python 在服务器上调用数据库特别慢的解决过程
在排除网络和环境配置问题后,如果发现本地调试比较快,而部署到服务器就会出现卡顿现象,可以检查下在上传服务器时,是否将连接mysql 的IP改为:localhoast、或者unix_socket 方式连接。
本地调试需要使用服务器ip地址!
更改如下:

补充:服务器响应慢问题
一.分析思路
1.排除本机自身原因
2.服务器性能分析
3.项目本身分析(不详细说)
4.虚拟机分析
5.数据库分析
二.详细分析方法
1.排除本机自身原因
可以使用站长工具测试网站速度。
2.服务器性能分析
使用top命令查看服务器的资源使用情况,主要分析CPU和内存的使用情况(top 命令是 Linux 下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,默认5秒刷新一下进程列表,所以类似于 Windows 的任务管理器。):
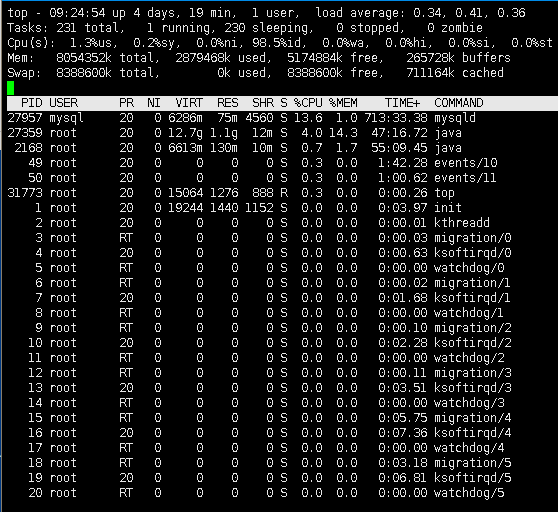
第三行显示的是Cpu的使用情况,详细含义如下:
us---用户空间占用CPU的百分比、sy---内核空间占用CPU的百分比、ni---改变过优先级的进程占用CPU的百分比、id---空闲CPU百分比、wa---IO等待占用CPU的百分比、hi---硬中断(Hardware IRQ)占用CPU的百分比、si---软中断(Software Interrupts)占用CPU的百分比、st---Steal Time,分配给运行在主机上其它虚拟机的任务的实际CPU时间,一般只有在虚拟机OS。
第4行是当前的内存情况,服务器总内存8054352k,已使用2879468k,剩余5174884k,缓冲265728k。
我个人的理解是:当us的百分比小于50%时,是不需要去考虑服务器的配置问题的,如果服务器的us百分比长时间在70%以上时,可以考虑加强服务器的硬件配置。此外,还需要查看服务器的网络情况,下载一个大型文件基本就可以确定网络情况了。
3.项目本身分析
如果使用JDBC连接池,需要对连接池的配置进行分析(分析线程池的最大数量和释放时间等等)。
这里以C3P0为例,下面是我曾经做的一个项目的配置,如下图:

这里本来只是本地测试的配置方案,由于粗心,上线后忘记修改了,当多人访问时,会出现等待连接超时的情况,我们需要根据项目的实际情况设定合适的配置数据。
还有可能项目的设计方面不合理导致响应缓慢,这里就不详细说明了。
checkoutTimeout---当连接池连接耗尽时,客户端调用getConnection()后等待获取新连接的时间,超时后将抛出SQLException,如设为0则无限期等待。单位毫秒。默认: 0
minPoolSize---连接池中保留的最小连接数,默认为:3
maxPoolSize---连接池中保留的最大连接数。默认值: 15
maxIdleTime---最大空闲时间,设定时间内未使用则连接被丢弃。若为0则永不丢弃。默认值: 0
maxIdleTimeExcessConnections---default : 0 单位 s 这个配置主要是为了减轻连接池的负载,比如连接池中连接数因为某次数据访问高峰导致创建了很多数据连接 ,但是后面的时间段需要的数据库连接数很少,则此时连接池完全没有必要维护那么多的连接,所以有必要将断开丢弃掉一些连接来减轻负载,必须小于maxIdleTime。配置不为0,则会将连接池中的连接数量保持到minPoolSize。为0则不处理
acquireIncrement---当连接池中的连接耗尽的时候c3p0一次同时获取的连接数。默认值: 3
4.虚拟机分析
使用top指令查看虚拟机的内存占用情况,有时候可以发现虽然虚拟机占用内存的百分比不大却有明显的上限值,我们就需要去查看虚拟机的配置情况。
解决方法(以tomcat为例):

