Java并发工具类LongAdder原理实例解析
LongAdder实现原理图
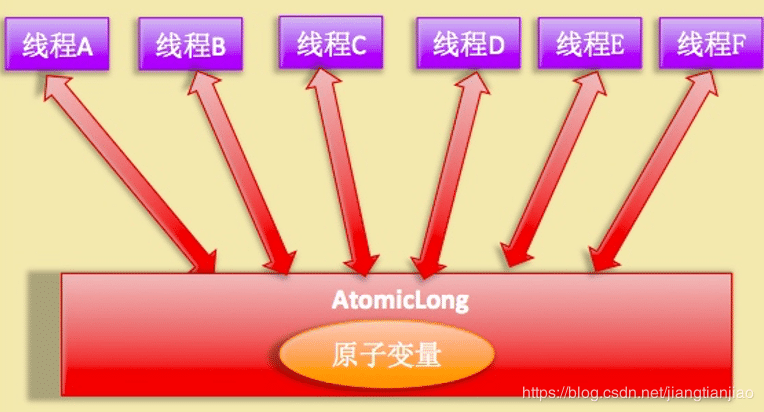
高并发下N多线程同时去操作一个变量会造成大量线程CAS失败,然后处于自旋状态,导致严重浪费CPU资源,降低了并发性。既然AtomicLong性能问题是由于过多线程同时去竞争同一个变量的更新而降低的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源。
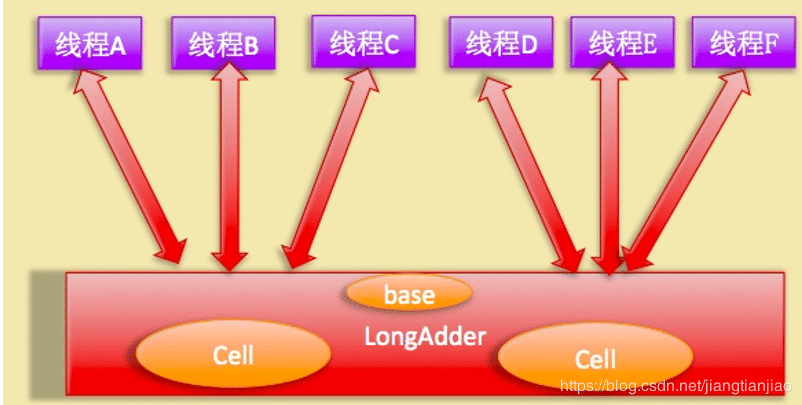
LongAdder则是内部维护一个Cells数组,每个Cell里面有一个初始值为0的long型变量,在同等并发量的情况下,争夺单个变量的线程会减少,这是变相的减少了争夺共享资源的并发量,另外多个线程在争夺同一个原子变量时候,如果失败并不是自旋CAS重试,而是尝试获取其他原子变量的锁,最后当获取当前值时候是把所有变量的值累加后再加上base的值返回的。
LongAdder维护了要给延迟初始化的原子性更新数组和一个基值变量base数组的大小保持是2的N次方大小,数组表的下标使用每个线程的hashcode值的掩码表示,数组里面的变量实体是Cell类型。
Cell 类型是Atomic的一个改进,用来减少缓存的争用,对于大多数原子操作字节填充是浪费的,因为原子操作都是无规律的分散在内存中进行的,多个原子性操作彼此之间是没有接触的,但是原子性数组元素彼此相邻存放将能经常共享缓存行,也就是伪共享。所以这在性能上是一个提升。
另外由于Cells占用内存是相对比较大的,所以一开始并不创建,而是在需要时候再创建,也就是惰性加载,当一开始没有空间时候,所有的更新都是操作base变量。
java.util.concurrency.atomic.LongAdder是Java8新增的一个类,提供了原子累计值的方法。根据文档的描述其性能要优于AtomicLong
这里测试时基于JDK1.8进行的,AtomicLong 从Java8开始针对x86平台进行了优化,使用XADD替换了CAS操作,我们知道JUC下面提供的原子类都是基于Unsafe类实现的,并由Unsafe来提供CAS的能力。CAS (compare-and-swap)本质上是由现代CPU在硬件级实现的原子指令,允许进行无阻塞,多线程的数据操作同时兼顾了安全性以及效率。大部分情况下,CAS都能够提供不错的性能,但是在高竞争的情况下开销可能会成倍增长,具体的研究可以参考这篇文章, 我们直接看下代码:
public class AtomicLong {
public final long incrementAndGet() {
return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L;
}
}
public final class Unsafe {
public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
}
getAndAddLong方法会以volatile的语义去读需要自增的域的最新值,然后通过CAS去尝试更新,正常情况下会直接成功后返回,但是在高并发下可能会同时有很多线程同时尝试这个过程,也就是说线程A读到的最新值可能实际已经过期了,因此需要在while循环中不断的重试,造成很多不必要的开销,而xadd的相对来说会更高效一点,伪码如下,最重要的是下面这段代码是原子的,也就是说其他线程不能打断它的执行或者看到中间值,这条指令是在硬件级直接支持的:
function FetchAndAdd(address location, int inc) {
int value := *location
*location := value + inc
return value
}
而LongAdder的性能比上面那种还要好很多,于是就研究了一下。首先它有一个基础的值base,在发生竞争的情况下,会有一个Cell数组用于将不同线程的操作离散到不同的节点上去(会根据需要扩容,最大为CPU核数),sum()会将所有Cell数组中的value和base累加作为返回值。核心的思想就是将AtomicLong一个value的更新压力分散到多个value中去,从而降低更新热点。
public class LongAdder extends Striped64 implements Serializable {
//...
}
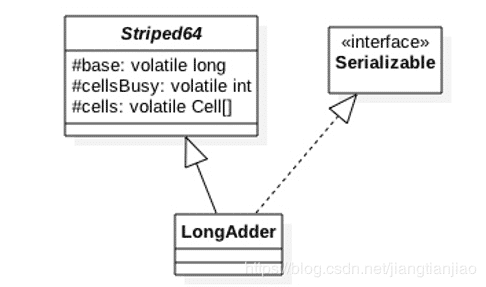
LongAdder继承自Striped64,Striped64内部维护了一个懒加载的数组以及一个额外的base实例域,数组的大小是2的N次方,使用每个线程Thread内部的哈希值访问。
abstract class Striped64 extends Number {
