R语言-如何循环读取excel并保存为RData
之前写过一个循环读取excel的代码,最近又有了新的需求:循环读取xlsx文件中的多个sheet,处理完之后循环输出到xlsx文件中的多个sheet中,总结一下。
1、循环读取csv文件并输出为RData格式
homedir <- "D:/Documents/tina/Database" #设置路径
setwd(homedir)
temp = list.files(pattern="*.csv")
for (i in 1:length(temp)) {
filename <- substr(temp[i], 1, nchar(temp[i])-4);
assign(filename, read.csv(temp[i], header = T));
save(list = filename, file = paste(filename, ".Rdata", sep = ""))
}
有了这段代码,要循环读取xlsx里面的多个sheet就简单多了,毕竟xlsx的文件名都是一致的,只是sheetIndex不一样:
2、循环读取xlsx文件中的多个sheet:
library(xlsx)
sheet.index <- c(1:12)
data.list <- list()
for(i in sheet.index){
filename <- paste0("month",i)
data.list[[i]] <- read.xlsx("E:/某某中心年收入.xls", encoding = "UTF-8", sheetIndex = i)
assign(filename, data.list[[i]])
}
下面这面这段代码是抄来的,还没来得及尝试能不能循环写入sheet了。
3、循环创建xlsx中的多个sheet
library(XLConnect)
wb <- loadWorkbook('data.xlsx', create = TRUE) # 创建excel工作簿
# 创建sheet
for (name in paste0('sheet', 1:3)) {
createSheet(wb, name)
}
# 分别向3个sheet写入数据
writeWorksheet(wb, data_frame_1, 'sheet1')
writeWorksheet(wb, data_frame_2, 'sheet2')
writeWorksheet(wb, data_frame_3, 'sheet3')
saveWorkbook(wb)
今天尝试了第3部分的代码,发现循环写入的功能无法实现,于是使用openxlsx包解决该问题。
4、创建xlsx,写入多个sheet
首先按照网上的教程安装了openxlsx,并进行了实验:
library(openxlsx)
wb <- createWorkbook()
addWorksheet(wb, "Sheet 1")
c1 <- createComment(comment = "this is comment")
writeComment(wb, 1, col = "B", row = 10, comment = c1)
s1 <- createStyle(fontSize = 12, fontColour = "red", textDecoration = c("BOLD"))
s2 <- createStyle(fontSize = 9, fontColour = "black")
c2 <- createComment(comment = c("This Part Bold red\n\n", "This part black"), style = c(s1, s2))
c2
writeComment(wb, 1, col = 6 , row = 3, comment = c2)
addWorksheet(wb, "Sheet 1")
saveWorkbook(wb, file = "E:/信和资料/项目/门店绩效/湖南益阳/writeCommentExample.xlsx", overwrite = TRUE)
但在最后保存时报错,因为是在windows环境下,保存时提示安装Rtools,windows系统下安装完成后,需要添加系统变量D:\Rtools\bin;D:\Rtools\gcc-4.6.3\bin,添加完成后,重启电脑,发现保存成功。
下面,需要循环将多个sheet写入xlsx文件中:
wb <- createWorkbook() addWorksheet(wb,"xsjshouru12") addWorksheet(wb, "xsjshouru18") addWorksheet(wb, "xsjshouru24") addWorksheet(wb, "xsjshouru36") writeData(wb,"xsjshouru12",xsjshouru12) writeData(wb,"xsjshouru18",xsjshouru18) writeData(wb,"xsjshouru24",xsjshouru24) writeData(wb,"xsjshouru36",xsjshouru36) #保存到本地文件 saveWorkbook(wb,file = "E:/信和资料/项目/门店绩效/湖南益阳/薪水借.xlsx", overwrite = TRUE)
