keras处理欠拟合和过拟合的实例讲解
baseline
import tensorflow.keras.layers as layers
baseline_model = keras.Sequential(
[
layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
baseline_model.summary()
baseline_history = baseline_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
小模型
small_model = keras.Sequential(
[
layers.Dense(4, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(4, activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
small_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
small_model.summary()
small_history = small_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
大模型
big_model = keras.Sequential(
[
layers.Dense(512, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(512, activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
big_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
big_model.summary()
big_history = big_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
绘图比较上述三个模型
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
plot_history([('baseline', baseline_history),
('small', small_history),
('big', big_history)])
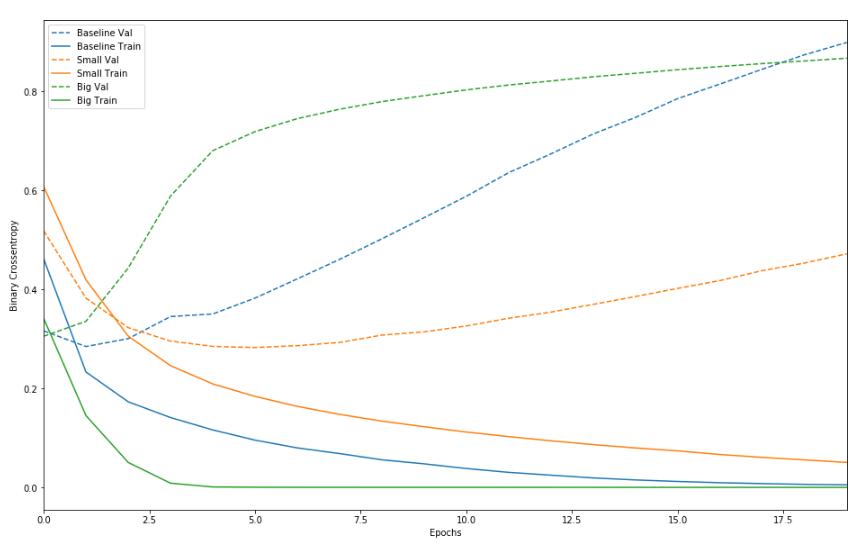
三个模型在迭代过程中在训练集的表现都会越来越好,并且都会出现过拟合的现象
大模型在训练集上表现更好,过拟合的速度更快
l2正则减少过拟合
l2_model = keras.Sequential(
[
layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu', input_shape=(NUM_WORDS,)),
layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation='relu'),
layers.Dense(1, activation='sigmoid')
]
)
l2_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
l2_model.summary()
l2_history = l2_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
plot_history([('baseline', baseline_history),
('l2', l2_history)])
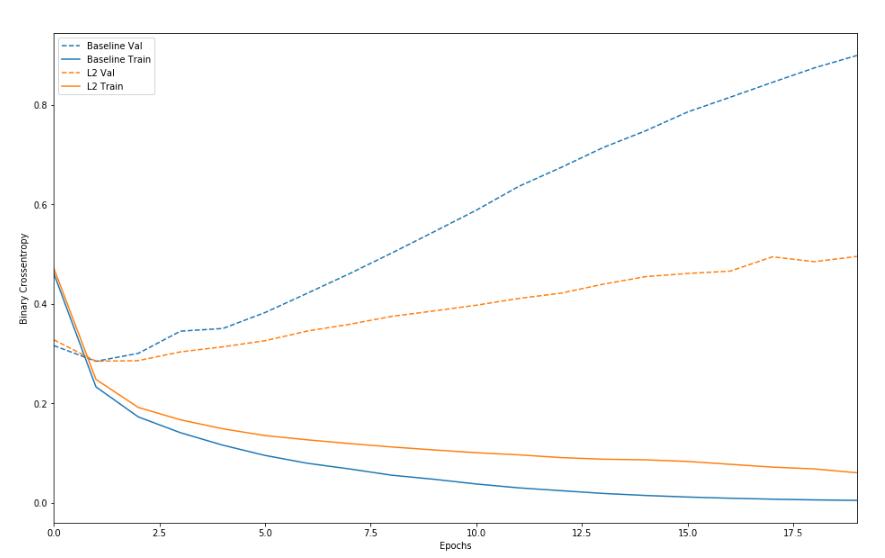
可以发现正则化之后的模型在验证集上的过拟合程度减少
添加dropout减少过拟合
dpt_model = keras.Sequential(
[
layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
layers.Dropout(0.5),
layers.Dense(16, activation='relu'),
layers.Dropout(0.5),
layers.Dense(1, activation='sigmoid')
]
)
dpt_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
dpt_model.summary()
dpt_history = dpt_model.fit(train_data, train_labels,
epochs=20, batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)
plot_history([('baseline', baseline_history),
('dropout', dpt_history)])
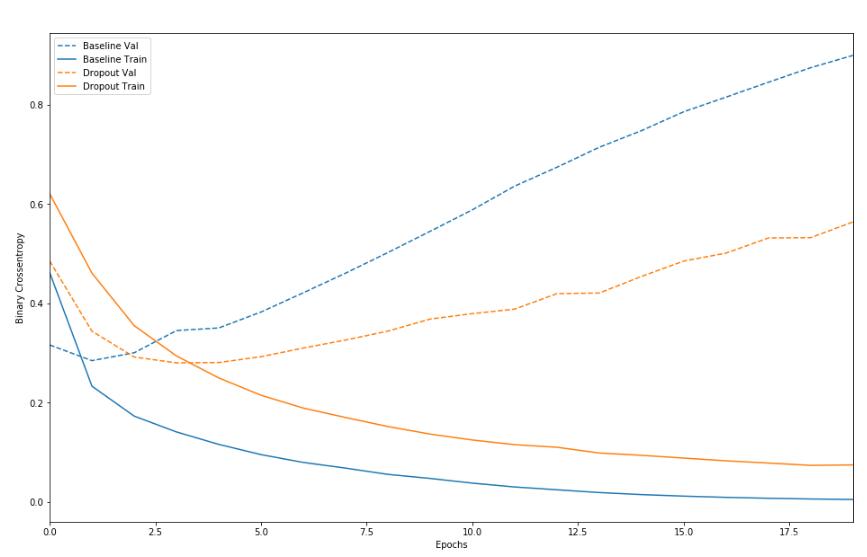
批正则化
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(784,)),
layers.BatchNormalization(),
layers.Dense(64, activation='relu'),
layers.BatchNormalization(),
layers.Dense(64, activation='relu'),