具体的数值根据实际情况而定。
5.数据库分析(MySql)
数据库的分析内容和需要考虑的方面有很多,这里只说本人遇到过的几种情况:
a.最大连接数
show variables like '%max_connections%'; 查看最大连接数 show status like 'Threads%';当前连接的使用情况
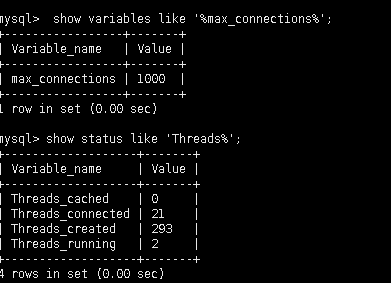
Threads_connected---打开的连接数
Threads_running---这个数值指的是激活的连接数,这个数值一般远低于connected数值
如果最大连接数的值太小可以根据实际情况进行修改,一般修改为1000即可,设置方法有两种:
1.临时设置,重启服务后将失效

2.修改数据库配置文件
在/etc/my.cnf 文件的[mysqld]下增减一行:max_connections = 1000
b.超时控制
mysql存在一项属性“wait_timeout”,默认值为28800秒(8小时),wait_timeout的值可以设定,但最多只能是2147483,不能再大了。也就是约24.85天 ,可以通过show global variables like 'wait_timeout';命令来查看。
wait_timeout的含义是:一个connection空闲超过8个小时,Mysql将自动断开该connection,通俗的讲就是一个连接在8小时内没有活动,就会自动断开该连接。由于dbcp没有检验该connection是否有效,用其进行数据操作便会出现异常。
如果是由超时控制引起的问题,不建议修改wait_timeout的值,在数据库连接的url的后面加上“&autoReconnect=true&failOverReadOnly=false”即可解决。
c.DNS反向解析
MySQL数据库收到一个网络连接后,首先拿到对方的IP地址,然后对这个IP地址进行反向DNS解析从而得到这个IP地址对应的主机名。用主机名在权限系统里面进行权限判断。反向DNS解析是耗费时间的,有可能让用户感觉起来很慢。甚至有的时候,反向解析出来的主机名并没有指向这个IP地址,这时候就无法连接成功了。 可以在配置文件里面禁止MySQL进行反向DNS解析,只需在my.cnf的[mysqld]段落中加入如下行即可:
skip-name-resolve (windows与linux下一样的)
d.表高速缓存
show global status like 'open%tables%';查看打开的表的数量:
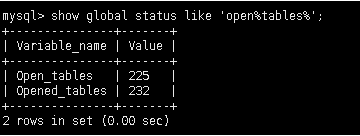
open_tables是当前在缓存中打开表的数量。
opened_tables是mysql自启动起,打开表的数量。
当Opened_tables数值非常大,说明cache太小,导致要频繁地open table,可以查看下当前的table_open_cache设置: show variables like 'table_open_cache'; 查看缓存的上限值
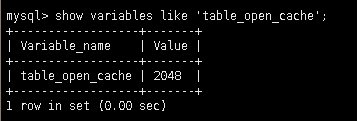
设置table_open_cache的值有两种方式(如果是4G左右内存的服务器,建议设为2048):
1.临时设置,重启服务后将失效
set global table_open_cache=2048;
2.修改数据库配置文件
在/etc/my.cnf 文件的[mysqld]下增减一行:table_open_cache = 2048
e.慢查询日志
记录的慢查询日志的目的是确认是否是由于某些语句执行缓慢而导致的服务器响应慢。
慢查询就不详细说了,网上可以查到很多。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Python查询oracle数据库速度慢的解决方案
如下所示: conn = cx_Oracle.connect('username/password@ip:port/servername') cur = conn.cursor() cur.execute('SELECT * FROM "db"."table"') cur是一个迭代器,不要用fetchall一次性取完数据 直接 for row in cur 即可取数据 使用:sqlalchemy MySQL-Python mysql+mysqldb://<us
-
解决Python访问MySQL数据库速度慢的问题
这两天写了个作业,关于学生选课系统的,随后完成后也会发布到我的博客里面.室友的访问速度几乎是毫秒级,而我的起码要等上四五秒钟. 我总结的影响访问速度的原因主要有以下几种: 1.主机名 2.重复开.关数据库 3.后台数据库中的数据过多,没做数据优化导致后台查询数据很慢 解决方法: 1.用IP地址代替localhost:mysql -h 127.0.0.1 -uroot -p 2.禁止mysql做域名解析: MySQL在处理新的线程连接请求时,会尝试进行DNS解析,如果在host cache和Hos
-
解决python存数据库速度太慢的问题
问题 在项目中遇到一个问题,需要从文本中读取三万条数据写入mysql数据库,文件中为用@分割的sql语句,但是在读取的过程中发现速度过慢,三万八千条数据需要220秒,问题代码片段如下: def read_to_mysql(filecata, targetDir): ''' 用来写入数据库,写入后会剪贴掉文件 filecata 为保存有文件地址的list,已去掉尾部的空格 :param filecata: 文件目录 :param targetDir: 要复制的目标目录 :return: ''' r
-
python 在服务器上调用数据库特别慢的解决过程
在排除网络和环境配置问题后,如果发现本地调试比较快,而部署到服务器就会出现卡顿现象,可以检查下在上传服务器时,是否将连接mysql 的IP改为:localhoast.或者unix_socket 方式连接. 本地调试需要使用服务器ip地址! 更改如下: 补充:服务器响应慢问题 一.分析思路 1.排除本机自身原因 2.服务器性能分析 3.项目本身分析(不详细说) 4.虚拟机分析 5.数据库分析 二.详细分析方法 1.排除本机自身原因 可以使用站长工具测试网站速度. 2.服务器性能分析 使用top命令
-
非常不错的列出sql服务器上所有数据库的asp代码
主题:列出sql服务器上所有库的代码 第一个:dbo权限列出服务器上所有数据库 复制代码 代码如下: <% Dim srv Dim objDB Set srv = Server.CreateObject("SQLDMO.SQLServer") srv.LoginTimeout = 15 srv.Connect "127.0.0.1", "lcx", "lcx" Set objDB = Server.Cr
-

