Hadoop的安装与环境搭建教程图解
一、Hadoop的安装
1. 下载地址:https://archive.apache.org/dist/hadoop/common/我下载的是hadoop-2.7.3.tar.gz版本。
2. 在/usr/local/ 创建文件夹zookeeper
mkdir hadoop

3.上传文件到Linux上的/usr/local/source目录下

3.解压缩
运行如下命令:
tar -zxvf hadoop-2.7.3.tar.gz-C /usr/local/hadoop

4. 修改配置文件
进入到cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop/ , 修改hadoop-env.sh

运行 vimhadoop-env.sh,修改JAVA_HOME

5.将Hadoop的执行命令加入到我们的环境变量里
在/etc/profile文件中加入:
export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin
执行/etc/profile文件:
source /etc/profile
6. 将npfdev1机器上的hadoop复制到npfdev2和npfdev3和npfdev4机器上。使用下面的命令:
首先分别在npfdev2和npfdev3和npfdev4机器上,建立/usr/local/hadoop目录,然后在npfdev1上分别执行下面命令:
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev2:/usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev3:/usr/local/hadoop/
scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev4:/usr/local/hadoop/
记住:需要各自修改npfdev2和npfdev3和npfdev4的/etc/profile文件:
在/etc/profile文件中加入:
export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin
执行/etc/profile文件:
source /etc/profile
然后分别在npfdev1和npfdev2和npfdev3和npfdev4机器上,执行hadoop命令,看是否安装成功。并且关闭防火墙。

7. 确定所有机器之间可以相互ping通,使用下面的命令:
(1). ping npfdev1

(2). ping npfdev2

(3). ping npfdev3

(4). ping npfdev4

8. 启动hadoop:
我们这里将npfdev1作为master,npfdev2和npfdev3和npfdev4分别作为三台slave。
(1).修改配置文件core-site.xml
进入 cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop
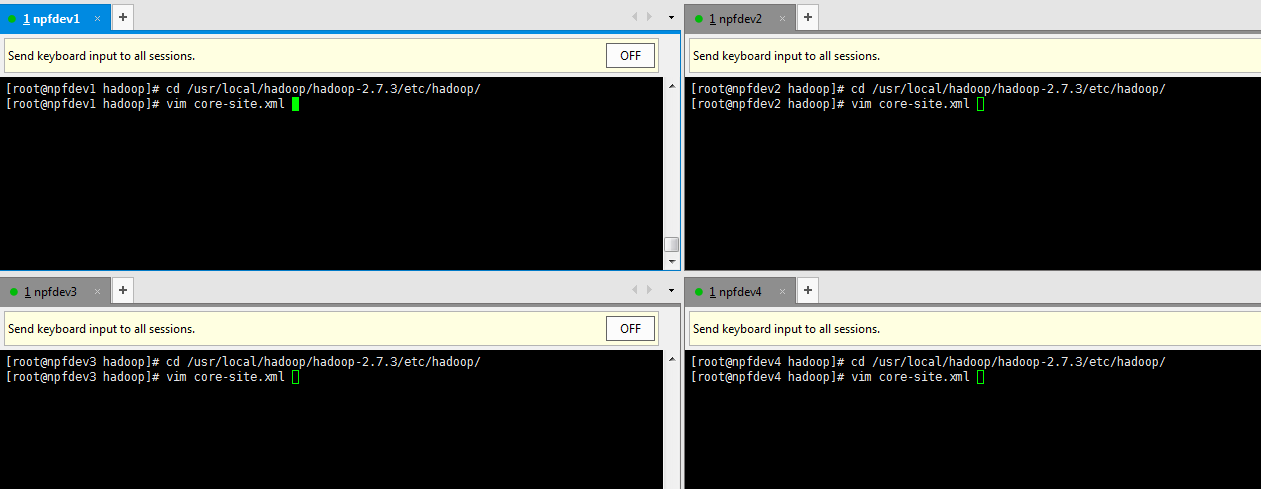
具体配置如下:
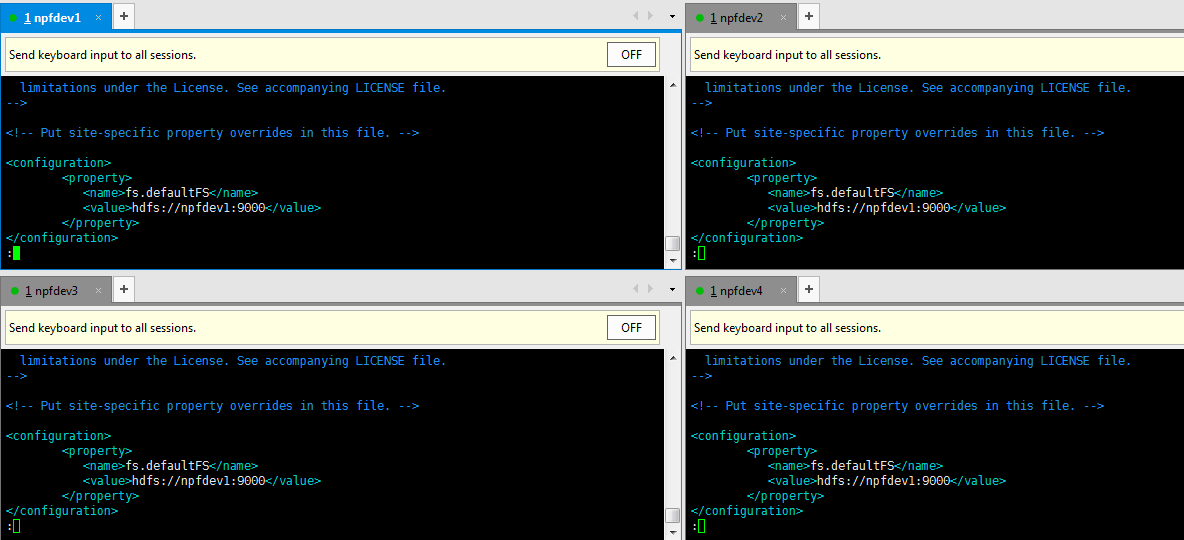
(2).在master机器npfdev1上启动namenode
首先需要格式化namenode,第一次使用需要格式化,后来就不需要了。
hdfs namenode -format

