python爬取全国火锅店数量并可视化展示
目录
- 一、网页分析
- 二、获取数据
- 1.导入相关库
- 2.请求数据
- 3.保存到excel
- 三、数据可视化
- 1.全国火锅店数量分布
- 2.四川火锅店数量分布
- 四、小结
前言:
今天教大家如何获取全国不同城市火锅店数量情况,并将这些数据进行可视化展示,以更加直观的方式去浏览全国不同省份、不同城市的火锅店分布情况。
本文数据来自于某度地图,通过python技术知识去获取数据并进行可视化。
一、网页分析
首先先看一下数据源,在某度地图里面按照下方操作,就可以请求到全国的火锅店情况(从下图来看没有显示出来,但是通过Network,可以看到数据)
再network中,找到下面这个数据包:
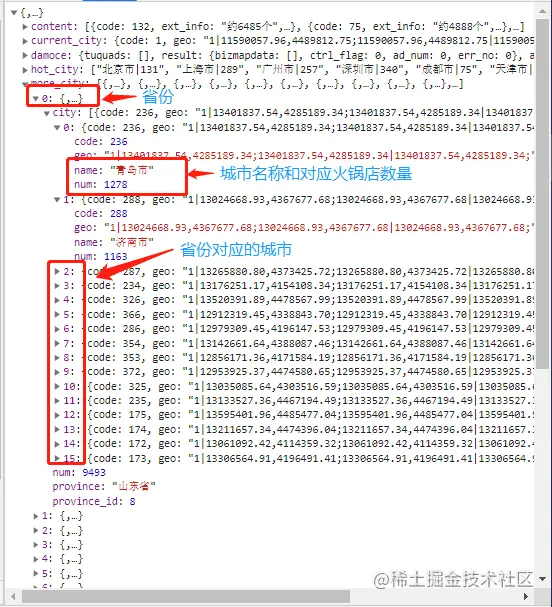
打开之后可以看到json数据:
二、获取数据
对网页分析好之后,接下来可以借助Python技术进行获取数据,并保存到excel中。
1.导入相关库
import json import requests import openpyxl
2.请求数据
下面开始编写请求数据代码(请求时记得带上headers)
###请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36",
'Referer':'https://map.baidu.com/@12949550.923158279,3712445.9716704674,6.28z',
"Cookie":";"你的cookie",
}
##请求链接
url = "https://map.baidu.com/?newmap=1&reqflag=pcmap&biz=1&from=webmap&da_par=direct&pcevaname=pc4.1&qt=s&da_src=searchBox.button&wd=%E7%81%AB%E9%94%85%E5%BA%97&c=1&src=0&wd2=&pn=0&sug=0&l=6&b=(10637065.476146251,2368134.592189369;12772445.910805061,5056757.351151566)&from=webmap&biz_forward={%22scaler%22:1,%22styles%22:%22pl%22}&sug_forward=&auth=NTSwAZUMzIaTTdWD4WAv0731cWF3MQEauxLxREHzERRtykiOxAXXw1GgvPUDZYOYIZuVt1cv3uVtGccZcuVtPWv3GuztQZ3wWvUvhgMZSguxzBEHLNRTVtcEWe1GD8zv7ucvY1SGpuxVthgW1aDeuxtf0wd0vyMySFIAFM7ueh33uTtAffbDF&seckey=c6d9c7e05d7e627c56ed46fab5d7c5c792064779599d5e12b955a6f18a1204375d1588206c94d22e4bdd1ade0ad06e78c21917e24c6223b96bc51b75ca38651a1b203a0609f126163c5e82fd0549a068e537303424837ab798acfc9088e5d76a66451c20ebd9599b41c9b4f1371850d20fa442ad464712f54c912422f4fa20b3052f8bb810f30d41c7c0e55af68f9d9d973537f03d0aa0a1d1617d78cae29b49c64c2d2dc3f44cf0f8799234b124a7a2dec18bfa011e097e31a508eae37b8603f97df8f935f04b3652f190eac52d04816f302a582c53971e515ff2e0e2b4cc30446e0bee48d51c4be8b6fe4185589ed9&device_ratio=1&tn=B_NORMAL_MAP&nn=0&u_loc=12677548,2604239&ie=utf-8&t=1618452491622"