读入数据:
files = list.files(pattern='*.Rdata') fload = lapply(files, function(x) get(load(x)))
合并多个数据框
edata4 <- Reduce(function(x,y) merge(x = x, y = y, by = c('lon','lat')),list(dtr01, dtr02, dtr03))
补充:R语言:批量循环读取一系列excel文件
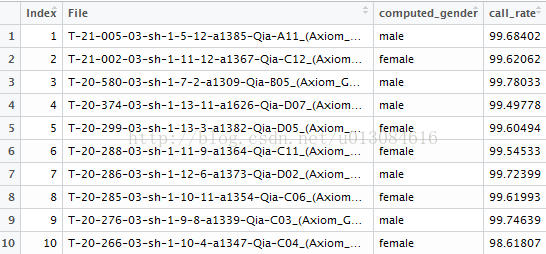
例如有20个excel文件分别代表20个亚组的数据,文件名为亚组名P01-P20,每个文件中的变量个数和名称等都是相同的,可通过以下命令实现一次性读取20个excel,并生成一个新变量提示来自哪个亚组(同时展示如何读取每个excel第二列数据的前11个字符生成一个新变量id)。
例如P01数据如下:
首先
读取excel文件先要安装package: XLConnect:
install.packages(XLConnect) library(XLConnect)
其次
生成代表亚组名称的新变量和第二列前11个字符的新变量:
temp<-list.files(pattern="*.xls") //生成一个新变量temp代表文件路径中所有后缀为xls的文件的文件名 head(temp) a=readWorksheetFromFile(temp[1],sheet=1) //读取temp1号excel即P01,命名为数据库a a$plate=substr(as.character(temp[1]),1,3) //生成变量plate,数值为temp里的plate名称(字符1到3) a$id=substr(a[,2],1,11) //生成变量id, 值为第二列数据的前11个字符 ncol(a) //看看a有多少个变量,新生成的plate和id变量为最后两个,假设为第58和59个变量 write.table(a[,c(58,59)],file = "newfile.txt",row.names=F, na="",col.names=FALSE, sep=" ",append = T,quote=F) //生成txt文件newfile.txt为p01文件中的plate和id,展示如下
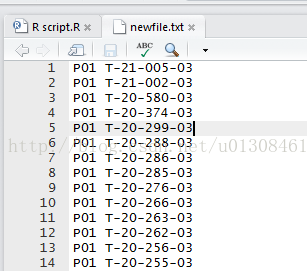
最后
对P02-20写一个for循环语句,导入进去即可
for (i in 2: length(temp)){
newfile=read.table("newfile.txt")
b=readWorksheetFromFile(temp[i],sheet=1)
b$row=substr(as.character(temp[i]),1,3)
b$extract=substr(b[,2],1,11)
write.table(b[,c(58,59)],file = "newfile.txt",row.names=F, na="",col.names=FALSE, sep=" ",append = T,quote=F)
}
命令翻译:对每一个i值,i从2到temp的最大值之间取值,生成一个文件newfile=之前P01的txt文件,下面四行是重复上面生成P01file的过程。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

解决R语言中install_github中无法安装遇到的问题
首先,让我们来进入常规步骤 我安装的是recharts包,正常的写法呢,就是以下这个样子: install.packages("devtools") #devtools::install_github("madlogos/recharts") 第一个问题: 然而对于今天的我来说,那就太天真了,首先踏入的第一个坑: 无法打开URL'http://yihui.name/xran/src/contrib/PACKAGES' Warning in install.packa
-
R语言中if(){}else{}语句和ifelse()函数的区别详解
首先看看定义: # if statement if(cond) expr if(cond) cons.expr else alt.expr # ifelse function ifelse(test, yes, no) 这两个函数(R语言中都是函数)相同的地方都是根据条件返回对应的值. 区别在于: if语句的条件是个TRUE/FALSE值,如果是个长度>1的逻辑向量,只判断第一个TRUE/FALSE值:而ifelse是长度任意的逻辑向量,返回根据逻辑向量对应对的yes/no值组合的新向量 ife
-