layers.BatchNormalization(),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=keras.optimizers.SGD(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
history = model.fit(x_train, y_train, batch_size=256, epochs=100, validation_split=0.3, verbose=0)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()
总结
防止神经网络中过度拟合的最常用方法:
获取更多训练数据。
减少网络容量。
添加权重正规化。
添加dropout。
以上这篇keras处理欠拟合和过拟合的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用Keras预训练模型ResNet50进行图像分类方式
Keras提供了一些用ImageNet训练过的模型:Xception,VGG16,VGG19,ResNet50,InceptionV3.在使用这些模型的时候,有一个参数include_top表示是否包含模型顶部的全连接层,如果包含,则可以将图像分为ImageNet中的1000类,如果不包含,则可以利用这些参数来做一些定制的事情. 在运行时自动下载有可能会失败,需要去网站中手动下载,放在"~/.keras/models/"中,使用WinPython则在"settings/.ke
-
Keras使用ImageNet上预训练的模型方式
我就废话不多说了,大家还是直接看代码吧! import keras import numpy as np from keras.applications import vgg16, inception_v3, resnet50, mobilenet #Load the VGG model vgg_model = vgg16.VGG16(weights='imagenet') #Load the Inception_V3 model inception_model = inception_v3.I
-
关于keras中keras.layers.merge的用法说明
旧版本中: from keras.layers import merge merge6 = merge([layer1,layer2], mode = 'concat', concat_axis = 3) 新版本中: from keras.layers.merge import concatenate merge = concatenate([layer1, layer2], axis=3) 补充知识:keras输入数据的方法:model.fit和model.fit_generator 1.第一
-

在keras下实现多个模型的融合方式
在网上搜过发现关于keras下的模型融合框架其实很简单,奈何网上说了一大堆,这个东西官方文档上就有,自己写了个demo: # Function:基于keras框架下实现,多个独立任务分类 # Writer: PQF # Time: 2019/9/29 import numpy as np from keras.layers import Input, Dense from keras.models import Model import tensorflow as tf # 生成训练集 data
-
keras 自定义loss损失函数,sample在loss上的加权和metric详解
首先辨析一下概念: 1. loss是整体网络进行优化的目标, 是需要参与到优化运算,更新权值W的过程的 2. metric只是作为评价网络表现的一种"指标", 比如accuracy,是为了直观地了解算法的效果,充当view的作用,并不参与到优化过程 在keras中实现自定义loss, 可以有两种方式,一种自定义 loss function, 例如: # 方式一 def vae_loss(x, x_decoded_mean): xent_loss = objectives.binary_
-
使用keras实现densenet和Xception的模型融合
我正在参加天池上的一个竞赛,刚开始用的是DenseNet121但是效果没有达到预期,因此开始尝试使用模型融合,将Desenet和Xception融合起来共同提取特征. 代码如下: def Multimodel(cnn_weights_path=None,all_weights_path=None,class_num=5,cnn_no_vary=False): ''' 获取densent121,xinception并联的网络 此处的cnn_weights_path是个列表是densenet和xce
-
使用keras2.0 将Merge层改为函数式
不能再向以前一样使用 model.add(Merge([Model1,Model2])) 必须使用函数式 out = Concatenate()([model1.output, model2.output]) 补充知识:keras 新版接口修改 1. # b = MaxPooling2D((3, 3), strides=(1, 1), border_mode='valid', dim_ordering='tf')(x) b = MaxPooling2D((3, 3), strides=(1, 1
-
keras处理欠拟合和过拟合的实例讲解
baseline import tensorflow.keras.layers as layers baseline_model = keras.Sequential( [ layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)), layers.Dense(16, activation='relu'), layers.Dense(1, activation='sigmoid') ] ) baseline_model.compil
