PyTorch 如何将CIFAR100数据按类标归类保存
few-shot learning的采样
Few-shot learning 基于任务对模型进行训练,在N-way-K-shot中,一个任务中的meta-training中含有N类,每一类抽取K个样本构成support set, query set则是在刚才抽取的N类剩余的样本中sample一定数量的样本(可以是均匀采样,也可以是不均匀采样)。
对数据按类标归类
针对上述情况,我们需要使用不同类别放置在不同文件夹的数据集。但有时,数据并没有按类放置,这时就需要对数据进行处理。
下面以CIFAR100为列(不含N-way-k-shot的采样):
import os
from skimage import io
import torchvision as tv
import numpy as np
import torch
def Cifar100(root):
character = [[] for i in range(100)]
train_set = tv.datasets.CIFAR100(root, train=True, download=True)
test_set = tv.datasets.CIFAR100(root, train=False, download=True)
dataset = []
for (X, Y) in zip(train_set.train_data, train_set.train_labels): # 将train_set的数据和label读入列表
dataset.append(list((X, Y)))
for (X, Y) in zip(test_set.test_data, test_set.test_labels): # 将test_set的数据和label读入列表
dataset.append(list((X, Y)))
for X, Y in dataset:
character[Y].append(X) # 32*32*3
character = np.array(character)
character = torch.from_numpy(character)
# 按类打乱
np.random.seed(6)
shuffle_class = np.arange(len(character))
np.random.shuffle(shuffle_class)
character = character[shuffle_class]
# shape = self.character.shape
# self.character = self.character.view(shape[0], shape[1], shape[4], shape[2], shape[3]) # 将数据转成channel在前
meta_training, meta_validation, meta_testing = \
character[:64], character[64:80], character[80:] # meta_training : meta_validation : Meta_testing = 64类:16类:20类
dataset = [] # 释放内存
character = []
os.mkdir(os.path.join(root, 'meta_training'))
for i, per_class in enumerate(meta_training):
character_path = os.path.join(root, 'meta_training', 'character_' + str(i))
os.mkdir(character_path)
for j, img in enumerate(per_class):
img_path = character_path + '/' + str(j) + ".jpg"
io.imsave(img_path, img)
os.mkdir(os.path.join(root, 'meta_validation'))
for i, per_class in enumerate(meta_validation):
character_path = os.path.join(root, 'meta_validation', 'character_' + str(i))
os.mkdir(character_path)
for j, img in enumerate(per_class):
img_path = character_path + '/' + str(j) + ".jpg"
io.imsave(img_path, img)
os.mkdir(os.path.join(root, 'meta_testing'))
for i, per_class in enumerate(meta_testing):
character_path = os.path.join(root, 'meta_testing', 'character_' + str(i))
os.mkdir(character_path)
for j, img in enumerate(per_class):
img_path = character_path + '/' + str(j) + ".jpg"
io.imsave(img_path, img)
if __name__ == '__main__':
root = '/home/xie/文档/datasets/cifar_100'
Cifar100(root)
print("-----------------")
补充:使用Pytorch对数据集CIFAR-10进行分类
主要是以下几个步骤:
1、下载并预处理数据集
2、定义网络结构
3、定义损失函数和优化器
4、训练网络并更新参数
5、测试网络效果
#数据加载和预处理
#使用CIFAR-10数据进行分类实验
import torch as t
import torchvision as tv
import torchvision.transforms as transforms
from torchvision.transforms import ToPILImage
show = ToPILImage() # 可以把Tensor转成Image,方便可视化
#定义对数据的预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)), #归一化
])
#训练集
trainset = tv.datasets.CIFAR10(
root = './data/',
train = True,
download = True,
