基于Python共轭梯度法与最速下降法之间的对比
在一般问题的优化中,最速下降法和共轭梯度法都是非常有用的经典方法,但最速下降法往往以”之”字形下降,速度较慢,不能很快的达到最优值,共轭梯度法则优于最速下降法,在前面的某个文章中,我们给出了牛顿法和最速下降法的比较,牛顿法需要初值点在最优点附近,条件较为苛刻。
算法来源:《数值最优化方法》高立,P111
我们选用了64维的二次函数来作为验证函数,具体参见上书111页。
采用的三种方法为:
共轭梯度方法(FR格式)、共轭梯度法(PRP格式)、最速下降法
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 01 15:01:54 2016
@author: zhangweiguo
"""
import sympy,numpy
import math
import matplotlib.pyplot as pl
from mpl_toolkits.mplot3d import Axes3D as ax3
import SD#这个文件里有最速下降法SD的方法,参见前面的博客
#共轭梯度法FR、PRP两种格式
def CG_FR(x0,N,E,f,f_d):
X=x0;Y=[];Y_d=[];
n = 1
ee = f_d(x0)
e=(ee[0]**2+ee[1]**2)**0.5
d=-f_d(x0)
Y.append(f(x0)[0,0]);Y_d.append(e)
a=sympy.Symbol('a',real=True)
print '第%2s次迭代:e=%f' % (n, e)
while n<N and e>E:
n=n+1
g1=f_d(x0)
f1=f(x0+a*f_d(x0))
a0=sympy.solve(sympy.diff(f1[0,0],a,1))
x0=x0-d*a0
X=numpy.c_[X,x0];Y.append(f(x0)[0,0])
ee = f_d(x0)
e = math.pow(math.pow(ee[0,0],2)+math.pow(ee[1,0],2),0.5)
Y_d.append(e)
g2=f_d(x0)
beta=(numpy.dot(g2.T,g2))/numpy.dot(g1.T,g1)
d=-f_d(x0)+beta*d
print '第%2s次迭代:e=%f'%(n,e)
return X,Y,Y_d
def CG_PRP(x0,N,E,f,f_d):
X=x0;Y=[];Y_d=[];
n = 1
ee = f_d(x0)
e=(ee[0]**2+ee[1]**2)**0.5
d=-f_d(x0)
Y.append(f(x0)[0,0]);Y_d.append(e)
a=sympy.Symbol('a',real=True)
print '第%2s次迭代:e=%f' % (n, e)
while n<N and e>E:
n=n+1
g1=f_d(x0)
f1=f(x0+a*f_d(x0))
a0=sympy.solve(sympy.diff(f1[0,0],a,1))
x0=x0-d*a0
X=numpy.c_[X,x0];Y.append(f(x0)[0,0])
ee = f_d(x0)
e = math.pow(math.pow(ee[0,0],2)+math.pow(ee[1,0],2),0.5)
Y_d.append(e)
g2=f_d(x0)
beta=(numpy.dot(g2.T,g2-g1))/numpy.dot(g1.T,g1)
d=-f_d(x0)+beta*d
print '第%2s次迭代:e=%f'%(n,e)
return X,Y,Y_d
if __name__=='__main__':
'''
G=numpy.array([[21.0,4.0],[4.0,15.0]])
#G=numpy.array([[21.0,4.0],[4.0,1.0]])
b=numpy.array([[2.0],[3.0]])
c=10.0
x0=numpy.array([[-10.0],[100.0]])
'''
m=4
T=6*numpy.eye(m)
T[0,1]=-1;T[m-1,m-2]=-1
for i in xrange(1,m-1):
T[i,i+1]=-1
T[i,i-1]=-1
W=numpy.zeros((m**2,m**2))
W[0:m,0:m]=T
W[m**2-m:m**2,m**2-m:m**2]=T
W[0:m,m:2*m]=-numpy.eye(m)
W[m**2-m:m**2,m**2-2*m:m**2-m]=-numpy.eye(m)
for i in xrange(1,m-1):
W[i*m:(i+1)*m,i*m:(i+1)*m]=T
W[i*m:(i+1)*m,i*m+m:(i+1)*m+m]=-numpy.eye(m)
W[i*m:(i+1)*m,i*m-m:(i+1)*m-m]=-numpy.eye(m)
mm=m**2
mmm=m**3