/** Number of CPUS, to place bound on table size */
static final int NCPU = Runtime.getRuntime().availableProcessors();
/**
* Table of cells. When non-null, size is a power of 2.
*/
transient volatile Cell[] cells;
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
}
数组的元素是Cell类,可以看到Cell类用Contended注解修饰,这里主要是解决false sharing(伪共享的问题),不过个人认为伪共享翻译的不是很好,或者应该是错误的共享,比如两个volatile变量被分配到了同一个缓存行,但是这两个的更新在高并发下会竞争,比如线程A去更新变量a,线程B去更新变量b,但是这两个变量被分配到了同一个缓存行,因此会造成每个线程都去争抢缓存行的所有权,例如A获取了所有权然后执行更新这时由于volatile的语义会造成其刷新到主存,但是由于变量b也被缓存到同一个缓存行,因此就会造成cache miss,这样就会造成极大的性能损失,因此有一些类库的作者,例如JUC下面的、Disruptor等都利用了插入dummy 变量的方式,使得缓存行被其独占,比如下面这种代码:
static final class Cell {
volatile long p0, p1, p2, p3, p4, p5, p6;
volatile long value;
volatile long q0, q1, q2, q3, q4, q5, q6;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
但是这种方式毕竟不通用,例如32、64位操作系统的缓存行大小不一样,因此JAVA8中就增加了一个注@sun.misc.Contended解用于解决这个问题,由JVM去插入这些变量,具体可以参考openjdk.java.net/jeps/142 ,但是通常来说对象是不规则的分配到内存中的,但是数组由于是连续的内存,因此可能会共享缓存行,因此这里加一个Contended注解以防cells数组发生伪共享的情况。
/**
* 底竞争下直接更新base,类似AtomicLong
* 高并发下,会将每个线程的操作hash到不同的
* cells数组中,从而将AtomicLong中更新
* 一个value的行为优化之后,分散到多个value中
* 从而降低更新热点,而需要得到当前值的时候,直接
* 将所有cell中的value与base相加即可,但是跟
* AtomicLong(compare and change -> xadd)的CAS不同,
* incrementAndGet操作及其变种
* 可以返回更新后的值,而LongAdder返回的是void
*/
public class LongAdder {
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
/**
* 如果是第一次执行,则直接case操作base
*/
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
/**
* as数组为空(null或者size为0)
* 或者当前线程取模as数组大小为空
* 或者cas更新Cell失败
*/
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
public long sum() {
//通过累加base与cells数组中的value从而获得sum
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
}
/**
* openjdk.java.net/jeps/142
*/
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
abstract class Striped64 extends Number {
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
/**
* 若getProbe为0,说明需要初始化
*/
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
/**
* 失败重试
*/
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
/**
* 若as数组已经初始化,(n-1) & h 即为取模操作,相对 % 效率要更高
*/
