Python+OpenCV实现车牌字符分割和识别
最近做一个车牌识别项目,入门级别的,十分简单。
车牌识别总体分成两个大的步骤:
一、车牌定位:从照片中圈出车牌
二、车牌字符识别
这里只说第二个步骤,字符识别包括两个步骤:
1、图像处理
原本的图像每个像素点都是RGB定义的,或者称为有R/G/B三个通道。在这种情况下,很难区分谁是背景,谁是字符,所以需要对图像进行一些处理,把每个RGB定义的像素点都转化成一个bit位(即0-1代码),具体方法如下:
①将图片灰度化
名字拗口,但是意思很好理解,就是把每个像素的RGB都变成灰色的RGB值,而灰色的RGB值是R=G=B的。具体怎么改变暂且忽略,因为OpenCV有封装好的函数。
②将灰度图片二值化
我们做第一步的目的就是为了让每个像素都可以转变成0或1。再解释一下,既然每个像素的RGB值都相等了,那么将这个值称为灰度值,假设一张灰度车牌图片中,背景的灰度值集中在180(十进制)左右,而字符的灰度值集中在20左右,那么我们规定一个中间值100,小于100的像素点就可以全部变成0,大于100的像素点可以全部变成1,这样就实现了二值化。
③旋转调平
这个就不说了。
④去燥
这个涉及另外一些方法,以后有时间再补充,入门项目不作要求。
2、图像切割和识别
①图像切割
切割可以很简单,也可以很难,关键是方法的选择。
在这就用最弱智的方法进行切割吧。
图片现在已经成为一个0-1矩阵了,其中要么0是背景而1是字符,或者1是背景而0是字符,那就简单粗暴地用每一列的0-1数来切割。
我先在这里假设图片几乎水平,而且几乎没有噪点,具体方法如下:
a.将每一列的1值和0值分别统计起来。
b.根据每一列的0-1总和变换来切割字符
②图像识别
将每一个字符的图片分割出来后,就可以根据模板来判断是哪个字符了。
简单的方法有两种:
a.逐个像素比对,如果一致则count加一,最后根据count值确定匹配结果。
b.投影匹配:将每行、每列的像素位统计起来,根据差值大小来确定匹配结果。
两种方法结合效果很好。
具体的识别之后再补充。
下面是字符分割的代码。
import cv2
# 1、读取图像,并把图像转换为灰度图像并显示
img = cv2.imread("chepai/6.png") # 读取图片
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换了灰度化
cv2.imshow('gray', img_gray) # 显示图片
cv2.waitKey(0)
# 2、将灰度图像二值化,设定阈值是100
img_thre = img_gray
cv2.threshold(img_gray, 100, 255, cv2.THRESH_BINARY_INV, img_thre)
cv2.imshow('threshold', img_thre)
cv2.waitKey(0)
# 3、保存黑白图片
cv2.imwrite('thre_res.png', img_thre)
# 4、分割字符
white = [] # 记录每一列的白色像素总和
black = [] # ..........黑色.......
height = img_thre.shape[0]
width = img_thre.shape[1]
white_max = 0
black_max = 0
# 计算每一列的黑白色像素总和
for i in range(width):
s = 0 # 这一列白色总数
t = 0 # 这一列黑色总数
for j in range(height):
if img_thre[j][i] == 255:
s += 1
if img_thre[j][i] == 0:
t += 1
white_max = max(white_max, s)
black_max = max(black_max, t)
white.append(s)
black.append(t)
print(s)
print(t)
arg = False # False表示白底黑字;True表示黑底白字
if black_max > white_max:
arg = True
# 分割图像
def find_end(start_):
end_ = start_+1
for m in range(start_+1, width-1):
if (black[m] if arg else white[m]) > (0.95 * black_max if arg else 0.95 * white_max): # 0.95这个参数请多调整,对应下面的0.05
end_ = m
break
return end_
n = 1
start = 1
end = 2
while n < width-2:
n += 1
if (white[n] if arg else black[n]) > (0.05 * white_max if arg else 0.05 * black_max):
# 上面这些判断用来辨别是白底黑字还是黑底白字
# 0.05这个参数请多调整,对应上面的0.95
start = n
end = find_end(start)
n = end
if end-start > 5:
cj = img_thre[1:height, start:end]
cv2.imshow('caijian', cj)
cv2.waitKey(0)
源程序中没有将图片输出,而只是显示出来,下面是执行结果
原图片:

灰度图片:

二值图片:(白底黑字)
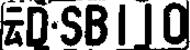
分割后:

总体分割效果还是补充。但是遇到干扰较多的图片,比如左右边框太大、噪点太多,这样就不能分割出来,各位可以试一下不同的照片。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python+opencv实现动态物体识别