###响应数据
response = requests.get(url,headers=headers).json()
这里的cookie可以在浏览器network中复制即可。

通过返回的json数据可知道,我们的目标数据在more_city中,里面是列表数据是省份(provice是省份名称,num是火锅店数量),紧接着每一个省份里都有city(列表),里面是对应着省份的城市(name是城市名称,num是对应城市火锅店数量)
response = response['more_city']
for i in response:
city = i['city']
print(i['province'])
print(i['num'])
for j in city:
print(j['name'])
print(j['num'])

3.保存到excel
省份和城市分别保存到两个不同的excel中
outwb_p = openpyxl.Workbook()
outws_p = outwb_p.create_sheet(index=0)
outws_p.cell(row=1, column=1, value="省份")
outws_p.cell(row=1, column=2, value="数量")
outwb_c = openpyxl.Workbook()
outws_c = outwb_c.create_sheet(index=0)
outws_c.cell(row=1, column=1, value="城市")
outws_c.cell(row=1, column=2, value="数量")
##################
###在循环中写入数据
##################
### 保存全国省份火锅数量-李运辰”
outwb_p.save("全国省份火锅数量-李运辰.xls") # 保存
### 保存全国城市火锅数量-李运辰”
outwb_c.save("全国城市火锅数量-李运辰.xls") # 保存


三、数据可视化
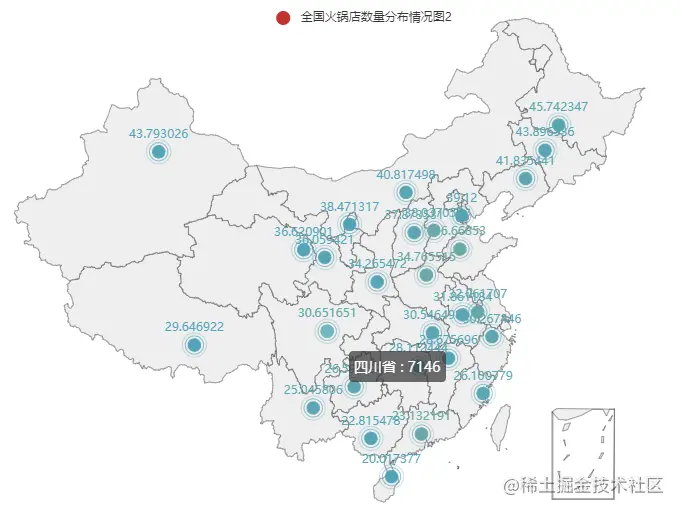
1.全国火锅店数量分布
datafile = u'全国省份火锅数量-李运辰.xls'
data = pd.read_excel(datafile)
attr = data['省份'].tolist()
value = data['数量'].tolist()
name = []
for i in attr:
if "省" in i:
name.append(i.replace("省",""))
else:
name.append(i)
from pyecharts import options as opts
from pyecharts.charts import Map
from pyecharts.faker import Faker
c = (
Map()
.add("数量", [list(z) for z in zip(name, value)], "china")
.set_global_opts(title_opts=opts.TitleOpts(title="全国火锅店数量分布情况"))
.render("全国火锅店数量分布情况.html")
)

还可以这样画:
datafile = u'全国省份火锅数量-李运辰.xls'
df = pd.read_excel(datafile)
province_distribution = df[['省份', '数量']].values.tolist()
