pandas数据处理清洗实现中文地址拆分案例
目录
- 一、案例场景
- 二、初步方案
- 三、优化方案
一、案例场景
字段login_place,一共267725行记录,随机15条记录如下:

后续数据分析工作需要用到地理维度进行分析,所以需要把login_place字段进行拆分成:国家、省份、地区。
二、初步方案
第三方中文分词库:jieba,可以对文本进行拆分。使用参考资料:jieba库的使用。
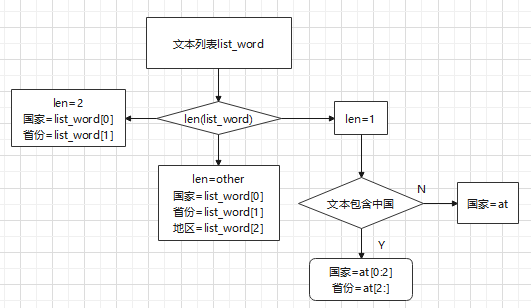
初步方案:
- 用jieba.cut()将文本拆分为单词列表list_word;
- 分支判断list_word长度,赋值国家、城市、地区。
代码:(抽取1000条记录,看一下我这台机器的运行时间)
%%time
# 地区拆分
for i in range(1000):
list_word=[word for word in jieba.cut(df.iloc[i,0])]
if len(list_word)==1:
if '中国' in df.iloc[i,0]:
df.loc[i,'国家']=df.iloc[i,0][0:2]
df.loc[i,'省份']=df.iloc[i,0][2:]
else:
df.loc[i,'国家']=df.iloc[i,0]
elif len(list_word)==2:
df.loc[i,'国家']=list_word[0]
df.loc[i,'省份']=list_word[1]
else:
df.loc[i,'国家']=list_word[0]
df.loc[i,'省份']=list_word[1]
df.loc[i,'地区']=list_word[2]
if i%100==0:
print(f'{round(i*100/(int(1000)),2)}%')

1000条用了1min 37秒。如果全部进行数据解析等待时间应该很久很久。有很多重复的记录,这里先去重,再跑一次代码。

去重之后,只有404不重复的记录。
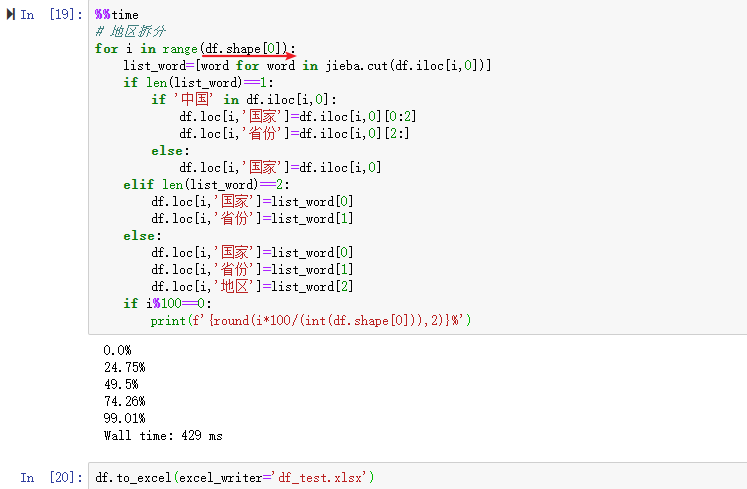
再跑一遍代码,并且把结果保存到本地文件‘df_test.xlsx'。便于查看jieba第三方分词库对本次数据拆分是不是想要的结果。
国家:
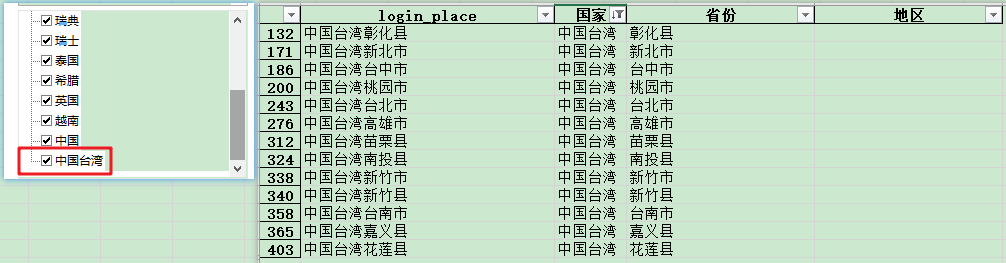
‘国家'这一列,中国台湾没有拆分出来。

