PyHacker编写URL批量采集器
目录
- 00x1:需要用到的模块
- 00x2:选取搜索引擎
- 00x3:分析需要采集的url
- 00x4:搜索
- 00x5:自动保存
- 00x6:完整代码
喜欢用Python写脚本的小伙伴可以跟着一起写一写呀。
编写环境:Python2.x
00x1:需要用到的模块
需要用到的模块如下:
import requests import re
本文将用re正则进行讲解,如果你用Xpath也可以
00x2:选取搜索引擎
首先我们要选取搜索引擎(其他搜索引擎原理相同)
以bing为例:Cn.bing.com
首先分析bing翻页机制:
https://cn.bing.com/search?q=内容&first=0 第一页 https://cn.bing.com/search?q=内容&first=10 第二页 https://cn.bing.com/search?q=内容&first=20 第三页
页数 = First*10
分析完毕,我们来请求看一下
def req():
url = 'https://cn.bing.com/search?q=小陈&first=0'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}
req = requests.get(url,headers=headers)
html = req.content
print html

Ok,没毛病
00x3:分析需要采集的url
分析需要采集的url在哪个位置

得出正则:(.*?)
正则表达式学习:(百度搜:python 正则表达式)
def reurl():
urlr = r'<cite>(.*?)</cite>'
reurl = re.findall(urlr,html)
print reurl

就在我请求第二页的时候发现了问题

可以看到请求内容和第一页一样,有某种验证机制
一般情况下验证机制,表示特定参数
经过多次测试,发现缺少 Cookie: _EDGE_V=1;

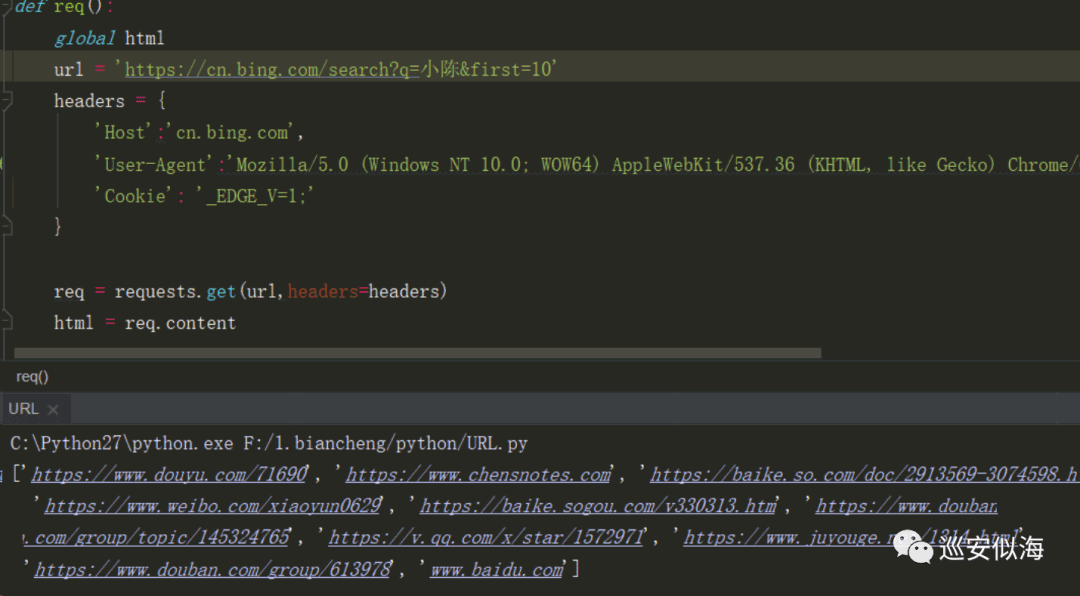
请求正常,大致已经完成
接下来只需要给关键词和页数变量就ok了
00x4:搜索
再搜索site:baidu.com 又出现了问题

于是修改正则为:
'target="_blank" href="(http.*?\..*?\..*?)" h="'

有很多我们不想要的结果,我们再来遍历下采集的urls
做一下处理
正则为:
(http[s]?://.*?)/
代码为:
def url():
for url in urls:
urlr = r'(http[s]?://.*?)/'
url = re.findall(urlr,url)
print url

print url 改为 print url[0] 再进行处理一下
可以看到下面还有重复的url,对url去重一下
def qc():#去重复
for url in url_ok:
if url in url_bing:
continue
url_bing.append(url)

