图文解析布隆过滤器大小的算法公式
目录
- 1. 简介
- 2. 应用场景
- 2.1 缓存穿透
- 2.2 判断某个数据是否在海量数据中存在
- 3. HashMap的问题
- 4. 理解布隆过滤器
- 5. 根据布隆过滤器查询元素
- 6. 可以删除么
- 7. 如何选择哈希函数个数和布隆过滤器长度
- 更多应用场景
1. 简介
客户端:这个key存在吗?
服务器:不存在/不知道
本质上,布隆过滤器是一种数据结构,是一种比较巧妙的概率型数据结构。它的特点是高效地插入和查询。但我们要检查一个key是否在某个结构中存在时,通过使用布隆过滤器,我们可以快速了解到「这个key一定不存在或者可能存在」。相比于传统的List、Set、Map这些数据结构,它更加高效、占用的空间也越少,但是它返回的结果是概率性的,是不确切的。
布隆过滤器仅用于测试集合中的成员资格。使用布隆过滤器的经典示例是减少对不存在的密钥的昂贵磁盘(或网络)查找。正如我们看到的那样,布隆过滤器可以在O(k)恒定时间内搜索密钥,其中k是哈希函数的数量,测试密钥的不存在将非常快。
2. 应用场景
2.1 缓存穿透
为了提高访问效率,我们会将一些数据放在Redis缓存中。当进行数据查询时,可以先从缓存中获取数据,无需读取数据库。这样可以有效地提升性能。
在数据查询时,首先要判断缓存中是否有数据,如果有数据,就直接从缓存中获取数据。
但如果没有数据,就需要从数据库中获取数据,然后放入缓存。如果大量访问都无法命中缓存,会造成数据库要扛较大压力,从而导致数据库崩溃。而使用布隆过滤器,当访问不存在的缓存时,可以迅速返回避免缓存或者DB crash。
2.2 判断某个数据是否在海量数据中存在
HBase中存储着非常海量数据,要判断某个ROWKEYS、或者某个列是否存在,使用布隆过滤器,可以快速获取某个数据是否存在。但有一定的误判率。但如果某个key不存在,一定是准确的。
3. HashMap的问题
要判断某个元素是否存在其实用HashMap效率是非常高的。HashMap通过把值映射为HashMap的Key,这种方式可以实现O(1)常数级时间复杂度。