代码试了一下,发现‘中国台湾'确实拆分不了。证实了台湾确实中国不可缺失的一部分。
省份:

‘省份'这一列拆分的更加糟糕。
总结:总数据集运行时间长,切词不准确。需要优化拆分方案!
三、优化方案
在上面查看Excel文件时候发现‘login_place'字段的数据有以下特点:
- 整个数据集分类两类:‘中国'和外国;
- 中国的省份大多是两个字,除了‘黑龙江'和‘内蒙古';
- 外国的,只有国家记录。
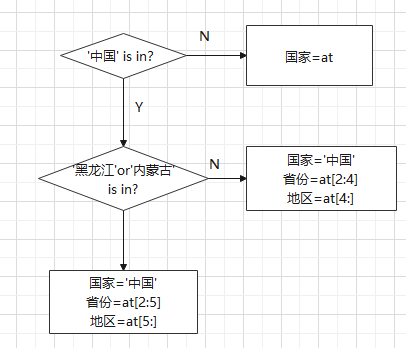
优化方案:
- 对国家判断,形成分支:中国和外国;
- 对于中国,再判断省份是不是‘黑龙江'和‘内蒙古'。
- 不是:可以直接切分[2:4],提取省份。[4:],提取地区;
- 是:[2:5]提取省份。[5:]提取地区
%%time
# 地区拆分
for i in range(df.shape[0]):
if '中国' in df.iloc[i,0] :
df.loc[i,'国家'] = '中国'
if ('内蒙古' in df.iloc[i,0]) or ('黑龙江' in df.iloc[i,0]):
# print(df.iloc[i,0])
df.loc[i,'省份'] = df.iloc[i,0][2:5]
if len(df.iloc[i,0]) > 5:
df.loc[i,'地区'] = df.iloc[i,0][5:]
else:
df.loc[i,'省份'] = df.iloc[i,0][2:4]
df.loc[i,'地区'] = df.iloc[i,0][4:]
else:
list_word = [word for word in jieba.cut(df.iloc[i,0])]
if len(list_word) == 1:
df.loc[i,'国家'] = df.iloc[i,0][0:2]
df.loc[i,'省份'] = df.iloc[i,0][2:]
else:
df.loc[i,'国家'] = list_word[0]
df.loc[i,'省份'] = list_word[1]
if i%100==0:
print(f'{round(i*100/(int(df.shape[0])),2)}%')
保存Excel文件,再次查看拆分情况。经过去重后的测试集拆分符合想要的结果。
运行未去重源数据集结果:

到此这篇关于pandas数据处理清洗实现中文地址拆分案例的文章就介绍到这了,更多相关pandas 中文地址拆分内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python Pandas list列表数据列拆分成多行的方法实现
1.实现的效果 示例代码: df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]}) df Out[458]: A B 0 1 [1, 2] 1 2 [1, 2] 拆分成多行的效果: A B 0 1 1 1 1 2 3 2 1 4 2 2 2.拆分成多行的方法 1)通过apply和pd.Series实现 容易理解,但在性能方面不推荐. df.set_index('A').B.apply(pd.Series).stack().reset_ind
-
利用python Pandas实现批量拆分Excel与合并Excel
一.实例演示 1.将一个大Excel等份拆成多个Excel 2.将多个小Excel合并成一个大Excel并标记来源 work_dir="./course_datas/c15_excel_split_merge" splits_dir=f"{work_dir}/splits" import os if not os.path.exists(splits_dir): os.mkdir(splits_dir) 二.读取源Excel到Pandas import pandas
-
对numpy和pandas中数组的合并和拆分详解
合并 numpy中 numpy中可以通过concatenate,指定参数axis=0 或者 axis=1,在纵轴和横轴上合并两个数组. import numpy as np import pandas as pd arr1=np.ones((3,5)) arr1 Out[5]: array([[ 1., 1., 1., 1., 1.], [ 1., 1., 1., 1., 1.], [ 1., 1., 1., 1., 1.]]) arr2=np.random.randn(15).reshape(
-

