浅谈JupyterNotebook导出pdf解决中文的问题
1.将ipynd编译成tex
建议将其放在桌面处理
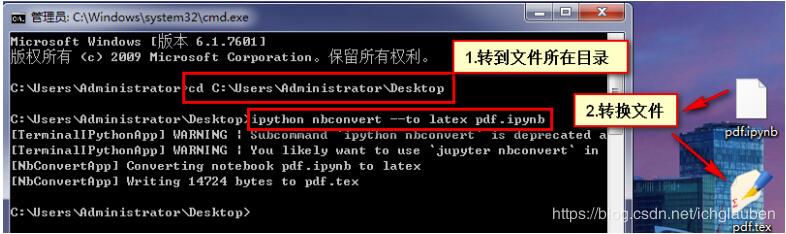
ipython nbconvert —to latex pdf.ipynb
2.修改tex
双击打开转换的文件在\documentclass{article}后面插入
\usepackage{fontspec, xunicode, xltxtra}
\setmainfont{Microsoft YaHei}
\usepackage{ctex}

3.编译tex 生成pdf
xelate pdf.tex

补充知识:Jupyter notebook 转成pdf 中文显示、代码隐藏
打开
D:\Anaconda3\Lib\site-packages\nbconvert\templates\latex/article.tplx
一、ctex中文包
修改
\documentclass[11pt]{article}
为
\documentclass{article}
\usepackage{ctex}
二、不显示输入
添加
((* block input_group *))
((* endblock input_group *))
以上这篇浅谈JupyterNotebook导出pdf解决中文的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
解决Jupyter notebook中.py与.ipynb文件的import问题
在jupyter notebook中,因为其解析文件的方式是基于json的,所以其默认保存的文件格式不是.py而是.ipynb.而.ipynb文件并不能简单的import进.py或者.ipynb文件中,这就为开发带来了极大不便.因为在jupyter notebook中,一定要是在默认的.ipynb下才能有一系列的特性支持,比如自动补全,控制台等待,而.py文件只能通过文本编辑器修改,非常非常不便. 因为.ipynb可以import .py的module,所以其中一个解决方法是将已经写好的.ipy
-
jupyter notebook 添加kernel permission denied的操作
为什么要手动添加核? 因为使用公司的服务器,最好不要直接使用anaconda自带的python,更不要使用系统下自带的python,如果每个人都使用同一个python,可能会给别人的工作带来"致命的伤害". 怎么添加? 正常情况: python -m ipykernel install --name your_env_name (your_env_name 代表你的python环境的名字) 如果出现 error13 permiss denied:/usr/local/share/jup
-
快速解决jupyter notebook启动需要密码的问题
jupyter notebook安装完成之后需要密码,还有某些情况下也会出现需要输入密码的情况 解决方法如下: 1.在运行界面输入 jupyter notebook list 2.之后运行界面会输出token值,将其复制到密码栏中 补充知识:Python 遇到NameError: name '_name_' is not defined这样的错误 今天练习写Python主函数的时候,遇到了NameError: name 'name' is not defined 这样的错误.>因为name是一个
-
jupyter notebook tensorflow打印device信息实例
juypter notebook中直接使用log_device_placement=True打印不出来device信息 # Creates a graph. with tf.device('/device:CPU:0'): a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name
-
Jupyter Notebook的连接密码 token查询方式
换用非默认浏览器时需要输入密码或token 查询方法: 在XX:\AnacondaXX\Scripts下 运行 jupyter-notebook.exe list 可得token 密码:(设成了用不了..???) 在jupyter notebook正常开的文件里打 in[1]from notebook.auth import passwd in[2]passwd() 补充知识:Anaconda3中自带Jupyter notebook如何查找token 最近在使用Anaconda3学习tensor
-
Jupyter Notebook折叠输出的内容实例
一.问题描述 当Jupyter Notebook的输出内容很多时,为了屏幕可以显示更多的代码行,我需要将输出的内容进行折叠. 二.解决方法 1.鼠标操作 (1)鼠标左键双击输出单元格的左侧灰色区域. (2)展开:鼠标左键单机下方的灰色区域即可.如下图所示: 2.快捷键操作 (1)按Esc键 (2)按字母O (3)展开:同上. 补充知识:Python 找出出现次数超过数组长度一半的元素实例 利用问题的普遍性和特殊性来求解,代码如下: import unittest from datetime im
-
jupyter notebook 的工作空间设置操作
Jupyter notebook 安装后,启动后,默认的工作空间是当前用户目录.为了方便对文档进行管理,往往需要自行设置工作空间.下面介绍一种便捷的工作空间设置方法. 对 Jupyter notebook 快捷方式进行修改.右击 jupyter notebook 快捷方式 -> 属性 -> 把"目标"中的 %USERPROFILE% 替换成你想要的目录,eg:D:\python-workspace. 接下来双击 Jupyter notebook 运行,就可以见证效果. 补充
-
浅谈JupyterNotebook导出pdf解决中文的问题
1.将ipynd编译成tex 建议将其放在桌面处理 ipython nbconvert -to latex pdf.ipynb 2.修改tex 双击打开转换的文件在\documentclass{article}后面插入 \usepackage{fontspec, xunicode, xltxtra} \setmainfont{Microsoft YaHei} \usepackage{ctex} 3.编译tex 生成pdf xelate pdf.tex 补充知识:Jupyter notebook
-
浅谈Java泛型通配符解决了泛型的许多诟病(如不能重载)
泛型: package Java基础增强; import java.util.ArrayList; import java.util.List; import org.junit.Test; public class Test2 { @Test public void fun1(){ Object[] objects = new Object[10]; List list = new ArrayList(); String[] strings = new String[10]; List<Str
-