然后启动namenode:
hadoop-daemon.sh start namenode
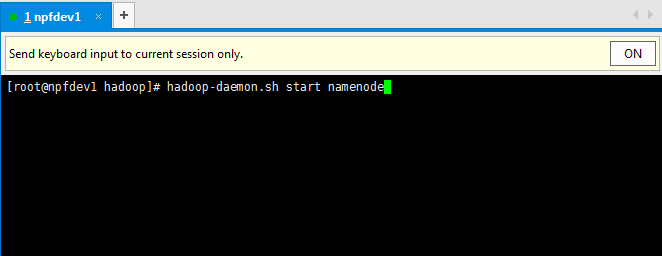
通过jps命令查看,如果有namenode的java进程,就说明我们启动namenode成功。

(3).在slave机器npfdev2,npfdev3,npfdev4上启动datanode

总结
以上所述是小编给大家介绍的Hadoop的安装与环境搭建教程图解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

详解Ubuntu16.04下Hadoop 2.7.3的安装与配置
一.Java环境搭建 (1)下载JDK并解压(当前操作系统为Ubuntu16.04,jdk版本为jdk-8u111-Linux-x64.tar.gz) 新建/usr/java目录,切换到jdk-8u111-linux-x64.tar.gz所在目录,将这个文件解压缩到/usr/java目录下. tar -zxvf jdk-8u101-linux-x64.tar.gz -C /usr/java/ (2)设置环境变量 修改.bashrc,在最后一行写入下列内容. sudo vim ~/.bashrc
-
windows 32位eclipse远程hadoop开发环境搭建
本文假设hadoop环境在远程机器(如linux服务器上),hadoop版本为2.5.2 注:本文eclipse/intellij idea 远程调试hadoop 2.6.0主要参考了并在其基础上有所调整 由于我喜欢在win7 64位上安装32位的软件,比如32位jdk,32位eclipse,所以虽然本文中的操作系统是win7 64位,但是所有的软件都是32位的. 软件版本: 操作系统:win7 64位 eclipse: eclipse-jee-mars-2-win32 java: 1.8.0_
-
在Hadoop集群环境中为MySQL安装配置Sqoop的教程
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中. Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS. 一.安装sqoop 1.下载sqoop压缩包,并解压 压缩包分别是:sqoop-1.2.0-CDH3B4.tar.gz,hadoop-0.20.2-C
-
Linux中安装配置hadoop集群详细步骤
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本.(前边主要介绍单机版的配置,集群版是在单机版的基础上,主要是配置文件有所不同,后边会有详细说明) 二. 准备工作 2.1 创建用户 创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好. sudo adduser hadoop sudo vim /etc/sudoers
-
Hadoop2.X/YARN环境搭建--CentOS7.0 JDK配置
Hadoop是Java写的,他无法使用Linux预安装的OpenJDK,因此安装hadoop前需要先安装JDK(1.6以上) 原材料:在Oracle官网下载的32位JDK: 说明: 1.CentOS 7.0系统现在只有64位的,但是,Hadoop一般支持32位的,在64位环境下有事会有Warning出现,避免真的有神马问题,选择i586的JDK(即32位的),当然,64位的CentOS 7 肯定是兼容32位JDK的,记住:64位系统肯定兼容32位的软件,32位系统不能兼容64位软件.64位只是说
-
hadoop 单机安装配置教程
