详解如何利用amoeba(变形虫)实现mysql数据库读写分离
关于mysql的读写分离架构有很多,百度的话几乎都是用mysql_proxy实现的。由于proxy是基于lua脚本语言实现的,所以网上不少网友表示proxy效率不高,也不稳定,不建议在生产环境使用;
amoeba是阿里开发的一款数据库读写分离的项目(读写分离只是它的一个小功能),由于是基于java编写的,所以运行环境需要安装jdk;
前期准备工作:
1.两个数据库,一主一从,主从同步;
- master: 172.22.10.237:3306 ;主库负责写入操作;
- slave: 10.4.66.58:3306 ; 从库负责读取操作;
- amoeba: 172.22.10.237:8066 ; 我把amoeba安装到了主库所在的服务器,当然,你也可以安装到第三台服务器上;
所有服务器操作系统均为centos7;
2.在amoeba所在的服务器上配置安装jdk;
我安装的是jdk1.8;
路径是: JAVA_HOME=/usr/local/java/jdk1.8.0_131
以上务必自己点搭建、配置好,主从正常工作,添加jdk环境变量: /etc/profile ;
安装amoeba的方式有很多,这里就不在安装上面费口舌了,我下载了amoeba-mysql-3.0.5-RC-distribution的安装包,直接解压即可使用;
解压目录: /usr/local/amoeba/
很明显 conf里是配置文件,bin里是启动程序;
刚才说到 amoeba的功能可不止读写分离,但如果只用读写分离功能的话只需要配置这几个个文件即可: conf/dbServers.xml conf/amoeba.xml 和 bin/launcher ;
conf/dbServers.xml :
`<property name="port">3306</property>
#设置Amoeba要连接的mysql数据库的端口,默认是3306
<property name="schema">testdb</property>
#设置缺省的数据库,当连接amoeba时,操作表必须显式的指定数据库名,即采用dbname.tablename的方式,不支持 use dbname指定缺省库,因为操作会调度到各个后端dbserver
<property name="user">test1</property>
#设置amoeba连接后端数据库服务器的账号和密码,因此需要在所有后端数据库上创建该用户,并授权amoeba服务器可连接
<property name="password">111111</property>
<property name="maxActive">500</property> #最大连接数,默认500
<property name="maxIdle">500</property> #最大空闲连接数
<property name="minIdle">1</property> #最新空闲连接数
<dbServer name="writedb" parent="abstractServer"> #设置一个后端可写的数据库,这里定义为writedb,这个名字可以任意命名,后面还会用到
<property name="ipAddress">172.22.10.237</property> #设置后端可写dbserver的ip
<dbServer name="slave01" parent="abstractServer"> #设置后端可读数据库
<property name="ipAddress">10.4.66.58</property>
<dbServer name="myslave" virtual="true"> #设置定义一个虚拟的dbserver,实际上相当于一个dbserver组,这里将可读的数据库ip统一放到一个组中,将这个组的名字命名为myslave
<property name="loadbalance">1</property> #选择调度算法,1表示复制均衡,2表示权重,3表示HA, 这里选择1
<property name="poolNames">slave01</property> #myslave组成员`
conf/amoeba.xml :
<property name="port">8066</property>
#设置amoeba监听的端口,默认是8066
<property name="ipAddress">127.0.0.1</property>
