windows7 32、64位下python爬虫框架scrapy环境的搭建方法
适用于python 2.7 64位安装
一、操作系统:WIN7 64位
二、python版本:2.7 64位(scrapy目前不支持3.x)
不确定位数的,看图

三、安装相关软件(可以从我的百度网盘下载:链接: https://pan.baidu.com/s/1MzHNALJcRePSoaEqBQvGAQ 提取码: xd5e )
我配置环境的时候是直接pip install scrapy安装的,但是在过程中出现一些错误,发现是由于以下软件安装失败导致的。所以请先安装这4个相关软件再安装scrapy。
一定要注意看看,你的python是不是64位的,位数一样才可以哈。否则要报错滴。
- pywin32-218.win-amd64-py2.7.exe 下载网站: https://sourceforge.net/projects/pywin32/files/pywin32/
- pyOpenSSL-0.13.1.win-amd64-py2.7.exe 官方主页:http://pypi.python.org/pypi/pyOpenSSL
- lxml-3.6.4-cp27-cp27m-win_amd64.whl 下载网站: http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
- VCForPython27.msi
安装验证:cmd进入python控制中心,注意大小写敏感
import win32com import OpenSSL import lxml
如果没有报错,证明安装成功
四、安装scrapy:
使用pip命令
pip install scrapy
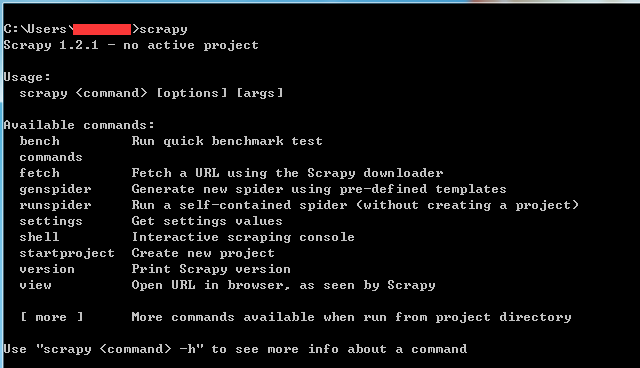
验证安装:cmd输入scrapy
scrapy
如果没有报错,如下图。证明安装成功
32位win7的安装过程和上述类似,只是文件不同。
相关推荐
-
详解Python网络框架Django和Scrapy安装指南
Windows 上的Django安装 如今Python使用的范围越来越广,所以学会关于它比较火的网络框架非常有必要.要安装Django,首先要知道你电脑上的python是哪个版本的,至于如何安装python的解释器环境此处不做介绍,网上的教程很多. Django 是一个 Python Web 框架,因此需要在您的机器上安装 Python.本文是基于Python3.6的环境安装介绍的. 要查看你电脑上的python版本,使用以下指令: python --version 要安装django,还要安装
-

Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文实例讲述了Python3爬虫爬取英雄联盟高清桌面壁纸功能.分享给大家供大家参考,具体如下: 使用Scrapy爬虫抓取英雄联盟高清桌面壁纸 源码地址:https://github.com/snowyme/loldesk 开始项目前需要安装python3和Scrapy,不会的自行百度,这里就不具体介绍了 首先,创建项目 scrapy startproject loldesk 生成项目的目录结构 首先需要定义抓取元素,在item.py中,我们这个项目用到了图片名和链接 import scrapy
-
Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例
本文实例讲述了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能.分享给大家供大家参考,具体如下: 一.背景: 小编在爬虫的时候肯定会遇到被封杀的情况,昨天爬了一个网站,刚开始是可以了,在settings的设置DEFAULT_REQUEST_HEADERS伪装自己是chrome浏览器,刚开始是可以的,紧接着就被对方服务器封杀了. 代理: 代理,代理,一直觉得爬去网页把爬去速度放慢一点就能基本避免被封杀,虽然可以使用selenium,但是这个坎必须
-
windows下搭建python scrapy爬虫框架步骤
网络上现有的windows下搭建scrapy教程都比较旧,一般都是咔咔咔安装一堆软件,太麻烦,这是因为scrapy框架用到好多不同的模块,其实查阅最新的官网scrapy文档,在windows下搭建scrapy框架,官方文档是建议使用集成包的,以免安装太过复杂而出现问题,首先百度scrapy,就可以找到scrapy的官方文档 1.找到windows下的框架安装的文档教程,这里建议我们安装Anaconda或者Miniconda集成包,下面我选择安装Miniconda安装包来安装scrapy框架 2.
-
Python爬虫框架Scrapy实例代码
目标任务:爬取腾讯社招信息,需要爬取的内容为:职位名称,职位的详情链接,职位类别,招聘人数,工作地点,发布时间. 一.创建Scrapy项目 scrapy startproject Tencent 命令执行后,会创建一个Tencent文件夹,结构如下 二.编写item文件,根据需要爬取的内容定义爬取字段 # -*- coding: utf-8 -*- import scrapy class TencentItem(scrapy.Item): # 职位名 positionname = scrapy.