单机安装主要用于程序逻辑调试.安装步骤基本通分布式安装,包括环境变量,主要Hadoop配置文件,SSH配置等.主要的区别在于配置文件:slaves配置需要修改,另外如果分布式安装中dfs.replication大于1,需要修改为1,因为只有1个datanode. 分布式安装请参考: http://acooly.iteye.com/blog/1179828 单机安装中,使用一台机器,即做namenode和JobTracker也是datanode和TaskTracker,当然也是SecondaryN
-
Hadoop2.X/YARN环境搭建--CentOS7.0系统配置
一.我缘何选择CentOS7.0 14年7月7日17:39:42发布了CentOS 7.0.1406正式版,我曾使用过多款Linux,对于Hadoop2.X/YARN的环境配置缘何选择CentOS7.0,其原因有: 1.界面采用RHEL7.0新的GNOME界面风,这可不是CentOS6.5/RHEL6.5所能比的!(当然,Fedora早就采用这种风格的了,但是现在的Fedora缺包已然不成样子了) 2.曾经,我也用了RHEL7.0,它最大的问题就是YUM没法用,而且总会有Warning提示注册购
-
Hadoop单机版和全分布式(集群)安装
Hadoop,分布式的大数据存储和计算, 免费开源!有Linux基础的同学安装起来比较顺风顺水,写几个配置文件就可以启动了,本人菜鸟,所以写的比较详细.为了方便,本人使用三台的虚拟机系统是Ubuntu-12.设置虚拟机的网络连接使用桥接方式,这样在一个局域网方便调试.单机和集群安装相差不多,先说单机然后补充集群的几点配置. 第一步,先安装工具软件编辑器:vim 复制代码 代码如下: sudo apt-get install vim ssh服务器: openssh,先安装ssh是为了使用远程终端工
-
Hadoop的安装与环境搭建教程图解
一.Hadoop的安装 1. 下载地址:https://archive.apache.org/dist/hadoop/common/我下载的是hadoop-2.7.3.tar.gz版本. 2. 在/usr/local/ 创建文件夹zookeeper mkdir hadoop 3.上传文件到Linux上的/usr/local/source目录下 3.解压缩 运行如下命令: tar -zxvf hadoop-2.7.3.tar.gz-C /usr/local/hadoop 4. 修改配置文件 进入到
-
Python从入门到精通之环境搭建教程图解
本章内容: 一.下载python安装包 下载地址:https://www.python.org/downloads/ 二.选择适合自己系统的文件,进行下载 Windows环境安装(Windows 10) 三.Python解释器的安装 双击python-3.7.4-amd64.exe文件,勾选Add Python 3.7 to PATH,点击自定义安装 点击Next 选择自定义路径,点击Install即可 安装成功 右键此电脑属性,查看环境变量是否配置 选择环境变量,查看path 查看python
-
selenium3+python3环境搭建教程图解
1.首先安装火狐浏览器 有单独文章分享怎么安装 2.搭建python环境 安装python,安装的时候把path选好,就不用自己在配置,安装方法有单独文档分享 安装好以后cmd打开输入python查看是否配置好 3.安装pip 一般python会默认带一个,放置和python一个地址,这样就不需要重新配置环境变量 安装路径可以上网查询很多的教程 https://pypi.python.org/pypi/pip 下载pip源码包 减压以后在cmd 窗口下用cd命令切换到 E:\新建文件夹 (2)\
-
win10下VSCode+CMake+Clang+GCC环境搭建教程图解
打算用C/C++把基本的数据结构与算法实现一遍, 为考研做准备, 因为只是想实现算法和数据结构, 就不太想用VisualStudio, 感觉VSCode不错, 遂在网上找了一些教程, 结合自己的需求, 配置一下开发环境. 安装软件 CMake CMake是一个跨平台的自动化建构系统,它使用一个名为 CMakeLists.txt 的文件来描述构建过程; 官网下载安装, 傻瓜式操作; 记得把安装目录下的bin文件添加到系统环境变量, 这个可以在安装的时候勾选, 勾选了就不用自己添加了; 检测是否安装