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {//这里casCellsBusy的作用其实就是一个spin lock
//可能会有多个线程执行了`Cell r = new Cell(x);`,
//因此这里进行cas操作,避免线程安全的问题,同时前面在判断一次
//避免正在初始化的时其他线程再进行额外的cas操作
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
//重新检查一下是否已经创建成功了
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot 现在是非空了,continue到下次循环重试
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;//若cas更新成功则跳出循环,否则继续重试
else if (n >= NCPU || cells != as) // 最大只能扩容到CPU数目, 或者是已经扩容成功,这里只有的本地引用as已经过期了
collide = false; // At max size or stale
else if (!collide)
collide = true;
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // 扩容
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
//重新计算hash(异或)从而尝试找到下一个空的slot
h = advanceProbe(h);
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
/**
* 默认size为2
*/
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x : // 若已经有另一个线程在初始化,那么尝试直接更新base
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
final boolean casCellsBusy() {
return UNSAFE.compareAndSwapInt(this, CELLSBUSY, 0, 1);
}
static final int getProbe() {
/**
* 通过Unsafe获取Thread中threadLocalRandomProbe的值
*/
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long BASE;
private static final long CELLSBUSY;
private static final long PROBE;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> sk = Striped64.class;
BASE = UNSAFE.objectFieldOffset
(sk.getDeclaredField("base"));
CELLSBUSY = UNSAFE.objectFieldOffset
(sk.getDeclaredField("cellsBusy"));
Class<?> tk = Thread.class;
//返回Field在内存中相对于对象内存地址的偏移量
PROBE = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomProbe"));
} catch (Exception e) {
throw new Error(e);
}
}
}
由于Cell相对来说比较占内存,因此这里采用懒加载的方式,在无竞争的情况下直接更新base域,在第一次发生竞争的时候(CAS失败)就会创建一个大小为2的cells数组,每次扩容都是加倍,只到达到CPU核数。同时我们知道扩容数组等行为需要只能有一个线程同时执行,因此需要一个锁,这里通过CAS更新cellsBusy来实现一个简单的spin lock。
数组访问索引是通过Thread里的threadLocalRandomProbe域取模实现的,这个域是ThreadLocalRandom更新的,cells的数组大小被限制为CPU的核数,因为即使有超过核数个线程去更新,但是每个线程也只会和一个CPU绑定,更新的时候顶多会有cpu核数个线程,因此我们只需要通过hash将不同线程的更新行为离散到不同的slot即可。
我们知道线程、线程池会被关闭或销毁,这个时候可能这个线程之前占用的slot就会变成没人用的,但我们也不能清除掉,因为一般web应用都是长时间运行的,线程通常也会动态创建、销毁,很可能一段时间后又会被其他线程占用,而对于短时间运行的,例如单元测试,清除掉有啥意义呢?