#配置监听的接口,如果不设置,默认监听所以的IP
# 提供客户端连接amoeba时需要使用这里设定的账号 (这里的账号密码和amoeba连接后端数据库服务器的密码无关)
<property name="user">root</property>
<property name="password">123456</property>
<property name="defaultPool">myslave</property>
#设置amoeba默认的池,这里设置为writedb
<property name="writePool">master</property>
#这两个选项默认是注销掉的,需要取消注释,这里用来指定前面定义好的俩个读写池
<property name="readPool">slave01</property>
bin/launcher :
#启动脚本,需要配置jdk环境变量;
#在注释后的第一行添加:
JAVA_HOME=/usr/local/java/jdk1.8.0_131
launcher 是启动脚本,如果不配置JAVA_HOME的话,即便你在/etc/profile中配置了环境变量也可能会报错:没有配置jdk环境变量;
还有一个配置文件: jvm.properties
#占用内存配置文件
# -Xss参数有最小值要求,必须大于228才能启动JVM
#修改:
JVM_OPTIONS="-server -Xms1024m -Xmx1024m -Xss256k -XX:PermSize=16m -XX:MaxPermSize=96m"
有经验的运维都知道,凡是和jdk沾上边的,基本都会和内存的调优有关系,amoeba也不例外;
现在可以启动了:
启动后就可以看到本机的8066端口:
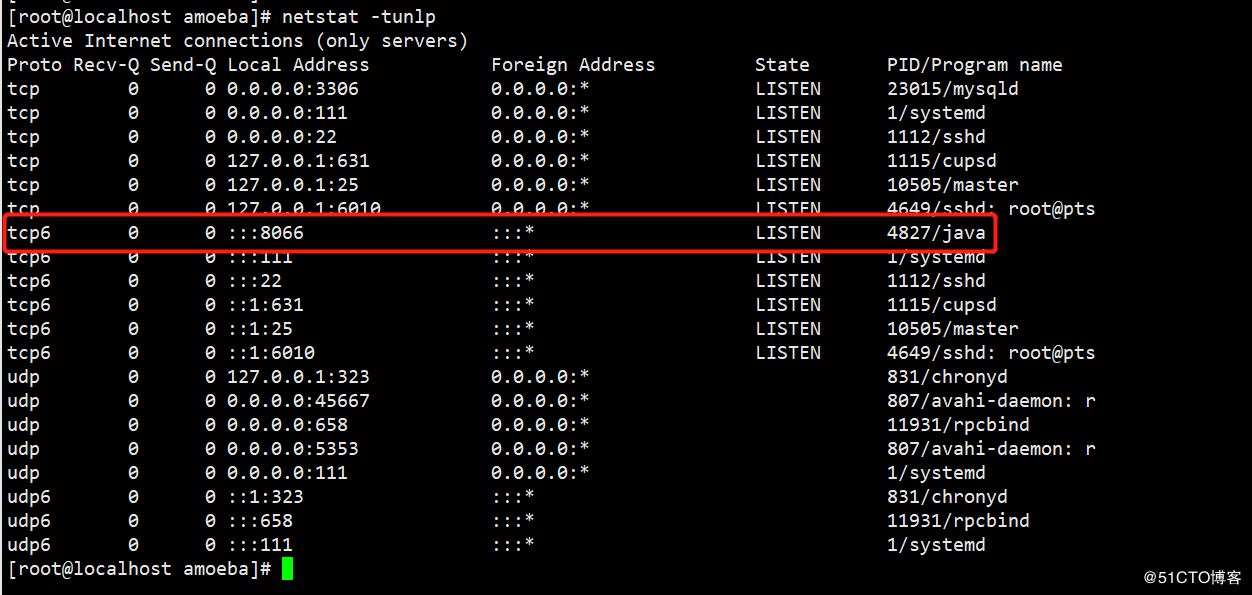
这时,你只需要通过本机ip的8066端口和你配置文件中设置的账号密码来连接数据库就行了,写入的数据都会到master里,读取的数据都会从slave中读取;
测试:
关闭master数据库,依然可以读取:执行 select 查看命令;
或者
关闭slave数据库,依然可以写入: 执行 update、inster命令;
相关推荐
-
MySQL主从同步、读写分离配置步骤
现在使用的两台服务器已经安装了MySQL,全是rpm包装的,能正常使用. 为了避免不必要的麻烦,主从服务器MySQL版本尽量保持一致; 环境:192.168.0.1 (Master) 192.168.0.2 (Slave) MySQL Version:Ver 14.14 Distrib 5.1.48, for pc-linux-gnu (i686) using readline 5.1 1.登录Master服务器,修改my.cnf,添加如下内容: server-id = 1 //数据库ID号,
-
mysql主从复制读写分离的配置方法详解
一.说明 前面我们说了mysql的安装配置,mysql语句使用以及备份恢复mysql数据;本次要介绍的是mysql的主从复制,读写分离;及高可用MHA; 环境如下: master:CentOS7_x64 mysql5.721 172.16.3.175 db1 slave1:CentOS7_x64 mysql5.7.21 172.16.3.235 db2 slave2:CentOS7_x64 mysql5.7.21 172.16.3.235 db3 proxysql/MHA:CentOS7_x64
-

详解MySQL的主从复制、读写分离、备份恢复
一.MySQL主从复制 1.简介 我们为什么要用主从复制? 主从复制目的: 可以做数据库的实时备份,保证数据的完整性: 可做读写分离,主服务器只管写,从服务器只管读,这样可以提升整体性能. 原理图: 从上图可以看出,同步是靠log文件同步读写完成的. 2.更改配置文件 两天机器都操作,确保 server-id 要不同,通常主ID要小于从ID.一定注意. # 3306和3307分别代表2台机器 # 打开log-bin,并使server-id不一样 #vim /data/3306/my.cnf lo
-
详解MySQL主从复制读写分离搭建