00x5:自动保存
接下来我们要让他自动保存到url_bing.txt
with open('url_bing.txt','a+')as f:
for url in url_bing:
print url
f.write(url+"\n")
print "Save as url_bing.txt"
00x6:完整代码
#!/usr/bin/python
#-*- coding:utf-8 -*-
import requests
import re
urls = []
url_ok = []
url_bing=[]
def req(q,first):
global html
url = 'https://cn.bing.com/search?q=%s&first=%s'%(q,first)
print url
headers = {
'Host':'cn.bing.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0',
'Cookie': '_EDGE_V=1;'
}
req = requests.get(url,headers=headers)
html = req.content
def reurl():#正则匹配url
urlr = r'target="_blank" href="(http.*?\..*?\..*?)" h="'
reurl = re.findall(urlr,html)
for url in reurl:
if url not in urls:
urls.append(url)
def url():#url二次处理
for url in urls:
urlr = r'(http[s]?://.*?)/'
url = re.findall(urlr,url)
url_ok.append(url[0])
def qc():#去重复
for url in url_ok:
if url in url_bing:
continue
url_bing.append(url)
if __name__ == '__main__':
q = raw_input('\nkey:')
page = input('page:')
for first in range(0, page):
req(q, first * 10)
reurl()
url()
qc()
with open('url_bing.txt','a+')as f:
for url in url_bing:
print url
f.write(url+"\n")
print "Save as url_bing.txt"
以上就是PyHacker编写URL批量采集器的详细内容,更多关于PyHacker批量采集URL的资料请关注我们其它相关文章!
相关推荐
-
PHP文章采集URL补全函数(FormatUrl)
写采集必用的函数,URL补全函数,也可叫做FormatUrl. 写此函数作用就是为了开发采集程序,采集文章的时候会经常遇到页面里的路径是 "相对路径" 或者 "绝对根路径" 不是"绝对全路径"就无法收集URL. 所以,就需要本功能函数进行对代码进行格式化,把所有的超链接都格式化一遍,这样就可以直接收集到正确的URL了. 路径知识普及 相对路径:"../" "./" 或者前面什么都不加 绝对根路径:/path
-
python采集百度搜索结果带有特定URL的链接代码实例
这篇文章主要介绍了python采集百度搜索结果带有特定URL的链接代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 #coding utf-8 import requests from bs4 import BeautifulSoup as bs import re from Queue import Queue import threading from argparse import ArgumentParser arg = Argu
-
C#网页信息采集方法汇总
本文实例总结了三种常用的C#网页信息采集方法.分享给大家供大家参考.具体实现方法如下: 一.通过HttpWebResponse 来获取 复制代码 代码如下: public static string CheckTeamSiteUrl(string url) { string response = ""; HttpWebResponse httpResponse = null; //assert: user have acces
-