注意:这种方法十分受光线变化影响 自己在家拿着手机瞎晃的成果图: 源代码: # -*- coding: utf-8 -*- """ Created on Wed Sep 27 15:47:54 2017 @author: tina """ import cv2 import numpy as np camera = cv2.VideoCapture(0) # 参数0表示第一个摄像头 # 判断视频是否打开 if (camera.isOpened()
-
python+opencv识别图片中的圆形
本文实例为大家分享了python+opencv识别图片中足球的方法,供大家参考,具体内容如下 先补充下霍夫圆变换的几个参数知识: dp,用来检测圆心的累加器图像的分辨率于输入图像之比的倒数,且此参数允许创建一个比输入图像分辨率低的累加器.上述文字不好理解的话,来看例子吧.例如,如果dp= 1时,累加器和输入图像具有相同的分辨率.如果dp=2,累加器便有输入图像一半那么大的宽度和高度. minDist,为霍夫变换检测到的圆的圆心之间的最小距离,即让我们的算法能明显区分的两个不同圆之间的最小距离.这
-
Python+Opencv识别两张相似图片
在网上看到python做图像识别的相关文章后,真心感觉python的功能实在太强大,因此将这些文章总结一下,建立一下自己的知识体系. 当然了,图像识别这个话题作为计算机科学的一个分支,不可能就在本文简单几句就说清,所以本文只作基本算法的科普向. 看到一篇博客是介绍这个,但他用的是PIL中的Image实现的,感觉比较麻烦,于是利用Opencv库进行了更简洁化的实现. 相关背景 要识别两张相似图像,我们从感性上来谈是怎么样的一个过程?首先我们会区分这两张相片的类型,例如是风景照,还是人物照.风景照中
-
python+OpenCV实现车牌号码识别
基于python+OpenCV的车牌号码识别,供大家参考,具体内容如下 车牌识别行业已具备一定的市场规模,在电子警察.公路卡口.停车场.商业管理.汽修服务等领域已取得了部分应用.一个典型的车辆牌照识别系统一般包括以下4个部分:车辆图像获取.车牌定位.车牌字符分割和车牌字符识别 1.车牌定位的主要工作是从获取的车辆图像中找到汽车牌照所在位置,并把车牌从该区域中准确地分割出来 这里所采用的是利用车牌的颜色(黄色.蓝色.绿色) 来进行定位 #定位车牌 def color_position(img,ou
-
python使用opencv进行人脸识别
环境 ubuntu 12.04 LTS python 2.7.3 opencv 2.3.1-7 安装依赖 sudo apt-get install libopencv-* sudo apt-get install python-opencv sudo apt-get install python-numpy 示例代码 #!/usr/bin/env python #coding=utf-8 import os from PIL import Image, ImageDraw import cv d
-
详解如何用OpenCV + Python 实现人脸识别
下午的时候,配好了OpenCV的Python环境,OpenCV的Python环境搭建.于是迫不及待的想体验一下opencv的人脸识别,如下文. 必备知识 Haar-like 通俗的来讲,就是作为人脸特征即可. Haar特征值反映了图像的灰度变化情况.例如:脸部的一些特征能由矩形特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等. opencv api 要想使用opencv,就必须先知道其能干什么,怎么做.于是API的重要性便体现出来了.就本例而言,使用到的函数
-
Python Opencv实现图像轮廓识别功能
本文实例为大家分享了python opencv识别图像轮廓的具体代码,供大家参考,具体内容如下 要求:用矩形或者圆形框住图片中的云朵(不要求全部框出) 轮廓检测 Opencv-Python接口中使用cv2.findContours()函数来查找检测物体的轮廓. import cv2 img = cv2.imread('cloud.jpg') # 灰度图像 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 二值化 ret, binary = cv2.th
-
OpenCV+python手势识别框架和实例讲解
基于OpenCV2.4.8和 python 2.7实现简单的手势识别. 以下为基本步骤 1.去除背景,提取手的轮廓 2. RGB->YUV,同时计算直方图 3.进行形态学滤波,提取感兴趣的区域 4.找到二值化的图像轮廓 5.找到最大的手型轮廓 6.找到手型轮廓的凸包 7.标记手指和手掌 8.把提取的特征点和手势字典中的进行比对,然后判断手势和形状 提取手的轮廓 cv2.findContours() 找到最大凸包cv2.convexHull(),然后找到手掌和手指的相对位置,定位手型的轮廓和关键点
-
python+opencv实现的简单人脸识别代码示例
# 源码如下: #!/usr/bin/env python #coding=utf-8 import os from PIL import Image, ImageDraw import cv def detect_object(image): '''检测图片,获取人脸在图片中的坐标''' grayscale = cv.CreateImage((image.width, image.height), 8, 1) cv.CvtColor(image, grayscale, cv.CV_BGR2GR
-