MySQL主从设置 MySQL主从复制,读写分离的设置非常简单: 修改配置my.cnf文件 master 和 slave设置的差不多: [mysqld] log-bin=mysql-bin server-id=222 log-bin=mysql-bin的意思是:启用二进制日志. server-id=222的意思是设置了服务器的唯一ID,默认是1,一般取IP最后一段,可以写成别的,只要不和其他mysql服务器重复就好. 这里,有的MySQL默认的my.cnf文件引用了/etc/mysql/conf
-
mysql 读写分离(实战篇)
MySQL Proxy最强大的一项功能是实现"读写分离(Read/Write Splitting)".基本的原理是让主数据库处理事务性查询,而从数据库处理SELECT查询.数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库. Jan Kneschke在<MySQL Proxy learns R/W Splitting>中详细的介绍了这种技巧以及连接池问题: 为了实现读写分离我们需要连接池.我们仅在已打开了到一个后端的一条经过认证的连接的情况下,才切换到该后端.My
-
mysql 读写分离(基础篇)
基本的原理是让主数据库处理事务性查询,而从数据库处理SELECT查询.数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库. Jan Kneschke在<MySQL Proxy learns R/W Splitting>中详细的介绍了这种技巧以及连接池问题: 为了实现读写分离我们需要连接池.我们仅在已打开了到一个后端的一条经过认证的连接的情况下,才切换到该后端.MySQL协议首先进行握手.当进入到查询/返回结果的阶段再认证新连接就太晚了.我们必须保证拥有足够的打开的连接才能保持运作正常
-
MySQL的使用中实现读写分离的教程
mysql-proxy实现读写分离 MySQL Proxy是一个处于你的client端和MySQL server端之间的简单程序,它可以监测.分析或改变它们的通信.它使用灵活,没有限制,常见的用途包括:负载平衡,故障.查询分析,查询过滤和修改等等. MySQL Proxy就是这么一个中间层代理,简单的说,MySQL Proxy就是一个连接池,负责将前台应用的连接请求转发给后台的数据库,并且通过使用lua脚本,可以实现复杂的连接控制和过滤,从而实现读写分离和负载平衡.对于应用来说,MySQL Pr
-
详解如何利用amoeba(变形虫)实现mysql数据库读写分离
关于mysql的读写分离架构有很多,百度的话几乎都是用mysql_proxy实现的.由于proxy是基于lua脚本语言实现的,所以网上不少网友表示proxy效率不高,也不稳定,不建议在生产环境使用: amoeba是阿里开发的一款数据库读写分离的项目(读写分离只是它的一个小功能),由于是基于java编写的,所以运行环境需要安装jdk: 前期准备工作: 1.两个数据库,一主一从,主从同步: master: 172.22.10.237:3306 :主库负责写入操作: slave: 10.4.66.58
-
详解如何在阿里云服务器安装Mysql数据库
前言 由于在学习过程中需要安装zookeeper,我的虚拟机一直有问题,就够买了阿里云服务器.安装完zookeeper后想着把数据库也安装在服务器上,释放一下电脑的压力,在安装数据库的时候遇到了很多问题,通过查看有些大佬的作品终于安装好了数据库.现在就我遇到的问题总结如下: 一.卸载Mysql 1.查看是否安装mysql 首先检查是否已经安装,如果已经安装先删除以前版本,以免安装不成功 [root@localhost ~]# php -v 或 [root@localhost ~]# rpm -q
-
SpringBoot图文并茂详解如何引入mybatis与连接Mysql数据库
目录 创建一个SpringBoot项目 创建mysql表 编写实体类 配置Mapper 感叹 创建一个SpringBoot项目 其他不赘叙了,引入MyBaties.MySql依赖 创建mysql表 CREATE TABLE sp_users( `id` INT PRIMARY KEY, `username` VARCHAR(30), `age` INT ); 刚开始一直出现这个错误,弄的我怀疑人生,结果是最后一行不能加',' ,物是人非. INSERT INTO sp_users(id,`use
-
spring集成mybatis实现mysql数据库读写分离