geo = Geo()
geo.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
geo.add_schema(maptype="china")
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=110000))
# 加入数据
geo.add('全国火锅店数量分布情况图2', province_distribution, type_=ChartType.EFFECT_SCATTER)
geo.render("全国火锅店数量分布情况图2.html")
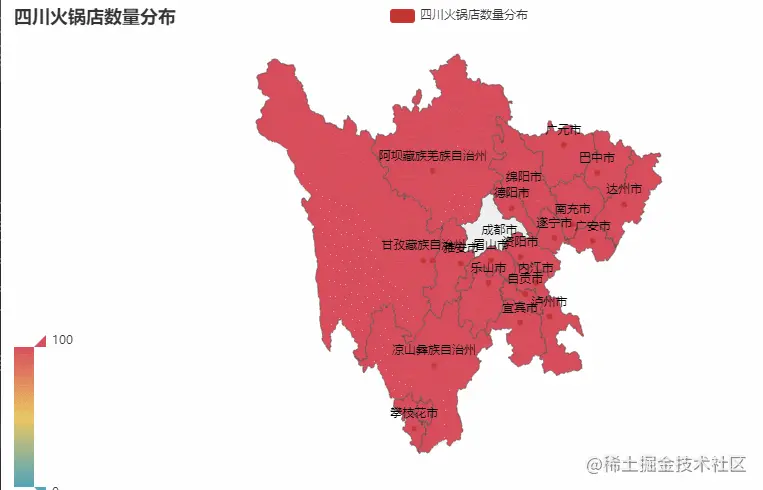
2.四川火锅店数量分布
为了绘制城市的分布图,选择了四川省为例进行绘制(如果要绘制全国的所有城市,那样出来的图密密麻麻,不美观)
datafile = u'全国城市火锅数量-李运辰.xls'
data = pd.read_excel(datafile)
city = data['城市'].tolist()
values2 = data['数量'].tolist()
###四川
name = []
value = []
flag = 0
for i in range(0,len(city)):
if city[i] =="绵阳市":
flag = 1
if flag:
name.append(city[i])
value.append(int(values2[i]))
if city[i] =="甘孜藏族自治州":
name.append(city[i])
value.append(int(values2[i]))
break
c = (
Map()
.add("四川火锅店数量分布", [list(z) for z in zip(name, value)], "四川")
.set_global_opts(
title_opts=opts.TitleOpts(title="四川火锅店数量分布"), visualmap_opts=opts.VisualMapOpts()
)
.render("四川火锅店数量分布.html")
)
四、小结
到此这篇关于python爬取全国火锅店数量并可视化展示的文章就介绍到这了,更多相关python可视化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬取雪中悍刀行弹幕分析并可视化详程
目录 哔哔一下 爬虫部分 代码部分 效果展示 数据可视化 代码展示 效果展示 福利环节 哔哔一下 雪中悍刀行兄弟们都看过了吗?感觉看了个寂寞,但又感觉还行,原谅我没看过原著小说~ 豆瓣评分5.8,说明我还是没说错它的. 当然,这并不妨碍它波播放量嘎嘎上涨,半个月25亿播放,平均一集一个亿,就是每天只有一集有点难受. 我们今天就来采集一下它的弹幕,实现数据可视化,看看弹幕文化都输出了什么~ 爬虫部分 我们将它的弹幕先采集下来,保存到Excel表格~ 首先安装一下这两个模块 requests # 发
-
Python爬取当网书籍数据并数据可视化展示
目录 一.开发环境 二.模块使用 三.爬虫代码实现步骤 1. 导入所需模块 2. 发送请求, 用python代码模拟浏览器发送请求 3. 解析数据, 提取我们想要数据内容 4. 多页爬取 5. 保存数据, 保存csv表格里面 四.数据可视化 1.导入所需模块 2.导入数据 3.可视化 一.开发环境 Python 3.8 Pycharm 2021.2 专业版 二.模块使用 csv 模块 把爬取下来的数据保存表格里面的 内置模块requests >>> pip install request
-
Python实现爬取天气数据并可视化分析