PyHacker编写URL批量采集器
目录 00x1:需要用到的模块 00x2:选取搜索引擎 00x3:分析需要采集的url 00x4:搜索 00x5:自动保存 00x6:完整代码 喜欢用Python写脚本的小伙伴可以跟着一起写一写呀. 编写环境:Python2.x 00x1:需要用到的模块 需要用到的模块如下: import requests import re 本文将用re正则进行讲解,如果你用Xpath也可以 00x2:选取搜索引擎 首先我们要选取搜索引擎(其他搜索引擎原理相同) 以bing为例:Cn.bing.com 首先分
-
详解Opentelemetry Collector采集器
目录 前言 客户端数据上报 OTLP OTLP/HTTP OTLP/gRPC Collector Collector简介 Collector使用 Receiver Processor Exportor Extension Service 个性化的Collector 总结 前言 上个篇章中我们主要介绍了OpenTelemetry的客户端的一些数据生成方式,但是客户端的数据最终还是要发送到服务端来进行统一的采集整合,这样才能看到完整的调用链,metrics等信息.因此在这个篇章中会主要介绍服务端的采
-
基于Qt编写简易的视频播放器
目录 一.前言 二.效果图 三.体验地址 四.相关代码 五.功能特点 5.1 基础功能 5.2 特色功能 5.3 视频控件 5.4 内核ffmpeg 一.前言 花了一年多的时间,终于把这个超级播放器做成了自己想要的架构,用户的需求是一方面,自己架构方面的提升也是一方面,最主要是将界面和解码解耦了,这样才能动态的挂载不同的解码内核到不同的窗体,多对多关系,而且解耦和才能方便的实现共享解码,整个设计参照了Qt的设计思路,将各种功能做成不同的类组件,同时还有多层基类的设计,最大的提炼共性,本组件设计的
-
利用PHP制作简单的内容采集器的代码
采集器,通常又叫小偷程序,主要是用来抓取别人网页内容的.关于采集器的制作,其实并不难,就是远程打开要采集的网页,然后用正则表达式将需要的内容匹配出来,只要稍微有点正则表达式的基础,都能做出自己的采集器来的. 前几天做了个小说连载的程序,因为怕更新麻烦,顺带就写了个采集器,采集八路中文网的,功能比较简单,不能自定义规则,不过大概思路都在里面了,自定义规则可以自己来扩展. 用php来做采集器主要用到两个函数:file_get_contents()和preg_match_all(),前一个是远程读取网
-
利用PHP制作简单的内容采集器的原理分析
前几天做了个小说连载的程序,因为怕更新麻烦,顺带就写了个采集器,采集八路中文网的,功能比较简单,不能自定义规则,不过大概思路都在里面了,自定义规则可以自己来扩展. 用php来做采集器主要用到两个函数:file_get_contents()和preg_match_all(),前一个是远程读取网页内容的,不过只在php5以上的版本才能用,后一个是正则函数,用来提取需要的内容的. 下面就一步一步来讲功能实现. 因为是采集小说,所以首先要将书名.作者.类型这三个提取出来,别的信息可根据需要提取. 这里以
-
淘宝IP地址库采集器c#代码
采集器概貌,如下: 最近做一个项目,功能类似于CNZZ站长统计功能,要求显示Ip所在的省份市区/提供商等信息.网上的Ip纯真数据库,下载下来一看,发现没提供商内容,省市区都很少,居然有XXX网吧,哥瞬间倒了.没标准化.并且杂乱.还不连续的IP段.总体说来没达到要求. 在百度上找啊找,找到淘宝Ip地址库,官方介绍的相当诱人,准确率高,数据质量有保障,提供国家.省.市.县.运营商全方位信息,信息维度广,格式规范,但是限制每秒10次的访问(这个比较无语). 淘宝IP地址库,提供API http:
-
Python实现批量采集商品数据的示例详解
目录 本次目的 知识点 开发环境 代码 本次目的 python批量采集某商品数据 知识点 requests 发送请求 re 解析网页数据 json 类型数据提取 csv 表格数据保存 开发环境 python 3.8 pycharm requests 代码 导入模块 import json import random import time import csv import requests import re import pymysql 核心代码 # 连接数据库 def save_sql(t
-
火车头采集器3.0采集图文教程
以采集示例详解部分功能今天要给大家做示例的网站是163的 娱乐频道 这个应该是个比较通用和实用的规则,下面开始.如果您是火车采集器的老手,那么您可以参考下,因为我要讲解的会有违传统的思维:如我您是新手那么您最好能仔细看下,因为这将加快您的入门,同时在以后给您节省很多时间.以下是一些采集的基本步骤,您可以灵活运用:一.建立站点1.请先打开火车采集器,新建站点,看下图:为了方便管理您可以为您的站点取任何的您觉得易记的名称,但是我建议用目标源的名字作为站点的名称有利于日后的管理,如下图大部分的站点,通
-
火车采集器 免费版使出收费版本功能实现原理
hi 各位免费火车头采集器的采友: 火车头免费版本不支持采集结果的外挂处理,比如采用php来辅助处理结果,而火车头本身对于正则表达式的不完整支持, 导致对于采集一些有混淆文字的内容效果不好,那么咱们怎么做到过滤那些混淆字串呢? 其实很简单--采用服务器端过滤 比如采集发送到服务器端是: $_POST = array("subject"=> "这里是标题","content"=> "<div class='1fadfaf
-
shell脚本实现批量采集爱站关键词库
shell批量采集爱站关键词库,心血来潮写着玩的,还不完善,先放出来,后期慢慢更新,功能虽然简单,同类工具也很多现成的,但毕竟是自己写出来的工具,感觉还是很不一样滴! 复制代码 代码如下: for i in $(seq 1 50);do curl -s http://baidurank.aizhan.com/baidu/jiameng.com/$i/position/|grep -a 'class="zhishu"'|sed 's/<a target="_blank&q