R语言ARMA模型的参数选择说明
AR(p)模型与MA(q)实际上是ARMA(p,q)模型的特例.它们都统称为ARMA模型,而ARMA(p,q)模型的统计性质也是AR(p)与MA(q)模型的统计性质的有机组合. 平稳系列建模 假如某个观察值序列通过序列预处理可以判定为平稳非白噪声序列,就可以利用ARMA模型对序列建模. 1.求出该观察值序列的样本自相关系数(ACF)与偏相关系数(PACF的值. 2.根据根样本自相关系数和偏自相关系数的性质,选择阶数适当的ARMA(p,q)模型进行拟合. 3.估计模型中未知参数的值 4.检验模型的
-
R语言实现用cbind合并两列数据
我有两个数据文件,分别只有一列,这两列数据行数一行,我想把这两列合并到一个数据文件中,方便使用. 我的两个数据文件分别是1.txt,2.txt,保存后的文件名是3.txt. // 代码如下 gow1<-read.table("1.txt",header = FALSE) gow2<-read.table("2.txt",header = FALSE) View(gow1) View(gow2) gow<-cbind(gow1,gow2) View(
-
R语言绘制频率直方图的案例
频率直方图是数据统计中经常会用到的图形展示方式,同时在生物学分析中可以更好的展示表型性状的数据分布类型:R基础做图中的hist函数对单一数据的展示很方便,但是当遇到多组数据的时候就不如ggplot2绘制来的方便. *** 1.基础做图hist函数 hist(rnorm(200),col='blue',border='yellow',main='',xlab='') 1.1 多图展示 par(mfrow=c(2,3)) for (i in 1:6) {hist(rnorm(200),border=
-
R语言中ifelse、which、%in%的用法详解
ifelse.which.%in%是R语言里极其重要的函数,以后会经常在别的程序中看到. ifelse ifelse是if条件判断语句的简写,它的用法如下: ifelse(test,yes,no) 参数 描述 test 一个可以判断逻辑表达式 yes 判断为 true 后返回的对象 no 判断为 flase 后返回的对象 举例: x = 5 ifelse(x,1,0) 如果x不等于0,就返回1,等于0就返回0. which which 返回条件为真的句柄,给正确的逻辑对象返回一个它的索引. wh
-
R语言中na.fail和na.omit的用法
实际工作中,数据集很少是完整的,许多情况下样本中都会包括若干缺失值NA,这在进行数据分析和挖掘时比较麻烦. R语言通过na.fail和na.omit可以很好地处理样本中的缺失值 1.na.fail(<向量a>): 如果向量a内包括至少1个NA,则返回错误:如果不包括任何NA,则返回原有向量a 2.na.omit(<向量a>): 返回删除NA后的向量a 3.attr( na.omit(<向量a>) ,"na.action"): 返回向量a中元素为NA的
-
R语言-使用ifelse进行数据分组
数据分组,根据数据分析对象的特征,按照一定的数值指标,把数据分析对象划分为不同的区间部分来研究,以揭示内在的联系和规律性: 在R中,我们常用ifelse函数来进行数据的分组,跟excel中的if函数是同一种用法. ifelse(condition,TRUE,FALSE) > data <- read.table('1.csv', sep='|', header=TRUE); > > level <- ifelse( + data$cost<=20, "(0,2
-
R语言-计算频数和频率的操作
首先,筛选出需要的列: data <- data2[,which(colnames(data2) %in% c("产品分类", "期数", "逾期月数"))] 产品分类 期数 逾期月数 委托贷款 24 1 委托贷款 36 1 担保贷款 24 2 委托贷款 24 2 信用贷款 36 4 担保贷款 24 3 信用贷款 24 1 委托贷款 36 3 担保贷款 24 2 现在希望得到每种产品种类在不同期数时 逾期月数的占比,使用table函数: #
-
R语言-如何循环读取excel并保存为RData
之前写过一个循环读取excel的代码,最近又有了新的需求:循环读取xlsx文件中的多个sheet,处理完之后循环输出到xlsx文件中的多个sheet中,总结一下. 1.循环读取csv文件并输出为RData格式 homedir <- "D:/Documents/tina/Database" #设置路径 setwd(homedir) temp = list.files(pattern="*.csv") for (i in 1:length(temp)) { fil
-
python3 循环读取excel文件并写入json操作