G=numpy.zeros((mmm,mmm))
G[0:mm,0:mm]=W;G[mmm-mm:mmm,mmm-mm:mmm]=W;
G[0:mm,mm:2*mm]=-numpy.eye(mm)
G[mmm-mm:mmm,mmm-2*mm:mmm-mm]=-numpy.eye(mm)
for i in xrange(1,m-1):
G[i*mm:(i+1)*mm,i*mm:(i+1)*mm]=W
G[i*mm:(i+1)*mm,i*mm-mm:(i+1)*mm-mm]=-numpy.eye(mm)
G[i*mm:(i+1)*mm,i*mm+mm:(i+1)*mm+mm]=-numpy.eye(mm)
x_goal=numpy.ones((mmm,1))
b=-numpy.dot(G,x_goal)
c=0
f = lambda x: 0.5 * (numpy.dot(numpy.dot(x.T, G), x)) + numpy.dot(b.T, x) + c
f_d = lambda x: numpy.dot(G, x) + b
x0=x_goal+numpy.random.rand(mmm,1)*100
N=100
E=10**(-6)
print '共轭梯度PR'
X1, Y1, Y_d1=CG_FR(x0,N,E,f,f_d)
print '共轭梯度PBR'
X2, Y2, Y_d2=CG_PRP(x0,N,E,f,f_d)
figure1=pl.figure('trend')
n1=len(Y1)
n2=len(Y2)
x1=numpy.arange(1,n1+1)
x2=numpy.arange(1,n2+1)
X3, Y3, Y_d3=SD.SD(x0,N,E,f,f_d)
n3=len(Y3)
x3=range(1,n3+1)
pl.semilogy(x3,Y3,'g*',markersize=10,label='SD:'+str(n3))
pl.semilogy(x1,Y1,'r*',markersize=10,label='CG-FR:'+str(n1))
pl.semilogy(x2,Y2,'b*',markersize=10,label='CG-PRP:'+str(n2))
pl.legend()
#图像显示了三种不同的方法各自迭代的次数与最优值变化情况,共轭梯度方法是明显优于最速下降法的
pl.xlabel('n')
pl.ylabel('f(x)')
pl.show()
最优值变化趋势:
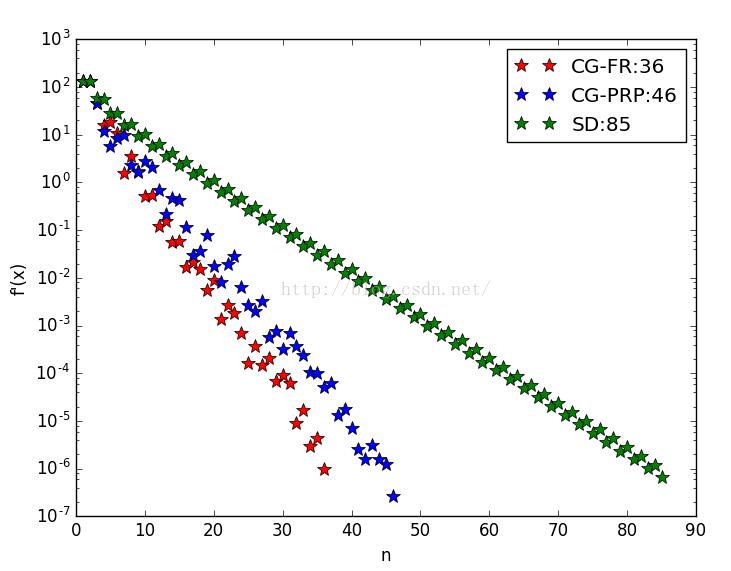
从图中可以看出,最速下降法SD的迭代次数是最多的,在与共轭梯度(FR与PRP两种方法)的比较中,明显较差。
补充知识:python实现牛顿迭代法和二分法求平方根,精确到小数点后无限多位-4
首先来看一下牛顿迭代法求平方根的过程:计算3的平方根

如图,是求根号3的牛顿迭代法过程。这里使用的初始迭代值(也就是猜测值)为1,其实可以为任何值最终都能得到结果。每次开始,先检测猜测值是否合理,不合理时,用上面的平均值来换掉猜测值,依次继续迭代,直到猜测值合理。
原理:现在取一个猜测值 a, 如果猜测值合理的话,那么就有a^2=x,即x/a=a ,x为被开方数。不合理的话呢,就用表中的猜测值和商的平均值来换掉猜测值。当不合理时,比如 a>真实值,那么x/a<真实值,这时候取a 与 x/a 的平均值来代替a的话,那么新的a就会比原来的a要更接近真实值。同理有 a<真实值 的情况。于是,这样不断迭代下去最终是一个a不断收敛到真实值的一个过程。于是不断迭代就能得到真实值,证明了迭代法是正确的。
附上我的python代码:
利用python整数运算,python整数可以无限大,可以实现小数点后无限多位
#二分法求x的平方根小数点下任意K位数的精准值,利用整数运算 #思想:利用二分法,每次乘以10,取中间值,比较大小,从而定位精确值的范围,将根扩大10倍,则被开方数扩大100倍。 #quotient(商)牛顿迭代法:先猜测一个值,再求商,然后用猜测值和商的中间值代替猜测值,扩大倍数,继续进行。
import math
from math import sqrt
def check_precision(l,h,p,len1):#检查是否达到了精确位
l=str(l);h=str(h)
if len(l)<=len1+p or len(h)<=len1+p:
return False
for i in range(len1,p+len1):#检查小数点后面的p个数是否相等
if l[i]!=h[i]: #当l和h某一位不相等时,说明没有达到精确位
return False
return True
def print_result(x,len1,p):
x=str(x)
if len(x)-len1<p:#没有达到要求的精度就已经找出根
s=x[:len1]+"."+x[len1:]+'0'*(p-len(x)+len1)
else:s=x[:len1]+"."+x[len1:len1+p]
print(s)