总结
总的来说,LongAdder从性能上来说要远远好于AtomicLong,一般情况下是可以直接替代AtomicLong使用的,Netty也通过一个接口封装了这两个类,在Java8下直接采用LongAdder,但是AtomicLong的一系列方法不仅仅可以自增,还可以获取更新后的值,如果是例如获取一个全局唯一的ID还是采用AtomicLong会方便一点。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Java并发工具辅助类代码实例
java中的并发工具类 一:等待多线程完成的CountDownLatch CountDownLatch允许一个或多个线程等待其他线程完成操作. package com.fuzhulei; import java.util.concurrent.*; /** * 减法计数器,主要是countDown(计数器1) 和 await(阻塞)方法,只有当计数器减为0的时候,当前线程才可以往下继续执行. * 主要用于允许一个或多个线程等待其他线程完成操作 * @author Huxudong * @cr
-

Java线程并发工具类CountDownLatch原理及用法
一.CountDownLatch [1]CountDownLatch是什么? CountDownLatch,英文翻译为倒计时锁存器,是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或 多个线程一直等待. 闭锁可以延迟线程的进度直到其到达终止状态,闭锁可以用来确保某些活动直到其他活动都完成才继续执行: 确保某个计算在其需要的所有资源都被初始化之后才继续执行; 确保某个服务在其依赖的所有其他服务都已经启动之后才启动; 等待直到某个操作所有参与者都准备就绪再继续执行: CountD
-
通俗易懂学习java并发工具类-Semaphore,Exchanger
1. 控制资源并发访问--Semaphore Semaphore可以理解为信号量,用于控制资源能够被并发访问的线程数量,以保证多个线程能够合理的使用特定资源. Semaphore就相当于一个许可证,线程需要先通过acquire方法获取该许可证,该线程才能继续往下执行,否则只能在该方法出阻塞等待.当执行完业务功能后,需要通过release()方法将许可证归还,以便其他线程能够获得许可证继续执行. Semaphore可以用于做流量控制,特别是公共资源有限的应用场景,比如数据库连接.假如有多个线程读取
-
android自动生成dimens适配文件的图文教程详解(无需Java工具类)
在编写ui界面时因为手机分辨率大小不同,所以展现出来的效果也是不同的,这个时候就需要考虑适配器,让根据手机分辨率自动适配相应尺寸来展示界面,可以提高用户的体验感. 1.首先安装插件ScreenMatch,安装成功之后android studio会提示重启 2.在res->values下创建一个dimens文件,将以下代码复制进去.如果不创建这个文件一下操作会不成功导致项目重启. <dimen name="common_margin">@dimen/dp_15</
-
Java使用Collections工具类对List集合进行排序
这篇文章主要介绍了Java使用Collections工具类对List集合进行排序,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.说明 使用Collections工具类的sort方法对list进行排序 新建比较器Comparator 二.代码 排序: import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import jav
-
Java并发编程中构建自定义同步工具
当Java类库没有提供适合的同步工具时,就需要构建自定义同步工具. 可阻塞状态依赖操作的结构 复制代码 代码如下: acquir lock on object state;//请求获取锁 while(precondition does not hold){//没有满足前提条件 release lock;//先释放锁 wait until precondition might hold;//等待满足前提条件 optionlly fail if interrupted or tim
-
了解JAVA并发工具常用设计套路
前言 在学习JAVA并发工具时,分析JUC下的源码,发现有三个利器:状态.队列.CAS. 状态 一般是state属性,如AQS源码中的状态,是整个工具的核心,一般操作的执行都要看当前状态是什么, 由于状态是多线程共享的,所以都是volatile修饰,保证线程直接内存可见. /** * AbstractQueuedSynchronizer中的状态 */ private volatile int state; /** * Status field, taking on only the values
-
Java并发工具类LongAdder原理实例解析
