print(df)
#获取几列的值
df1 = df[columns[1:]]
print("=======获取几列的值========")
print(df1)
print("=======获取几行的值========")
print(df.ix[1:3])
#删除含有NaN值的行
df2 = df1.dropna()
print("=======删除含有NaN值的行=======")
print(df2)
运行结果:
name age source
0 gerry 18 98.5
1 tom 21 NaN
2 lili 24 98.5
3 john 20 89.2
=======更改列索引========
姓名 年龄 成绩
0 gerry 18 98.5
1 tom 21 NaN
2 lili 24 98.5
3 john 20 89.2
=======获取几列的值========
年龄 成绩
0 18 98.5
1 21 NaN
2 24 98.5
3 20 89.2
=======获取几行的值========
姓名 年龄 成绩
1 tom 21 NaN
2 lili 24 98.5
3 john 20 89.2
=======删除含有NaN值的行=======
年龄 成绩
0 18 98.5
2 24 98.5
3 20 89.2
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数学运算技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-
python3 pandas 读取MySQL数据和插入的实例
python 代码如下: # -*- coding:utf-8 -*- import pandas as pd import pymysql import sys from sqlalchemy import create_engine def read_mysql_and_insert(): try: conn = pymysql.connect(host='localhost',user='user1',password='123456',db='test',charset='utf8')
-
Python3.5 Pandas模块缺失值处理和层次索引实例详解
本文实例讲述了Python3.5 Pandas模块缺失值处理和层次索引.分享给大家供大家参考,具体如下: 1.pandas缺失值处理 import numpy as np import pandas as pd from pandas import Series,DataFrame df3 = DataFrame([ ["Tom",np.nan,456.67,"M"], ["Merry",34,345.56,np.nan], [np.nan,np
-
Python3 pandas 操作列表实例详解
1.首先需要安装pandas, 安装的时候可能由依赖的包需要安装,根据运行时候的提示,缺少哪个库,就pip 安装哪个库. 2.示例代码 import pandas as pd from pandas import ExcelWriter EX_PATH = "E:\\code\\test2.xlsx" #读取excel里面的内容 data = pd.read_excel(EX_PATH,sheet_name='Sheet1') #新增加一列内容 lista = [21, 21, 20,
-
Python3.5 Pandas模块之Series用法实例分析
本文实例讲述了Python3.5 Pandas模块之Series用法.分享给大家供大家参考,具体如下: 1.Pandas模块引入与基本数据结构 2.Series的创建 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu #模块引入 import numpy as np import pandas as pd from pandas import Series,DataFrame #1.Series通过numpy一
-
详解Python3 pandas.merge用法
摘要 数据分析与建模的时候大部分时间在数据准备上,包括对数据的加载.清理.转换以及重塑.pandas提供了一组高级的.灵活的.高效的核心函数,能够轻松的将数据规整化.这节主要对pandas合并数据集的merge函数进行详解.(用过SQL或其他关系型数据库的可能会对这个方法比较熟悉.)码字不易,喜欢请点赞!!! 1.merge函数的参数一览表 2.创建两个DataFrame 3.pd.merge()方法设置连接字段. 默认参数how是inner内连接,并且会按照相同的字段key进行合并,即等价于o
-
python3使用pandas获取股票数据的方法
如下所示: from pandas_datareader import data, wb from datetime import datetime import matplotlib.pyplot as plt end = datetime.now() start = datetime(end.year - 1, end.month, end.day) alibaba = data.DataReader('BABA', 'yahoo', start, end) alibaba['Adj Clo
-
Python3使用pandas模块读写excel操作示例
本文实例讲述了Python3使用pandas模块读写excel操作.分享给大家供大家参考,具体如下: 前言 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,能使我们快速便捷地处理数据.本文介绍如何用pandas读写excel. 1. 读取excel 读取excel主要通过read_excel函数实现,除了pandas
-
Python3.5 Pandas模块之DataFrame用法实例分析
本文实例讲述了Python3.5 Pandas模块之DataFrame用法.分享给大家供大家参考,具体如下: 1.DataFrame的创建 (1)通过二维数组方式创建 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu import numpy as np import pandas as pd from pandas import Series,DataFrame #1.DataFrame通过二维数组创建 pr
-
Python中threading模块join函数用法实例分析
本文实例讲述了Python中threading模块join函数用法.分享给大家供大家参考.具体分析如下: join的作用是众所周知的,阻塞进程直到线程执行完毕.通用的做法是我们启动一批线程,最后join这些线程结束,例如: for i in range(10): t = ThreadTest(i) thread_arr.append(t) for i in range(10): thread_arr[i].start() for i in range(10): thread_arr[i].joi
-

Python XlsxWriter模块Chart类用法实例分析
本文实例讲述了Python XlsxWriter模块Chart类用法.分享给大家供大家参考,具体如下: 一 点睛 Chart类是XlsxWriter模块中图表组件的基类,支持的图表类型包括面积.条形图.柱形图.折线图.饼图.散点图.股票和雷达等,一个图表对象是通过Workbook(工作簿)的add_chart方法创建,通过 {type,'图表类型'}字典参数指定图表的类型,语句如下: chart = workbook.add_chart({type, 'column'}) #创建一个column
-
python argparse模块传参用法实例
目录 前言 传入一个参数 操作args字典 传入多个参数 改变数据类型 位置参数 可选参数 默认值 必需参数 前言 argsparse是python的命令行解析的标准模块,内置于python,不需要安装.这个库可以让我们直接在命令行中就可以向程序中传入参数并让程序运行. 港真的,今天是我第一次学习argsparse.因为用不到,自然也就没有学习的动力.但是现在电脑有点卡,每次打开pycharm太卡了,逼得我不得不开始使用命令行来测试代码. 传入一个参数 我们先在桌面新建“arg学习”的文件夹,在
-
Python iter()函数用法实例分析
本文实例讲述了Python iter()函数用法.分享给大家供大家参考,具体如下: python中的迭代器用起来非常灵巧,不仅可以迭代序列,也可以迭代表现出序列行为的对象,例如字典的键.一个文件的行,等等. 迭代器就是有一个next()方法的对象,而不是通过索引来计数.当使用一个循环机制需要下一个项时,调用迭代器的next()方法,迭代完后引发一个StopIteration异常. 但是迭代器只能向后移动.不能回到开始.再次迭代只能创建另一个新的迭代对象. 反序迭代工具:reversed()将返回
-
Python callable()函数用法实例分析
本文实例讲述了Python callable()函数用法.分享给大家供大家参考,具体如下: python中的内建函数callable( ) ,可以检查一个对象是否是可调用的 . 对于函数, 方法, lambda 函数式, 类, 以及实现了 _ _call_ _ 方法的类实例, 它都返回 True. >>> help(callable) Help on built-in function callable in module __builtin__: callable(...) calla
-
Python lambda函数基本用法实例分析
本文实例讲述了Python lambda函数基本用法.分享给大家供大家参考,具体如下: 这里我们简单学习一下python lambda函数. 首先,看一下python lambda函数的语法,如下: f=lambda [parameter1,parameter2,--]:expression lambda语句中,冒号前是参数,可以有0个或多个,用逗号隔开,冒号右边是返回值.lambda语句构建的其实是一个函数对象. 1>无参数 f=lambda :'python lambda!' >>&