但是,如果存储的数据量非常大的时候(例如:上亿的数据),HashMap将会耗费非常大的内存大小。而且也根本无法一次性将海量的数据读进内存。
4. 理解布隆过滤器
工作原理图:
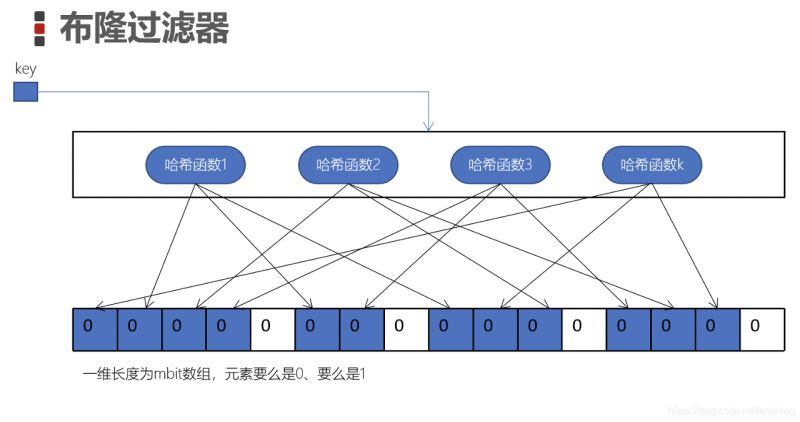
布隆过滤器是一个bit数组或者称为一个bit二进制向量
这个数组中的元素存的要么是0、要么是1
k个hash函数都是彼此独立的,并将每个hash函数计算后的结果对数组的长度m取模,并将对一个的bit设置为1(蓝色单元格)
我们将每个key都按照这种方式设置单元格,就是「布隆过滤器」
5. 根据布隆过滤器查询元素
假设输入一个key,我们使用之前的k个hash函数求哈希,得到k个值
判断这k个值是否都为蓝色,如果有一个不是蓝色,那么这个key一定不存在
如果都有蓝色,那么key是可能存在(布隆过滤器会存在误判)
因为如果输入对象很多,而集合比较小的情况,会导致集合中大多位置都会被描蓝,那么检查某个key时候为蓝色时,刚好某个位置正好被设置为蓝色了,此时,会错误认为该key在集合中
示例:
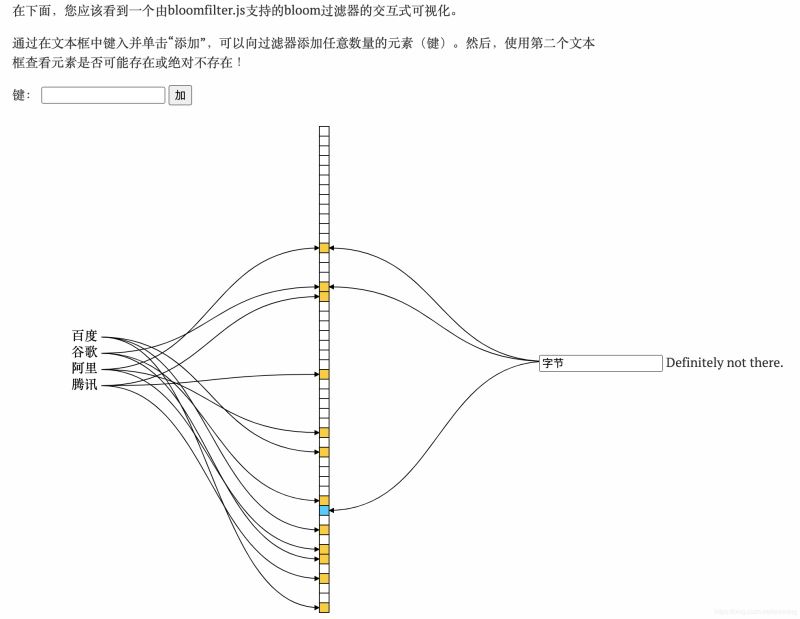
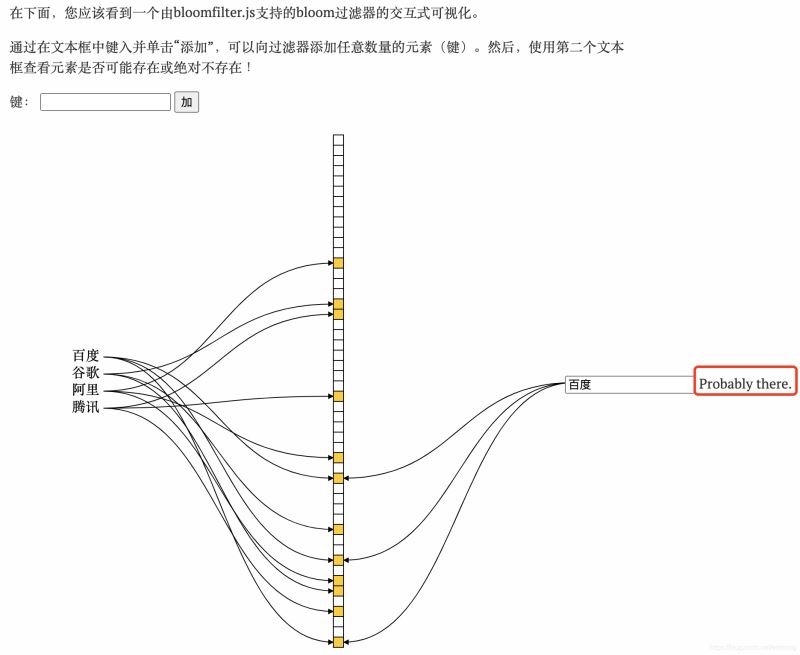
6. 可以删除么
传统的布隆过滤器并不支持删除操作。但是名为 Counting Bloom filter 的变种可以用来测试元素计数个数是否绝对小于某个阈值,它支持元素删除。详细理解可以参考文章Counting Bloom Filter 的原理和实现, 写的很详细。
7. 如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
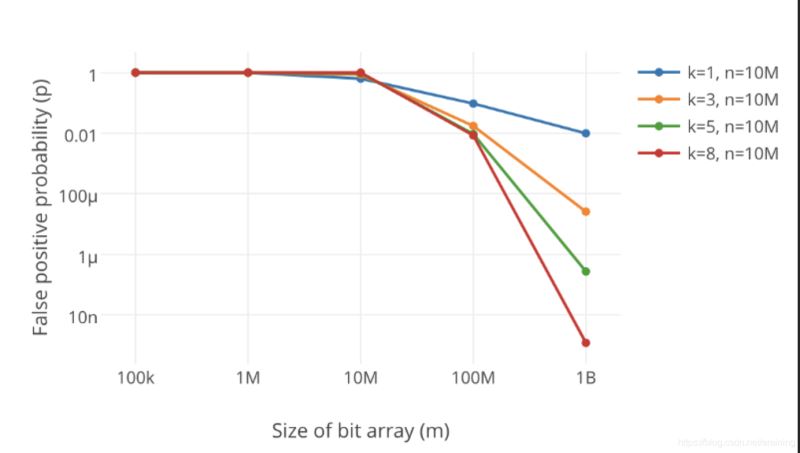
从上图可以看出,增加哈希函数k的数量将大大降低错误率p。

好像是WTF?不用担心,实际上我们实际上需要确定我们的m和k。因此,如果我们自己设置容错值p和元素数n,则可以使用以下公式来计算这些参数:
我们可以根据过滤器的大小m,哈希函数的数量k和插入的元素的数量n来计算误报率p,公式如下:由上面,又怎么选择适合业务的 k 和 m 值呢?