def binary_sqrt(x,p):
x0=int(sqrt(x))
if x0*x0==x: #完全平方数直接开方,不用继续进行
print_result(x0,len(str(x0)),p)
return
len1=len(str(x0))#找出整数部分的长度
l=0;h=x
while(not check_precision(l,h,p,len1)):#没有达到精确位,继续循环
if not l==0:#第一次l=0,h=x时不用乘以10,直接取中间值
h=h*10 #l,h每次扩大10倍
l=l*10
x=x*100 #x每次要扩大100倍,因为平方
m=(l+h)//2
if m*m==x:
return print_result(m,len1,p)
elif m*m>x:
h=m
else:
l=m
return print_result(l,len1,p)#当达到了要求的精度,直接返回l
#牛顿迭代法求平方根
def newton_sqrt(x,p):
x0=int(sqrt(x))
if x0*x0==x: #完全平方数直接开方,不用继续进行
print_result(x0,len(str(x0)),p)
return
len1=len(str(x0))#找出整数部分的长度
g=1;q=x//g;g=(g+q)//2
while(not check_precision(g,q,p,len1)):
x=x*100
g=g*10
q=x//g #求商
g=(g+q)//2 #更新猜测值为猜测值和商的中间值
return print_result(g,len1,p)
while True:
x=int(input("请输入待开方数:"))
p=int(input("请输入精度:"))
print("binary_sqrt:",end="")
binary_sqrt(x,p)
print("newton_sqrt:",end="")
newton_sqrt(x,p)
以上这篇基于Python共轭梯度法与最速下降法之间的对比就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

python实现迭代法求方程组的根过程解析
这篇文章主要介绍了python实现迭代法求方程组的根过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 有方程组如下: 迭代法求解x,python代码如下: import numpy as np import matplotlib.pyplot as plt A = np.array([[8, -3, 2], [4, 11, -1], [6, 3, 12]]) b = np.array([[20, 33, 36]]) # 方法一:消元法求解
-
8种用Python实现线性回归的方法对比详解
前言 说到如何用Python执行线性回归,大部分人会立刻想到用sklearn的linear_model,但事实是,Python至少有8种执行线性回归的方法,sklearn并不是最高效的. 今天,让我们来谈谈线性回归.没错,作为数据科学界元老级的模型,线性回归几乎是所有数据科学家的入门必修课.抛开涉及大量数统的模型分析和检验不说,你真的就能熟练应用线性回归了么?未必! 在这篇文章中,文摘菌将介绍8种用Python实现线性回归的方法.了解了这8种方法,就能够根据不同需求,灵活选取最为高效的方法实现线
-
python中比较两个列表的实例方法
cmp() 方法用于比较两个列表的元素. cmp()方法语法: cmp(list1, list2) 参数: list1 -- 比较的列表.list2 -- 比较的列表. 返回值: 如果比较的元素是同类型的,则比较其值,返回结果. 如果两个元素不是同一种类型,则检查它们是否是数字. 如果是数字,执行必要的数字强制类型转换,然后比较.如果有一方的元素是数字,则另一方的元素"大"(数字是"最小的")否则,通过类型名字的字母顺序进行比较. 如果有一个列表首先到达末尾,则另一
-
基于Python共轭梯度法与最速下降法之间的对比
在一般问题的优化中,最速下降法和共轭梯度法都是非常有用的经典方法,但最速下降法往往以"之"字形下降,速度较慢,不能很快的达到最优值,共轭梯度法则优于最速下降法,在前面的某个文章中,我们给出了牛顿法和最速下降法的比较,牛顿法需要初值点在最优点附近,条件较为苛刻. 算法来源:<数值最优化方法>高立,P111 我们选用了64维的二次函数来作为验证函数,具体参见上书111页. 采用的三种方法为: 共轭梯度方法(FR格式).共轭梯度法(PRP格式).最速下降法 # -*- codin
-
几个提升Python运行效率的方法之间的对比
在我看来,python社区分为了三个流派,分别是python 2.x组织,3.x组织和PyPy组织.这个分类基本上可以归根于类库的兼容性和速度.这篇文章将聚焦于一些通用代码的优化技巧以及编译成C后性能的显著提升,当然我也会给出三大主要python流派运行时间.我的目的不是为了证明一个比另一个强,只是为了让你知道如何在不同的环境下使用这些具体例子作比较. 使用生成器 一个普遍被忽略的内存优化是生成器的使用.生成器让我们创建一个函数一次只返回一条记录,而不是一次返回所有的记录,如果你正在使用pyth