transform = transform
)
trainloader = t.utils.data.DataLoader(
trainset,
batch_size = 4,
shuffle = True,
num_workers = 2,
)
#测试集
testset = tv.datasets.CIFAR10(
root = './data/',
train = False,
download = True,
transform = transform,
)
testloader = t.utils.data.DataLoader(
testset,
batch_size = 4,
shuffle = False,
num_workers = 2,
)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
初次下载需要一些时间,运行结束后,显示如下:

import torch.nn as nn
import torch.nn.functional as F
import time
start = time.time()#计时
#定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(3,6,5)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
x = F.max_pool2d(F.relu(self.conv1(x)),2)
x = F.max_pool2d(F.relu(self.conv2(x)),2)
x = x.view(x.size()[0],-1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
显示net结构如下:
#定义优化和损失
loss_func = nn.CrossEntropyLoss() #交叉熵损失函数
optimizer = t.optim.SGD(net.parameters(),lr = 0.001,momentum = 0.9)
#训练网络
for epoch in range(2):
running_loss = 0
for i,data in enumerate(trainloader,0):
inputs,labels = data
outputs = net(inputs)
loss = loss_func(outputs,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss +=loss.item()
if i%2000 ==1999:
print('epoch:',epoch+1,'|i:',i+1,'|loss:%.3f'%(running_loss/2000))
running_loss = 0.0
end = time.time()
time_using = end - start
print('finish training')
print('time:',time_using)
结果如下:

下一步进行使用测试集进行网络测试:
#测试网络
correct = 0 #定义的预测正确的图片数
total = 0#总共图片个数
with t.no_grad():
for data in testloader:
images,labels = data
outputs = net(images)
_,predict = t.max(outputs,1)
total += labels.size(0)
correct += (predict == labels).sum()
print('测试集中的准确率为:%d%%'%(100*correct/total))
结果如下:
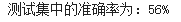
简单的网络训练确实要比10%的比例高一点:)
在GPU中训练:
#在GPU中训练
device = t.device('cuda:0' if t.cuda.is_available() else 'cpu')
net.to(device)
images = images.to(device)
labels = labels.to(device)
output = net(images)
loss = loss_func(output,labels)
loss
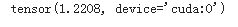
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Pytorch 实现数据集自定义读取
以读取VOC2012语义分割数据集为例,具体见代码注释: VocDataset.py from PIL import Image import torch import torch.utils.data as data import numpy as np import os import torchvision import torchvision.transforms as transforms import time #VOC数据集分类对应颜色标签 VOC_COLORMAP = [[0,
-
利用pytorch实现对CIFAR-10数据集的分类
步骤如下: 1.使用torchvision加载并预处理CIFAR-10数据集. 2.定义网络 3.定义损失函数和优化器 4.训练网络并更新网络参数 5.测试网络 运行环境: windows+python3.6.3+pycharm+pytorch0.3.0 import torchvision as tv import torchvision.transforms as transforms import torch as t from torchvision.transforms import
-
pytorch VGG11识别cifar10数据集(训练+预测单张输入图片操作)
首先这是VGG的结构图,VGG11则是红色框里的结构,共分五个block,如红框中的VGG11第一个block就是一个conv3-64卷积层: 一,写VGG代码时,首先定义一个 vgg_block(n,in,out)方法,用来构建VGG中每个block中的卷积核和池化层: n是这个block中卷积层的数目,in是输入的通道数,out是输出的通道数 有了block以后,我们还需要一个方法把形成的block叠在一起,我们定义这个方法叫vgg_stack: def vgg_stack(num_conv
-
PyTorch读取Cifar数据集并显示图片的实例讲解