公式:

k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
至于如何推导这个公式,我在知乎发布的文章有涉及,感兴趣可以看看,不感兴趣的话记住上面这个公式就行了。
我还要在这里提到另一个重要的观点。由于使用Bloom筛选器的唯一目的是搜索速度更快,所以我们不能使用慢速哈希函数,对吗?加密散列函数(例如Sha-1,MD5)对于bloom过滤器不是一个好选择,因为它们有点慢。因此,从更快的哈希函数实现中更好的选择是murmur,fnv系列哈希,Jenkins哈希和HashMix。
更多应用场景
在给定的示例中您已经看到,我们可以使用它来警告用户输入弱密码。
您可以使用布隆过滤器,以防止用户从访问恶意网站。
您可以先使用Bloom Bloom筛选器进行廉价的查找检查,而不用查询SQL数据库来检查是否存在具有特定电子邮件的用户。如果电子邮件不存在,那就太好了!如果确实存在,则可能必须对数据库进行额外的查询。您也可以执行同样的操作来搜索“用户名已被占用”。
您可以根据网站访问者的IP地址保留一个Bloom过滤器,以检查您网站的用户是“回头用户”还是“新用户”。“回头用户”的一些误报不会伤害您,对吗?
您也可以通过使用Bloom过滤器跟踪词典单词来进行拼写检查。
以上就是布隆过滤器算法图文详解的详细内容,更多关于布隆过滤器算法的资料请关注我们其它相关文章!
相关推荐
-
Python+Redis实现布隆过滤器
布隆过滤器是什么 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难. 布隆过滤器的基本思想 通过一种叫作散列表(又叫哈希表,Hash table)的数据结构.它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点.这样一来,我们只要看看这个点是不是1就可以知道集合中有没
-

布隆过滤器(bloom filter)及php和redis实现布隆过滤器的方法
引言 在介绍布隆过滤器之前我们首先引入几个场景. 场景一 在一个高并发的计数系统中,如果一个key没有计数,此时我们应该返回0,但是访问的key不存在,相当于每次访问缓存都不起作用了.那么如何避免频繁访问数量为0的key而导致的缓存被击穿? 有人说, 将这个key的值置为0存入缓存不就行了吗?确实,这是一个好的方案.大部分情况我们都是这样做的,当访问一个不存在的key的时候,设置一个带有过期时间的标志,然后放入缓存.不过这样做的缺点也很明显,浪费内存和无法抵御随机key攻击. 场景二 在一个黑名
-
python实现布隆过滤器及原理解析
在学习redis过程中提到一个缓存击穿的问题, 书中参考的解决方案之一是使用布隆过滤器, 那么就有必要来了解一下什么是布隆过滤器.在参考了许多博客之后, 写个总结记录一下. 一.布隆过滤器简介 什么是布隆过滤器? 本质上布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 "某样东西一定不存在或者可能存在". 相比于传统的 Set.Map 等数据结构,它更高效
-
Java实现布隆过滤器的方法步骤
前言 记得前段时间的文章么?redis使用位图法记录在线用户的状态,还是需要自己实现一个IM在线用户状态的记录,今天来讲讲另一方案,布隆过滤器 布隆过滤器的作用是加快判定一个元素是否在集合中出现的方法.因为其主要是过滤掉了大部分元素间的精确匹配,故称为过滤器. 布隆过滤器 在日常生活工作,我们会经常遇到这的场景,从一个Excel里面检索一个信息在不在Excel表中,还记得被CTRL+F支配的恐惧么,不扯了,软件开发中,一般会使用散列表来实现,Hash Table也叫哈希表,哈希表的优点是快速准确
-
布隆过滤器的概述及Python实现方法
布隆过滤器 布隆过滤器是一种概率空间高效的数据结构.它与hashmap非常相似,用于检索一个元素是否在一个集合中.它在检索元素是否存在时,能很好地取舍空间使用率与误报比例.正是由于这个特性,它被称作概率性数据结构(probabilistic data structure). 空间效率 我们来仔细地看看它的空间效率.如果你想在集合中存储一系列的元素,有很多种不同的做法.你可以把数据存储在hashmap,随后在hashmap中检索元素是否存在,hashmap的插入和查询的效率都非常高.但是,由于ha