浅谈Python处理PDF的方法
处理pdf文档 第一. 从文本中提取文本 第二. 创建PDF 两种方法 #使用PdfFileWriter import PyPDF2 pdfFiles = [] for filename in os.listdir('.'): if filename.endswith('.pdf'): pdfFiles.append(filename) print(pdfFiles) pdfWriter = PyPDF2.PdfFileWriter() pdfFileObj = open(pdfFiles[0]
-
浅谈python实现Google翻译PDF,解决换行的问题
我们复制PDF到Google翻译时,总是会出现换行的情况,如果自己手动去除,那就太麻烦了. 那么用Python就可以解决,复制到粘贴板以后,Python程序自动可以把\n换成空格,然后我们就可以复制到Google翻译中去 代码: import pyperclip import time import webbrowser copyBuff=' ' while True: time.sleep(10) copyedText=pyperclip.paste() if copyBuff!=copyed
-
浅谈Android Studio导出javadoc文档操作及问题的解决
1.在Android studio中进行打开一个项目的文件之后,然后进行点击Android stuio中菜单中的"tools"的选项.在弹出了下拉菜单中,进行选中下拉菜单中的"Generate JavaDoc"的选项. 2.在弹出界面中 Output directory是你即将生产的javadoc文件的存储位置,图中1指示的位置:正常点击ok即可: 但是如果有异常情况 比如空指针异常或者文档乱码 java.lang.NullPointerException 或者 j
-
浅谈Python2获取中文文件名的编码问题
问题: Python2获取包含中文的文件名是如果不转码会出现乱码. 这里假设要测试的文件夹名为test,文件夹下有5个文件名包含中文的文件分别为: Python性能分析与优化.pdf Python数据分析与挖掘实战.pdf Python编程实战:运用设计模式.并发和程序库创建高质量程序.pdf 流畅的Python.pdf 编写高质量Python代码的59个有效方法.pdf 我们先不转码直接打印获取到的文件名,代码如下: import os for file in os.listdir('./te
-
浅谈python的elementtree模块处理中文注意事项
处理中文在进行写文件时,必须采用以下方式: tree.write(nxmlpath, "UTF-8") 如果写成: tree.write(nxmlpath, "utf-8") 则会使输出文件缺少<?xml version="1.0" encoding="UTF-8"?>头 如果写成: <?xml version="1.0" encoding="utf8"?> 则输
-
浅谈Maven包冲突的原理及解决方法
1.概述 Apache Maven ,是一个软件(特别是Java软件)项目管理及自动构建工具.在没有Maven的上古年代,项目中引入jar包需要手动下载一个个的去下载,但是随着代码数量的增加,引入的jar包数量自然会增加,随之而来的就是jar包冲突的问题了. 2.产生jar包冲突的原因 众所周知,一个项目中不能存在两个全限定类名一致的Class类,并且jar包的本质就是打包好的Class类文件,例如: 将 junit-jupiter-api-5.6.2.jar 文件解压后, 可以得到多个Clas
-
JS导出PDF插件的方法(支持中文、图片使用路径)
在WEB上想做一个导出PDF的功能,发现jsPDF比较多人推荐,遗憾的是不支持中文,最后找到pdfmake,很好地解决了此问题.它的效果可以先到http://pdfmake.org/playground.html查看.在使用过程中,还发现图片的插入是相对繁琐的一件事. 针对这些问题,本文的主要内容可分为三部分: •pdfmake的基本使用方法: •如何解决中文问题; •如何通过指定图片地址插入图片. pdfmake的基本使用方法 1.包含以下两个文件 <script src="build/
-
浅谈php中fopen不能创建中文文件名文件的问题
之前网页的chartset用的是utf-8,文件也用utf-8,然后用fopen()创建一个中文文件名的文件时问题就出来了,文件名都是乱 码! 查看了很多文档试了不少方法都解决不了,本来想着用别的方法绕过这个问题,忽然脑子里闪过Windows默认的文字编码是ansi,然后再 baidu了一下,证实了这点,所以我的网页也应该是ansi编码才能使创建的文件名不会是乱码. 接着就着手验证,把网页都用ansi保存,去掉chartset语句,果然ok了,但是网页的内容就成乱码了,后来想起,这个网页还inc