-
基于Python实现对比Exce的工具
目录 1.参数 2.效果 3.实现 目的:设计一个应用GUI用于对比两个Excel文件 思路 1.参数 同一个excel文件两个sheet页其中一个ODS(老数据),一个DWH(新数据) 生成对比文件 设计两个主键 输入主键1 输入主键2 (默认新旧文件列名一致) 2.效果 生成的文件 数据量一样.取每个字段不一致的数据前10 数据量不一样.取两边不一样的数据前10.排除不一样的数据.每个字段不一致的数据前10 3.实现 循环对比组合列(主键+对比列) pandas处理差异数据.openpyxl
-
详解基于python的图像Gabor变换及特征提取
1.前言 在深度学习出来之前,图像识别领域北有"Gabor帮主",南有"SIFT慕容小哥".目前,深度学习技术可以利用CNN网络和大数据样本搞事情,从而取替"Gabor帮主"和"SIFT慕容小哥"的江湖地位.但,在没有大数据和算力支撑的"乡村小镇"地带,或是对付"刁民小辈","Gabor帮主"可以大显身手,具有不可撼动的地位.IT武林中,有基于C++和OpenCV,或
-
基于Python实现口罩佩戴检测功能
目录 口罩佩戴检测 一 题目背景 1.1 实验介绍 1.2 实验要求 1.3 实验环境 1.4 实验思路 二 实验内容 2.1 已知文件与数据集 2.2 图片尺寸调整 2.3 制作训练时需要用到的批量数据集 2.4 调用MTCNN 2.5 加载预训练模型MobileNet 2.6 训练模型 2.6.1 加载和保存 2.6.2 手动调整学习率 2.6.3 早停法 2.6.4 乱序训练数据 2.6.5 训练模型 三 算法描述 3.1 MTCNN 3.2 MobileNet 四 求解结果 五 比较分析
-
基于python时间处理方法(详解)
在处理数据和进行机器学习的时候,遇到了大量需要处理的时间序列.比如说:数据库读取的str和time的转化,还有time的差值计算.总结一下python的时间处理方面的内容. 一.字符串和时间序列的转化 time.strptime():字符串=>时间序列 time.strftime():时间序列=>字符串 import time start = "2017-01-01" end = "2017-8-12" startTime = time.strptime
-
基于Python和Scikit-Learn的机器学习探索
你好,%用户名%! 我叫Alex,我在机器学习和网络图分析(主要是理论)有所涉猎.我同时在为一家俄罗斯移动运营商开发大数据产品.这是我第一次在网上写文章,不喜勿喷. 现在,很多人想开发高效的算法以及参加机器学习的竞赛.所以他们过来问我:"该如何开始?".一段时间以前,我在一个俄罗斯联邦政府的下属机构中领导了媒体和社交网络大数据分析工具的开发.我仍然有一些我团队使用过的文档,我乐意与你们分享.前提是读者已经有很好的数学和机器学习方面的知识(我的团队主要由MIPT(莫斯科物理与技术大学)和
-
基于python爬虫数据处理(详解)
一.首先理解下面几个函数 设置变量 length()函数 char_length() replace() 函数 max() 函数 1.1.设置变量 set @变量名=值 set @address='中国-山东省-聊城市-莘县'; select @address 1.2 .length()函数 char_length()函数区别 select length('a') ,char_length('a') ,length('中') ,char_length('中') 1.3. replace() 函数
-
基于Python实现文件大小输出
在数据库中存储时,使用 Bytes 更精确,可扩展性和灵活性都很高. 输出时,需要做一些适配. 1. 注意事项与测试代码 1.需要考虑 sizeInBytes 为 None 的场景. 2.除以 1024.0 而非 1024,避免丢失精度. 实现的函数为 getSizeInMb(sizeInBytes),通用的测试代码为 def getSizeInMb(sizeInBytes): return 0 def test(sizeInBytes): print '%s -> %s' % (sizeInB
-
基于Python对象引用、可变性和垃圾回收详解
变量不是盒子 在示例所示的交互式控制台中,无法使用"变量是盒子"做解释.图说明了在 Python 中为什么不能使用盒子比喻,而便利贴则指出了变量的正确工作方式. 变量 a 和 b 引用同一个列表,而不是那个列表的副本 >>> a = [1, 2, 3] >>> b = a >>> a.append(4) >>> b [1, 2, 3, 4] 如果把变量想象为盒子,那么无法解释 Python 中的赋值:应该把变量视作