Python+OpenCV实现车牌字符分割和识别
最近做一个车牌识别项目,入门级别的,十分简单. 车牌识别总体分成两个大的步骤: 一.车牌定位:从照片中圈出车牌 二.车牌字符识别 这里只说第二个步骤,字符识别包括两个步骤: 1.图像处理 原本的图像每个像素点都是RGB定义的,或者称为有R/G/B三个通道.在这种情况下,很难区分谁是背景,谁是字符,所以需要对图像进行一些处理,把每个RGB定义的像素点都转化成一个bit位(即0-1代码),具体方法如下: ①将图片灰度化 名字拗口,但是意思很好理解,就是把每个像素的RGB都变成灰色的RGB值,而灰色的
-
OpenCV实现车牌字符分割(C++)
之前的车牌定位中已经获取到了车牌的位置,并且对车牌进行了提取.我们最终的目的是进行车牌识别,在这之前需要将字符进行分割,方便对每一个字符进行识别,最后将其拼接后便是完整的车牌号码.关于车牌定位可以看这篇文章: OpenCV车牌定位(C++),本文使用的图片也是来自这里. 先来看一看原图: 最左边的汉字本来是 沪,截取时只获得了右边一点点的部分,这与原图和获取方法都有关,对于 川.沪- 这一类左右分开的字会经常发生这类问题,对方法进行优化后可以解决,这里暂时不进行讨论. 后面的字都是完整的,字符分
-
python+opencv实现车牌定位功能(实例代码)
写在前面 HIT大三上学期视听觉信号处理课程中视觉部分的实验三,经过和学长们实验的对比发现每一级实验要求都不一样,因此这里标明了是2019年秋季学期的视觉实验三. 由于时间紧张,代码没有进行任何优化,实验算法仅供参考. 实验要求 对给定的车牌进行车牌识别 实验代码 代码首先贴在这里,仅供参考 源代码 实验代码如下: import cv2 import numpy as np def lpr(filename): img = cv2.imread(filename) # 预处理,包括灰度处理,高斯
-
Python+Opencv身份证号码区域提取及识别实现
前端时间智能信息处理实训,我选择的课题为身份证号码识别,对中华人民共和国公民身份证进行识别,提取并识别其中的身份证号码,将身份证号码识别为字符串的形式输出.现在实训结束了将代码发布出来供大家参考,识别的方式并不复杂,并加了一些注释,如果有什么问题可共同讨论.最后重要的事情说三遍:请勿直接抄袭,请勿直接抄袭,请勿直接抄袭!尤其是我的学弟学妹们,还是要自己做的,小心直接拿我的用被老师发现了挨批^_^. 实训环境:CentOS-7.5.1804 + Python-3.6.6 + Opencv-3.4.
-
OpenCV+Python识别车牌和字符分割的实现
本篇文章主要基于python语言和OpenCV库(cv2)进行车牌区域识别和字符分割,开篇之前针对在python中安装opencv的环境这里不做介绍,可以自行安装配置! 车牌号检测需要大致分为四个部分: 1.车辆图像获取 2.车牌定位. 3.车牌字符分割 4.车牌字符识别 具体介绍 车牌定位需要用到的是图片二值化为黑白后进canny边缘检测后多次进行开运算与闭运算用于消除小块的区域,保留大块的区域,后用cv2.rectangle选取矩形框,从而定位车牌位置 车牌字符的分割前需要准备的是只保留车牌
-
python 实现的车牌识别项目
车牌识别在高速公路中有着广泛的应用,比如我们常见的电子收费(ETC)系统和交通违章车辆的检测,除此之外像小区或地下车库门禁也会用到,基本上凡是需要对车辆进行身份检测的地方都会用到. 简介 车牌识别系统(Vehicle License Plate Recognition)是计算机视频图像识别技术在车辆牌照识别中的一种应用,通常一个车牌识别系统主要包括以下这四个部分: 车辆图像获取 车牌定位 车牌字符分割 车牌字符识别 我们再来看一下百科中对车牌识别技术的描述: 车牌识别技术要求能够将运动中的汽车牌
-
opencv实现车牌识别
本文实例为大家分享了opencv实现车牌识别的具体代码,供大家参考,具体内容如下 (1)提取车牌位置,将车牌从图中分割出来:(2)车牌字符的分割:(3)通过模版匹配识别字符:(4)将结果绘制在图片上显示出来. import cv2 from matplotlib import pyplot as plt import os import numpy as np # plt显示彩色图片 def plt_show0(img): # cv2与plt的图像通道不同:cv2为[b,g,r];plt
-
python中超简单的字符分割算法记录(车牌识别、仪表识别等)
背景 在诸如车牌识别,数字仪表识别等问题中,最关键的就是将单个的字符分割开来再分别进行识别,如下图.最近刚好用到,就自己写了一个简单地算法进行字符分割,来记录一下. 图像预处理 彩图二值化以减小参数量,再进行腐蚀膨胀去除噪点. image = cv2.imread('F://demo.jpg', 0) # 读取为灰度图 _, image = cv2.threshold(image, 50, 255, cv2.THRESH_BINARY) # 二值化 kernel1 = cv2.getStruct
-
Python中OpenCV实现简单车牌字符切割
在Jupyter Notebook上使用Python+opencv实现如下简单车牌字符切割.关于opencv库的安装可以参考:Python下opencv库的安装过程与一些问题汇总. 1.实现代码 import cv2 import numpy as np import matplotlib.pyplot as plt from PIL import Image #读取原图片 image1=cv2.imread("123456.jpg") cv2.imshow("image1&