-
Python机器学习pytorch模型选择及欠拟合和过拟合详解
目录 训练误差和泛化误差 模型复杂性 模型选择 验证集 K折交叉验证 欠拟合还是过拟合? 模型复杂性 数据集大小 训练误差和泛化误差 训练误差是指,我们的模型在训练数据集上计算得到的误差. 泛化误差是指,我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望. 在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的.未曾在训练集中出现的数据样本构成. 模型复杂性 在本节中将重点介绍几个倾向于影响模型泛化的因素: 可调整参数的数量.当可调
-
使用keras做SQL注入攻击的判断(实例讲解)
本文是通过深度学习框架keras来做SQL注入特征识别, 不过虽然用了keras,但是大部分还是普通的神经网络,只是外加了一些规则化.dropout层(随着深度学习出现的层). 基本思路就是喂入一堆数据(INT型).通过神经网络计算(正向.反向).SOFTMAX多分类概率计算得出各个类的概率,注意:这里只要2个类别:0-正常的文本:1-包含SQL注入的文本 文件分割上,做成了4个python文件: util类,用来将char转换成int(NN要的都是数字类型的,其他任何类型都要转换成int/fl
-
Python 确定多项式拟合/回归的阶数实例
通过 1至10 阶来拟合对比 均方误差及R评分,可以确定最优的"最大阶数". import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression,Perceptron from sklearn.metrics import mean_squared_
-
Keras使用tensorboard显示训练过程的实例
众所周知tensorflow造势虽大却很难用,因此推荐使用Keras,它缺省是基于tensorflow的,但通过修改keras.json也可以用于theano.但是为了能用tensorflow提供的tensorboard,因此建议仍基于tensorflow. 那么问题来了,由于Keras隐藏了tensorflow那令人诟病.可笑至极的graph构建方法,那么如何使用tensorboard呢?一般网站上会告诉你是这样的: 方法一(标准调用方法): 采用keras特有的fit()进行训练,只要在fi
-
TensorFlow 实战之实现卷积神经网络的实例讲解
本文根据最近学习TensorFlow书籍网络文章的情况,特将一些学习心得做了总结,详情如下.如有不当之处,请各位大拿多多指点,在此谢过. 一.相关性概念 1.卷积神经网络(ConvolutionNeural Network,CNN) 19世纪60年代科学家最早提出感受野(ReceptiveField).当时通过对猫视觉皮层细胞研究,科学家发现每一个视觉神经元只会处理一小块区域的视觉图像,即感受野.20世纪80年代,日本科学家提出神经认知机(Neocognitron)的概念,被视为卷积神经网络最初
-
python之tensorflow手把手实例讲解猫狗识别实现
目录 一,猫狗数据集数目构成 二,数据导入 三,数据集构建 四,模型搭建 五,模型训练 六,模型测试 作为tensorflow初学的大三学生,本次课程作业的使用猫狗数据集做一个二分类模型. 一,猫狗数据集数目构成 train cats:1000 ,dogs:1000 test cats: 500,dogs:500 validation cats:500,dogs:500 二,数据导入 train_dir = 'Data/train' test_dir = 'Data/test' validati
-
Python创建简单的神经网络实例讲解
在过去的几十年里,机器学习对世界产生了巨大的影响,而且它的普及程度似乎在不断增长.最近,越来越多的人已经熟悉了机器学习的子领域,如神经网络,这是由人类大脑启发的网络.在本文中,将介绍用于一个简单神经网络的 Python 代码,该神经网络对于一个 1x3 向量,分类第一个元素是否为 10. 步骤1: 导入 NumPy. Scikit-learn 和 Matplotlib import numpy as np from sklearn.preprocessing import MinMaxScale
-
R语言基础统计方法图文实例讲解
tidyr > tdata <- data.frame(names=rownames(tdata),tdata)行名作为第一列 > gather(tdata,key="Key",value="Value",cyl:disp,mpg)创key列和value列,cyl和disp放在一列中 -号减去不需要转换的列 > spread(gdata,key="Key",value="Value") 根据value将
-
python之tensorflow手把手实例讲解斑马线识别实现
一,斑马线的数据集 数据集的构成: test train zebra corssing:56 zebra corssing:168 other:54 other:164 二,代码部分 1.导包 import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator import numpy as np import matplotlib.pyplot as plt import ker