-
Redis实现布隆过滤器的方法及原理
布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难. 本文将介绍布隆过滤器的原理以及Redis如何实现布隆过滤器. 应用场景 1.50亿个电话号码,现有10万个电话号码,如何判断这10万个是否已经存在在50亿个之中?(可能方案:数据库,set, hyperloglog) 2.新闻客户端看新闻时,它会不
-
图文解析布隆过滤器大小的算法公式
目录 1. 简介 2. 应用场景 2.1 缓存穿透 2.2 判断某个数据是否在海量数据中存在 3. HashMap的问题 4. 理解布隆过滤器 5. 根据布隆过滤器查询元素 6. 可以删除么 7. 如何选择哈希函数个数和布隆过滤器长度 更多应用场景 1. 简介 客户端:这个key存在吗? 服务器:不存在/不知道 本质上,布隆过滤器是一种数据结构,是一种比较巧妙的概率型数据结构.它的特点是高效地插入和查询.但我们要检查一个key是否在某个结构中存在时,通过使用布隆过滤器,我们可以快速了解到「这个k
-
通过实例解析布隆过滤器工作原理及实例
布隆过滤器 布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 "一定不存在或者可能存在". 相比于传统的 List.Set.Map 等数据结构,它更高效.占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的. 布隆过滤器的工作原理 假设一个长度为m的bit类型的数组,即数组中每个位置只占一个bit,每个bit只有两种状态:0,1,所有bit的初始状态都为0. 再假设一共有k个哈
-
go语言中布隆过滤器低空间成本判断元素是否存在方式
目录 简介 原理 数据结构 添加 判断存在 哈希函数 布隆过滤器大小.哈希函数数量.误判率 应用场景 数据库 黑名单 实现 数据结构 初始化 添加元素 判断元素是否存在 简介 布隆过滤器(BloomFilter)是一种用于判断元素是否存在的方式,它的空间成本非常小,速度也很快. 但是由于它是基于概率的,因此它存在一定的误判率,它的Contains()操作如果返回true只是表示元素可能存在集合内,返回false则表示元素一定不存在集合内.因此适合用于能够容忍一定误判元素存在集合内的场景,比如缓存
-
C++详细讲解模拟实现位图和布隆过滤器的方法
目录 位图 引论 概念 解决引论 位图的模拟实现 铺垫 结构 构造函数 存储 set,reset,test flip,size,count any,none,all 重载流运算符 测试 位图简单应用 位图代码汇总 布隆过滤器 引论 要点 代码实现 效率 解决方法 位图 引论 四十亿个无符号整数,现在给你一个无符号整数,判断这个数是否在这四十亿个数中. 路人甲:简单,快排+二分. 可是存储这四十亿个整数需要多少空间? 简单算一下,1G=1024M=1024 * 1024KB=1024 * 1024
-
JAVA实现较完善的布隆过滤器的示例代码
布隆过滤器是可以用于判断一个元素是不是在一个集合里,并且相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势.布隆过滤器存储空间和插入/查询时间都是常数.但是它也是拥有一定的缺点:布隆过滤器是有一定的误识别率以及删除困难的.本文中给出的布隆过滤器的实现,基本满足了日常使用所需要的功能. 0 0 0 0 0 0 0 0 0 0 先简单来说一下布隆过滤器.其实现方法就是:利用内存中一个长度为M的位数组B并初始化里面的所有位都为0,如下面的表格所示: 然后我们根据H个不同的散列函数,对传进来
-
Redis 中的布隆过滤器的实现
什么是『布隆过滤器』 布隆过滤器是一个神奇的数据结构,可以用来判断一个元素是否在一个集合中.很常用的一个功能是用来去重.在爬虫中常见的一个需求:目标网站 URL 千千万,怎么判断某个 URL 爬虫是否宠幸过?简单点可以爬虫每采集过一个 URL,就把这个 URL 存入数据库中,每次一个新的 URL 过来就到数据库查询下是否访问过. select id from table where url = 'https://jaychen.cc' 但是随着爬虫爬过的 URL 越来越多,每次请求前都要访问数据