前言 在网站的用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈.幸运的是目前大部分的主流数据库都提供主从热备功能,通过配置两台数据库主从关系,可以将一台数据库的数据更新同步到另一台服务器上.网站利用数据库的这一功能,实现数据库读写分离,从而改善数据库负载压力.如下图所示: 应用服务器在写数据的时候,访问主数据库,主数据库通过主从复制机制将数据更新同步到从数据库,这样当应用服务器读数据的时候,就可以通过从数据库获得数据.为了便于应用程序访问读写分离后的数据库,通常在应用服务器使用专门的数
-
Python web框架(django,flask)实现mysql数据库读写分离的示例
读写分离,顾名思义,我们可以把读和写两个操作分开,减轻数据的访问压力,解决高并发的问题. 那么我们今天就Python两大框架来做这个读写分离的操作. 1.Django框架实现读写分离 Django做读写分离非常的简单,直接在settings.py中把从机加入到数据库的配置文件中就可以了. DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'HOST': '127.0.0.1', # 主服务器的运行ip 'PORT':
-
使用Spring AOP实现MySQL数据库读写分离案例分析(附demo)
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库的主从配置,最简单的是一台Master和一台Slave(大型网站系统的话,当然会很复杂,这里只是分析了最简单的情况).通过主从配置主从数据库保持了相同的数据,我们在进行读操作的时候访问从数据库Slave,在进行写操作的时候访问主数据库Master.这样的话就减轻了一台服务器的压力. 在进行读写分离
-
详解使用navicat连接远程linux mysql数据库出现10061未知故障
使用使用navicat连接远程linux mysql数据库出现10061未知故障,设置使用ssh连接后出现2013故障 本机环境:win10 navicat premium mysql数据库主机环境:Linux version 4.15.0-42-generic (buildd@lgw01-amd64-023) (gcc version 7.3.0 (Ubuntu 7.3.0-16ubuntu3)) #45-Ubuntu SMP Thu Nov 15 19:32:57 UTC 2018 mysq
-
利用mycat实现mysql数据库读写分离的示例
什么是MyCAT 一个彻底开源的,面向企业应用开发的大数据库集群 支持事务.ACID.可以替代MySQL的加强版数据库 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群 一个融合内存缓存技术.NoSQL技术.HDFS大数据的新型SQL Server 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品 一个新颖的数据库中间件产品 MyCAT关键特性 支持SQL92标准 支持MySQL.Oracle.DB2.SQL Server.PostgreSQL等DB的常见SQL
-
thinkphp下MySQL数据库读写分离代码剖析
当采用原生态的sql语句进行写入操作的时候,要用execute,读操作要用query. MySQL数据主从同步还是要靠MySQL的机制来实现,所以这个时候MySQL主从同步的延迟问题是需要优化,延迟时间太长不仅影响业务,还影响用户体验. thinkphp核心类Thinkphp/library/Model.class.php 中,query 方法,调用Thinkphp/library/Think/Db/Driver/Mysql.class.php /** * SQL查询 * @access pub
-
详解如何利用docker快速构建MySQL主从复制环境
在学习MySQL的过程中,常常会测试各种参数的作用.这时候,就需要快速构建出MySQL实例,甚至主从. 考虑如下场景: 譬如我想测试mysqldump在指定--single-transaction参数的情况下,对于myisam表的影响. 本来想在现成的测试环境中进行,但测试环境中,有大量的数据,执行mysqldump进行全备,产生的SQL文件,很难基于表进行搜索. 这个时候,就特别渴望能有一套干净的实例进行测试. 此刻,快速构建能力就显得尤为必要,很多童鞋可能会问,通过脚本不就能实现么?为什么要