Springboot如何连接远程服务器上的数据库实践
Springboot项目如何连接远程服务器上的数据库 没有数据库服务器,就在自己的服务器上装了mysql,希望将数据库的mysql开放给外部用户,设置如下. 1.在自己的服务器放开3306的端口,当然也可以限制ip的来源,限制那些ip才能够访问. 2.在远程数据库创建一个以供开放的角色,这个角色你可以根据不同的需求场景,开放某一个数据库,授予不同的权限等.以下我创建了一个用户Akio,允许来自任何ip的用户都可借此登录.当然你也可以根据语法创建更多类型更多场景的用户. 3.授予权限,ALL PR
-
sql 语句 取数据库服务器上所有数据库的名字
--取得所有数据库名 包括系统数据库 --SELECT name FROM master.dbo.sysdatabases --取得所有非系统数据库名 --select [name] from master.dbo.sysdatabases where DBId>6 Order By [Name] --取所有信息,包括数据库文件地址 --select * from master.dbo.sysdatabases where DBId>6 Order By [Name]
-
WEB上调用HttpWebRequest奇怪问题的解决方法
今天做了个在局域网的某客户端取得该局域网的公网IP的小程序,方法是通过登陆外网,让外网告诉你所在局域网的公网IP是多少,方法如下: 复制代码 代码如下: Uri uri = new Uri("http://www.jb51.net/"); HttpWebRequest req = (HttpWebRequest)WebRequest.Create(uri); req.Method = "POST"; req.ContentType = "applic
-
Python调用scp向服务器上传文件示例
最近做的项目中有一个小功能:在python中调用scp命令 使用ssh登录,然后将指定目录中的图片上传到服务器指定目录 网上搜了很多方法都没用,最后终于碰到一个可以成功上传的,特此记录 import paramiko # 用于调用scp命令 from scp import SCPClient # 将指定目录的图片文件上传到服务器指定目录 # remote_path远程服务器目录 # file_path本地文件夹路径 # img_name是file_path本地文件夹路径下面的文件名称 def u
-
详解Python下ftp上传文件linux服务器
模块介绍: from ftplib import FTP ftp = FTP() #设置变量 ftp.set_debuglevel(2) #打开调试级别2 显示详细信息 ftp.connect("IP", "port") #连接ftp, IP和端口 ftp.log("user", "password") #连接的用户名.密码 ftp.cwd(pathname) #设置FTP当前操作的路径 ftp.dir() #显示目录下的文件
-
通过Shell脚本批量创建服务器上的MySQL数据库账号
1.项目背景 因监控需要,我们需要在既有的每个MySQL实例上创建一个账号.公司有数百台 MySQL 实例,如果手动登入来创建账号很麻烦,也不现实.所以,我们写了一个简单的shell脚本,用来创建批量服务器的mysql 账号. 2.执行脚本内容; #!/bin/bash ## 此段shell 脚本的主要功能是实现在多个SQL Server IP实例上,创建账号.输入参数是两个,第一个是数据库所在的IPs,即多个Server IP构成的字符串,IP间用逗号隔开.第二个参数是 端口(3306 或
-
python修改FTP服务器上的文件名
python修改FTP服务器上的文件名,具体代码如下所示: #-*- coding:utf-8 -*- #修改ftp服务器上的文件名 from ftplib import FTP def ftpoperate(ip,port,username,passwd,path): #获取ftp服务器某一文件夹下的所有文件名 ftp = FTP() ftp.set_debuglevel(0) ftp.connect(ip,port) ftp.login(username,passwd) ftp.cwd(pa
-
Python Web程序部署到Ubuntu服务器上的方法
在本文记录了我在Ubuntu中部署Flask Web站点的过程, 其中包括用户创建.代码获取.Python3环境的安装.虚拟环境设置.uWSGI启动程序设置,并将Nginx作为前端反向代理.希望对各位有所帮助. 建立一个Python Web程序专用账户 adduser haseo vim /etc/sudoers #将haseo用户加入导sudo用户清单中 sudo usermod -a -G www-data haseo 安装Python3并配置程序运行环境 1.更新Ubuntu的软件库 su