-
Scrapy框架爬取Boss直聘网Python职位信息的源码
分析 使用CrawlSpider结合LinkExtractor和Rule爬取网页信息 LinkExtractor用于定义链接提取规则,一般使用allow参数即可 LinkExtractor(allow=(), # 使用正则定义提取规则 deny=(), # 排除规则 allow_domains=(), # 限定域名范围 deny_domains=(), # 排除域名范围 restrict_xpaths=(), # 使用xpath定义提取队则 tags=('a', 'area'), attrs=(
-
图文详解python安装Scrapy框架步骤
python书写爬虫的一个框架,它也提供了多种类型爬虫的基类,scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 首先要先安装python 安装完成以后,配置一下环境变量. 还需要安装一些组件pywin32,百度搜索下载安装 pywin32安装完成还要安转pip,百度搜索pip下载下来,解压通过cmd命令进行安装 我查看一下pip是否安装成功 执行pip install Scrapy进行安装Scrapy 测试一下Scrapy框架是否安装成功,不报错就说明安装成功了
-
windows7 32、64位下python爬虫框架scrapy环境的搭建方法
适用于python 2.7 64位安装 一.操作系统:WIN7 64位 二.python版本:2.7 64位(scrapy目前不支持3.x) 不确定位数的,看图 三.安装相关软件(可以从我的百度网盘下载:链接: https://pan.baidu.com/s/1MzHNALJcRePSoaEqBQvGAQ 提取码: xd5e ) 我配置环境的时候是直接pip install scrapy安装的,但是在过程中出现一些错误,发现是由于以下软件安装失败导致的.所以请先安装这4个相关软件再安装scrap
-
Python爬虫框架Scrapy实战之批量抓取招聘信息
网络爬虫抓取特定网站网页的html数据,但是一个网站有上千上万条数据,我们不可能知道网站网页的url地址,所以,要有个技巧去抓取网站的所有html页面.Scrapy是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便- Scrapy 使用wisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求.整体架构如下图所示: 绿线是数据流向,首先从初始URL 开始,Scheduler 会将其
-
python爬虫框架scrapy实战之爬取京东商城进阶篇
前言 之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看看详细的介绍吧. 代码详解 1.首先应该构造请求,这里使用scrapy.Request,这个方法默认调用的是start_urls构造请求,如果要改变默认的请求,那么必须重载该方法,这个方法的返回值必须是一个可迭代的对象,一般是用yield返回. 代码如下: def start_requests(self): fo
-
Python爬虫框架Scrapy常用命令总结
本文实例讲述了Python爬虫框架Scrapy常用命令.分享给大家供大家参考,具体如下: 在Scrapy中,工具命令分为两种,一种为全局命令,一种为项目命令. 全局命令不需要依靠Scrapy项目就可以在全局中直接运行,而项目命令必须要在Scrapy项目中才可以运行 全局命令 全局命令有哪些呢,要想了解在Scrapy中有哪些全局命令,可以在不进入Scrapy项目所在目录的情况下,运行scrapy-h,如图所示: 可以看到,此时在可用命令在终端下展示出了常见的全局命令,分别为fetch.runspi
-
python爬虫框架scrapy实现模拟登录操作示例
本文实例讲述了python爬虫框架scrapy实现模拟登录操作.分享给大家供大家参考,具体如下: 一.背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎,很多信息都是需要登录以后才能爬取,但是频繁登录后就会出现验证码(有些网站直接就让你输入验证码),这就坑了,毕竟运维同学很辛苦,该反的还得反,那我们怎么办呢?这不说验证码的事儿,你可以自己手动输入验
-
Python爬虫框架Scrapy基本用法入门教程
本文实例讲述了Python爬虫框架Scrapy基本用法.分享给大家供大家参考,具体如下: Xpath <html> <head> <title>标题</title> </head> <body> <h2>二级标题</h2> <p>爬虫1</p> <p>爬虫2</p> </body> </html> 在上述html代码中,我要获取h2的内容,
-
Python爬虫框架-scrapy的使用
Scrapy Scrapy是纯python实现的一个为了爬取网站数据.提取结构性数据而编写的应用框架. Scrapy使用了Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,并且包含了各种中间件接口,可以灵活的完成各种需求 1.安装 sudo pip3 install scrapy 2.认识scrapy框架 2.1 scrapy架构图 Scrapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递
-
python爬虫框架Scrapy基本应用学习教程
在正式编写爬虫案例前,先对 scrapy 进行一下系统的学习. scrapy 安装与简单运行 使用命令 pip install scrapy 进行安装,成功之后,还需要随手收藏几个网址,以便于后续学习使用. scrapy 官网:https://scrapy.org scrapy 文档:https://doc.scrapy.org/en/latest/intro/tutorial.html scrapy 更新日志:https://docs.scrapy.org/en/latest/news.htm
-
Python爬虫框架Scrapy简介
在爬虫的路上,学习scrapy是一个必不可少的环节.也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习.开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学起.从本篇起,博主将开启scrapy学习的系列,分享如何快速入门scrapy并熟练使用它. 本篇作为第一篇,主要介绍和了解scrapy,在结尾会向大家推荐一本关于学习scrapy的书,以及获取的方式. 为什么要用爬虫框架? 如果你对爬虫的基础知识有了一定了解的话,那么是时候该了解一下爬虫框架了.那么