-
wind10 idea中 go 开发环境搭建教程图解
1.下载安装包: 国内的: https://studygolang.com/ 这里使用的的是第一种https://studygolang.com/ 下载后解压到本地 目录结构: 配置环境变量 path中配置到bin 上面只要是弄过开发都应该可以搞定. 然后任意shell环境监察配置是否成功 go env go version 输出如下说明go安装配置成功. idea中的设置 file->plugins->在搜索框搜索go 插件 前两步可能收不到 往下看 添加 源 https://plugins
-
Windows下MongoDB的下载安装、环境配置教程图解
下载MongoDB 1.进入MongoDB官网,Products -> 选择SOFTWARE下的MongoDB Server 2.选择下载最新版 3.选择对应的版本下载 msi安装包形式安装MongoDB 1.选择complete,完整安装(安装全部组件).complete,完整的.完全的. 当然也可以选自定义安装,影响不大. 2. data目录是数据存储目录,数据库中的数据就存储在这个目录中.log是日志文件的输出目录. 需要在该盘的根目录下新建一个data文件夹(必须要是MongoDB安装盘
-
基于 ZooKeeper 搭建 Hadoop 高可用集群 的教程图解
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求比 YARN ResourceManger 高得多,所以它的实现也更加复杂,故下面先进行讲解: 1.1 高可用整体架构 HDFS 高可用架构如下: 图片引用自: https://www.edureka.co/blog/how-to-set-up-hadoop-cluster-with-hdfs-hi
-
windows server 2008/2012安装php iis7 mysql环境搭建教程
windows server 2008/2012安装php iis7 mysql环境搭建教程,具体内容如下 1.安装IIS windows server 2008的IIS版本为7.0,包括fastcgi,安装十分方便. 打开"开始"菜单→"服务器管理",出现服务器管理界面(图1) 图1 - 服务器管理 滚动条下翻,或者点击主菜单的"角色",然后点击"添加角色",出现向导页面后点击下一步,选择"web服务器(IIS)&
-
IDEA快速搭建Java开发环境的教程图解
作为IntelliJ IDEA mac新手,IDEA如何快速搭建Java开发环境呢? 今天小编就给大家带来了IntelliJ IDEA mac使用教程,想知道IDEA如何快速搭建Java开发环境?那就一起来看看吧! 全局JDK(默认配置) 具体步骤:顶部工具栏 File ->Other Settins -> Default Project Structure -> SDKs -> JDK 示例: 根据下图步骤设置JDK目录,最后点击OK保存. 注:SDKs全称是Software D
-
java环境搭建教程
网上关于java环境搭建的文章很多,有正确的也有错误的,有原创的也有拷贝的,还有一些过时的. 今天正好有时间,简单对java环境变量的配置作了总结,并加了一些说明,希望可以帮助一些新手朋友. 1.首先要搞明白什么是JVM.JRE.JDK 我见过一些工作过一两年的程序员解释不清楚这三个概念,简单的解释下, JVM:java虚拟机 JRE:java运行环境 简单点说 JRE = java虚拟机+核心类库(辅助java虚拟机运行的文件) JDK:java开发工具集合 也可以理解为 JDK = JR