LongAdder实现原理图 高并发下N多线程同时去操作一个变量会造成大量线程CAS失败,然后处于自旋状态,导致严重浪费CPU资源,降低了并发性.既然AtomicLong性能问题是由于过多线程同时去竞争同一个变量的更新而降低的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源. LongAdder则是内部维护一个Cells数组,每个Cell里面有一个初始值为0的long型变量,在同等并发量的情况下,争夺单个变量的线程会减少,这是变相的减少了争夺共享资源的并发量,另外多个线程在争夺同
-
Java线程的并发工具类实现原理解析
目录 一.fork/join 1. Fork-Join原理 2. 工作窃取 3. 代码实现 二.CountDownLatch 三.CyclicBarrier 四.Semaphore 五.Exchange 六.Callable.Future.FutureTask 在JDK的并发包里提供了几个非常有用的并发工具类.CountDownLatch.CyclicBarrier和Semaphore工具类提供了一种并发流程控制的手段,Exchanger工具类则提供了在线程间交换数据的一种手段.本章会配合一些应
-
Java并发工具类Exchanger的相关知识总结
一.Exchanger的理解 Exchanger 属于java.util.concurrent包: Exchanger 是 JDK 1.5 开始提供的一个用于两个工作线程之间交换数据的封装工具类; 一个线程在完成一定的事务后想与另一个线程交换数据,则第一个先拿出数据的线程会一直等待第二个线程,直到第二个线程拿着数据到来时才能彼此交换对应数据. 二.Exchanger类中常用方法 public Exchanger() 无参构造方法.表示创建一个新的交换器. public V exchange(V
-
Java并发工具类Future使用示例
目录 前言 Future使用示例 FutureTask 前言 Future是一个接口类,定义了5个方法: boolean cancel(boolean mayInterruptIfRunning); boolean isCancelled(); boolean isDone(); V get() throws InterruptedException, ExecutionException; V get(long timeout, TimeUnit unit) throws Interrupte
-
Java JDK动态代理实现原理实例解析
JDK动态代理实现原理 动态代理机制 通过实现 InvocationHandler 接口创建自己的调用处理器 通过为 Proxy 类指定 ClassLoader 对象和一组 interface 来创建动态代理类 通过反射机制获得动态代理类的构造函数,其唯一参数类型是调用处理器接口类型 通过构造函数创建动态代理类实例,构造时调用处理器对象作为参数被传入 Interface InvocationHandler 该接口中仅定义了一个方法Object:invoke(Object obj,Method m
-
Java多线程锁机制相关原理实例解析
上下文:程序运行需要的环境(外部变量) 上下文切换:将之前的程序需要的外部变量复制保存,然后切换到新的程序运行环境 系统调用:(用户态陷入操作系统,通过操作系统执行内核态指令,执行完回到用户态)用户态--内核态--用户态:两次上下文切换 线程wait()方法:将自身加入等待队列,发生了一次上下文切换 notify()方法:将线程唤醒,也发生了上下文切换 Java线程中的锁:偏向锁.轻量级锁.重量级锁. 注意:偏向锁和轻量级锁都没有发生竞争,重量级锁发生了竞争. 偏向锁:可重入和经常使用某一个线程
-
Java链表元素查找实现原理实例解析
链表是一种物理存储单元上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针连接次序实现的. 每一个链表都包含多个节点,节点又包含两个部分,一个是数据域(储存节点含有的信息),一个是引用域(储存下一个节点或者上一个节点的地址). 以下实例演示了使用 linkedlistname.indexof(element) 和 linkedlistname.Lastindexof(elementname) 方法在链表中获取元素第一次和最后一次出现的位置: Main.java 文件 import j
-
Java main方法String[]args原理实例解析
一个程序中必定会有一个入口,java中main方法就是一个项目的的入口, public static void main(String[] args) {} eclipse的生成快捷键main+回车 ,idea的生成快捷键:psvm+回车 args数组是main方法自带的,我也不知道干什么的最近刷题遇到了三个有关的这个的题目看着我迷迷糊糊的记录一下 第一题: 第二题: 第三题 三个题都涉及了这个String[]args数组 下面以第二题为例简单说: 下面有一段代码,简单看看跟题目一样: publ