pandas将list数据拆分成行或列的实现
数据 import numpy as np import pandas as pd data = [{'Name': '小明', 'Chinese': [70, 80], 'Math': [90, 80]}, {'Name': '小红', 'Chinese': [70, 80, 90], 'Math': [90, 80, 70]}] data = pd.DataFrame(data) data 拆分成行 def split_row(data, column): '''拆分成行 :param da
-
pandas数据处理清洗实现中文地址拆分案例
目录 一.案例场景 二.初步方案 三.优化方案 一.案例场景 字段login_place,一共267725行记录,随机15条记录如下: 后续数据分析工作需要用到地理维度进行分析,所以需要把login_place字段进行拆分成:国家.省份.地区. 二.初步方案 第三方中文分词库:jieba,可以对文本进行拆分.使用参考资料:jieba库的使用. 初步方案: 用jieba.cut()将文本拆分为单词列表list_word; 分支判断list_word长度,赋值国家.城市.地区. 代码:(抽取
-
六个实用Pandas数据处理代码
目录 选取有空值的行 快速替换列值 对列进行分区 将一列分为多列 中文筛选 更改列的位置 前言: 今天和大家分享自己总结的6个常用的Pandas数据处理代码,对于经常处理数据的coder最好熟练掌握. 选取有空值的行 在观察数据结构时,该方法可以快速定位存在缺失值的行. df = pd.DataFrame({'A': [0, 1, 2], 'B': [0, 1, None], 'C': [0, None, 2]}) df[df.isnull().T.any()] 输出: A B C
-
Python Pandas数据处理高频操作详解
目录 引入依赖 算法相关依赖 获取数据 生成df 重命名列 增加列 缺失值处理 独热编码 替换值 删除列 数据筛选 差值计算 数据修改 时间格式转换 设置索引列 折线图 散点图 柱状图 热力图 66个最常用的pandas数据分析函数 从各种不同的来源和格式导入数据 导出数据 创建测试对象 查看.检查数据 数据选取 数据清理 筛选,排序和分组依据 数据合并 数据统计 16个函数,用于数据清洗 1.cat函数 2.contains 3.startswith/endswith 4.count 5.ge
-
python pandas数据处理之删除特定行与列
目录 dropna() 方法过滤任何含有缺失值的行 方法一:dropna() 其他参数解析 方法二:替换并删除,Python pandas 如果某列值为空,过滤删除所在行数据 总结 dropna() 方法过滤任何含有缺失值的行 pandas.DataFrame里,如果一行数据有任意值为空,则过滤掉整行,这时候使用dropna()方法是合适的.下面的案例,任意列只要有一个为空数据,则整行都干掉.但是我们常常遇到的情况,是根据一个指标(一列)数据的情况,去过滤行数据,类似Excel里面的过滤漏斗,怎
-
pandas数据处理基础之筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 1.重新索引:reindex和ix 上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号.列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子. 1.1 Series 比方说:data=Series([4,5,6],index=['a',
-
Pandas 数据处理,数据清洗详解
如下所示: # -*-coding:utf-8-*- from pandas import DataFrame import pandas as pd import numpy as np """ 获取行列数据 """ df = DataFrame(np.random.rand(4, 5), columns=['A', 'B', 'C', 'D', 'E']) print df print df['col_sum'] = df.apply(lam
-
在python中pandas读文件,有中文字符的方法
后面要加encoding='gbk' import pandas as pd datt=pd.read_csv('D:\python_prj_1\data_1.txt',encoding='gbk') print(datt) 以上这篇在python中pandas读文件,有中文字符的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
解决pandas 作图无法显示中文的问题
最近开始使用 pandas 处理可视化数据,挖掘信息.但是在作图时遇到,无法显示中文的问题. 下面这段代码是统计 fujian1.csv 文件中 City 所在列中各个城市出现次数的代码.可是作图直方图时在 x 轴上无法显示中文. import pandas as pd # Reading data locally df = pd.read_csv('fujian1.csv', encoding='gbk') counts = df['City'].value_counts() counts[c
-
pandas数据处理之绘图的实现
Pandas是Python中非常常用的数据处理工具,使用起来非常方便.它建立在NumPy数组结构之上,所以它的很多操作通过NumPy或者Pandas自带的扩展模块编写,这些模块用Cython编写并编译到C,并且在C上执行,因此也保证了处理速度. 今天我们就来体验一下它的强大之处. 1.创建数据 使用pandas可以很方便地进行数据创建,现在让我们创建一个5列1000行的pandas DataFrame: mu1, sigma1 = 0, 0.1 mu2, sigma2 = 0.2, 0.2 n