首先了解一下需要的几个类所在的package from torchvision import transforms, datasets as ds from torch.utils.data import DataLoader import matplotlib.pyplot as plt import numpy as np #transform = transforms.Compose是把一系列图片操作组合起来,比如减去像素均值等. #DataLoader读入的数据类型是PIL.Image
-

PyTorch 如何将CIFAR100数据按类标归类保存
few-shot learning的采样 Few-shot learning 基于任务对模型进行训练,在N-way-K-shot中,一个任务中的meta-training中含有N类,每一类抽取K个样本构成support set, query set则是在刚才抽取的N类剩余的样本中sample一定数量的样本(可以是均匀采样,也可以是不均匀采样). 对数据按类标归类 针对上述情况,我们需要使用不同类别放置在不同文件夹的数据集.但有时,数据并没有按类放置,这时就需要对数据进行处理. 下面以CIFAR1
-
php实现的返回数据格式化类实例
本文实例讲述了php实现的返回数据格式化类及其用法,在字符串处理中非常具有实用价值.分享给大家供大家参考.具体方法如下: DataReturn.class.php类文件如下: <?php /** 返回数据格式化类 * Date: 2011-08-15 * Author: fdipzone */ class DataReturn{ // class start private $type; private $xmlroot; private $callback; private $returnDa
-
Yii框架批量插入数据扩展类的简单实现方法
本文实例讲述了Yii框架批量插入数据扩展类的简单实现方法.分享给大家供大家参考,具体如下: MySQL INSERT语句允许插入多行数据,如下所示: INSERT INTO tbl_name (a,b,c) VALUES(1,2,3),(4,5,6),(7,8,9); 那么要实现批量插入,主要的任务就是按照列顺序,把数据组装成上述格式即可,可以使用sprintf和vsprintf函数来实现. 下面是一个实现批量插入的Yii扩展类的简单示例(支持VARCHAR类型数据): <?php /** *
-
asp的通用数据分页类
(原创)<!--#include file="Conn.asp" --> 通用数据分页类 通用分页类,以后写分页显示数据时就轻松多啦.直接调用此类,然后再Execute即可以取得当前页的所有数据. 此类所做的工作是只取得当前页的数据,和总页数和总记录数等等数据. ASP代码: <% '/*****************************分页显示类************************** '/* 作者:哇哇鱼 '/* 日期:2004年
-
C#实现操作MySql数据层类MysqlHelper实例
本文实例讲述了C#实现操作MySql数据层类MysqlHelper.分享给大家供大家参考.具体如下: using System; using System.Data; using System.Configuration; using System.Collections.Generic; using System.Linq; using System.Text; using System.Xml.Linq; using MySql.Data; using MySql.Data.MySqlCli
-
PHP解析xml格式数据工具类示例
本文实例讲述了PHP解析xml格式数据工具类.分享给大家供大家参考,具体如下: class ome_xml { /** * xml资源 * * @var resource * @see xml_parser_create() */ public $parser; /** * 资源编码 * * @var string */ public $srcenc; /** * target encoding * * @var string */ public $dstenc; /** * the origi
-
pytorch 图像中的数据预处理和批标准化实例
目前数据预处理最常见的方法就是中心化和标准化. 中心化相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征. 标准化也非常简单,在数据变成 0 均值之后,为了使得不同的特征维度有着相同的规模,可以除以标准差近似为一个标准正态分布,也可以依据最大值和最小值将其转化为 -1 ~ 1 之间 批标准化:BN 在数据预处理的时候,我们尽量输入特征不相关且满足一个标准的正态分布,这样模型的表现一般也较好.但是对于很深的网路结构,网路的非线性层会使得输出的结
-
PyTorch中Tensor的数据统计示例
张量范数:torch.norm(input, p=2) → float 返回输入张量 input 的 p 范数 举个例子: >>> import torch >>> a = torch.full([8], 1) >>> b = a.view(2, 4) >>> c = a.view(2, 2, 2) >>> a.norm(1), b.norm(1), c.norm(1) # 求 1- 范数 (tensor(8.),
-
Java 如何读取Excel格式xls、xlsx数据工具类
目录 Java 读取Excel格式xls.xlsx数据工具类 需要POI的jar包支持 调用方式 使用poi读取xlsx格式的Excel总结 今天遇到的坑 我使用的是springmvc,首先是controller部分 然后是读取Excel文件部分,也就是service部分 spring-servlet.xml 配置如下 最初的maven是这么配置的 Java 读取Excel格式xls.xlsx数据工具类 需要POI的jar包支持 调用方式 ReadExcelTest excelTest = ne
-
浅谈pytorch 模型 .pt, .pth, .pkl的区别及模型保存方式
我们经常会看到后缀名为.pt, .pth, .pkl的pytorch模型文件,这几种模型文件在格式上有什么区别吗? 其实它们并不是在格式上有区别,只是后缀不同而已(仅此而已),在用torch.save()函数保存模型文件时,各人有不同的喜好,有些人喜欢用.pt后缀,有些人喜欢用.pth或.pkl.用相同的torch.save()语句保存出来的模型文件没有什么不同. 在pytorch官方的文档/代码里,有用.pt的,也有用.pth的.一般惯例是使用.pth,但是官方文档里貌似.pt更多,而且官方也