文件内容: excel内容: 代码: import xlrd import json import operator def read_xlsx(filename): # 打开excel文件 data1 = xlrd.open_workbook(filename) # 读取第一个工作表 table = data1.sheets()[0] # 统计行数 n_rows = table.nrows data = [] # 微信文章属性:wechat_name wechat_id title abstr
-
R语言如何将大型Excel文件转为dta格式详解
本文以2000年度我国工业企业数据库为例,该文件后缀名为xlsx,包含约16万条记录,文件有88M这么大.直接使用Excel打开都费劲:等待时间久,电脑风扇呼呼呼作响.如果尝试用Stata打开该xlsx文件,则会出现提示报错. 报错原因在于,Stata无法读取超过40M的Excel文件. 这就好比瓜迪奥拉的传控足球固然美丽,但是面对摆大巴的球队无能为力. 破大巴需要攻城锤,这把锤子的名字就是R语言.万事开头难啊,正憧憬着数据清洗和花式选取变量建模呢,可不能连数据们长啥模样都没见着啊.R语言适时挺
-
基于R语言for循环的替换方案
R语言中,for循环运行比较慢 for(i in 1:1000){ print(i^2) } 补充:R语言:for循环使用小结 基本结构展示: vals =c(5,6,7) for(v in vals){ print(v) } #即把大括号里的内容对vals里的每一个值都循环run一遍 实例展示: 1. paste() 命令是把几个字符连接起来 如paste("A","B","C",sep=" ")得到的就是"A B
-
Java用jxl读取excel并保存到数据库的方法
项目中涉及到读取excel中的数据,保存到数据库中,用jxl做起来比较简单. 基本的思路: 把excel放到固定盘里,然后前段页面选择文件,把文件的名字传到后台,再利用jxl进行数据读取,把读取到的数据存到list中,通过遍历list,得到map,存到数据库中. 首先导入jar包:在网上都有, 代码: 页面: 新模excel导入 <input type="file" name="excel" id="xinmu"> <input
-
可以读取EXCEL文件的js代码第1/2页
首页给个有中文说明的例子,下面的例子很多大家可以多测试. 复制代码 代码如下: <script language="javascript" type="text/javascript"><!-- function readExcel() { var excelApp; var excelWorkBook; var excelSheet; try{ excelApp = new ActiveXObject("Excel.Applicatio
-
R语言条形图创建方法
条形图表示矩形条中的数据,条的长度与变量的值成比例. R语言使用函数 barplot() 创建条形图. R 语言可以在条形图中绘制垂直和水平条. 在条形图中,每个条可以给予不同的颜色. 语法 在 R 语言中创建条形图的基本语法是 H 是包含在条形图中使用的数值的向量或矩阵. xlab 是 x 轴的标签. ylab 是 y 轴的标签. main 是条形图的标题. names.arg 是在每个条下出现的名称的向量. col 用于向图中的条形提供颜色. barplot(H, xlab, ylab, m
-
C#使用NPOI读取excel转为DataSet
本文实例为大家分享了C#使用NPOI读取excel转为DataSet的具体代码,供大家参考,具体内容如下 NPOI读取excel转为DataSet /// <summary> /// 读取Execl数据到DataTable(DataSet)中 /// </summary> /// <param name="filePath">指定Execl文件路径</param> /// <param name="isFirstLineC
-
R语言数据读取以及数据保存方式
一.R语言读取文本文件: 1.文件目录操作: getwd() : 返回当前工作目录 setwd("d:/data") 更改工作目录 2.常用的读取指令read read.table() : 读取文本文件 read.csv(): 读取csv文件 如果出现缺失值,read.table()会报错,read.csv()读取时会自动在缺失的位置填补NA 3.灵活的读取指令 scan() : 4.读取固定宽度格式的文件: read.fwf() 文本文档中最后一行的回车符很重要,这是一个类似于停止符
-
R语言读取excel数据的方法(两行命令)
安装库 安装xlsx install.packages("xlsx") 使用 library(xlsx) ray = read.xlsx('D:/Code/R/Data in Excel/Chapter 8/gamma-ray.xls',1) 后面的参数,第一个放地址,第二个放具体sheet页(这里除了可以放数值之外,还可以放对应的名字(字符串)).除此之外,还可以使用encoding="utf-8"的方式来定义使用中文数据. 效果: > a = read.x