目录 核心功能设计 实现步骤 爬取数据 风向风级雷达图 温湿度相关性分析 24小时内每小时时段降水 24小时累计降雨量 今天我们分享一个小案例,获取天气数据,进行可视化分析,带你直观了解天气情况! 核心功能设计 总体来说,我们需要先对中国天气网中的天气数据进行爬取,保存为csv文件,并将这些数据进行可视化分析展示. 拆解需求,大致可以整理出我们需要分为以下几步完成: 1.通过爬虫获取中国天气网7.20-7.21的降雨数据,包括城市,风力方向,风级,降水量,相对湿度,空气质量. 2.对获取的天气数
-
Python爬取股票交易数据并可视化展示
目录 开发环境 第三方模块 爬虫案例的步骤 爬虫程序全部代码 分析网页 导入模块 请求数据 解析数据 翻页 保存数据 实现效果 数据可视化全部代码 导入数据 读取数据 可视化图表 效果展示 开发环境 解释器版本: python 3.8 代码编辑器: pycharm 2021.2 第三方模块 requests: pip install requests csv 爬虫案例的步骤 1.确定url地址(链接地址) 2.发送网络请求 3.数据解析(筛选数据) 4.数据的保存(数据库(mysql\mong
-
Python爬虫入门案例之爬取去哪儿旅游景点攻略以及可视化分析
目录 知识点 第三方库 开发环境: 爬虫程序 导入模块 发送请求 获取数据(网页源代码) 解析网页(re正则表达式,css选择器,xpath,bs4/六年没更新了,json) 向详情页网站发送请求(get,post) 解析网页 保存数据 数据可视化 导入模块 导入数据 旅游胜地Top10及对应费用 出游方式分析 出游时间分析 出游玩法分析 知识点 requests 发送网络请求 parsel 解析数据 csv 保存数据 第三方库 requests >>> pip install requ
-
Python爬虫爬取疫情数据并可视化展示
目录 知识点 开发环境 爬虫完整代码 导入模块 分析网站 发送请求 获取数据 解析数据 保存数据 数据可视化 导入模块 读取数据 死亡率与治愈率 各地区确诊人数与死亡人数情况 知识点 爬虫基本流程 json requests 爬虫当中 发送网络请求 pandas 表格处理 / 保存数据 pyecharts 可视化 开发环境 python 3.8 比较稳定版本 解释器发行版 anaconda jupyter notebook 里面写数据分析代码 专业性 pycharm 专业代码编辑器 按照年份与月
-
python爬取全国火锅店数量并可视化展示
目录 一.网页分析 二.获取数据 1.导入相关库 2.请求数据 3.保存到excel 三.数据可视化 1.全国火锅店数量分布 2.四川火锅店数量分布 四.小结 前言: 今天教大家如何获取全国不同城市火锅店数量情况,并将这些数据进行可视化展示,以更加直观的方式去浏览全国不同省份.不同城市的火锅店分布情况. 本文数据来自于某度地图,通过python技术知识去获取数据并进行可视化. 一.网页分析 首先先看一下数据源,在某度地图里面按照下方操作,就可以请求到全国的火锅店情况(从下图来看没有显示出来,但是
-
python爬取全国水雨情信息详解
目录 分析 代码 结果 总结 分析 我们没有找到接口,所以打算利用selenium来爬取. 代码 import datetime import pandas as pd from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from
-
Python爬取奶茶店数据分析哪家最好喝以及性价比
目录 序篇 数据获取 数据清洗 数据可视化 热门城市奶茶店铺数量情况 特色奶茶分布情况 大众奶茶分布情况 总结 序篇 天气真的很热啊… 很想有一杯冰冰凉凉的奶茶来解渴~ 但是现在奶茶店这么多, 到底哪一家最好喝.性价比最高呢? 数据获取 本文抓取了12个热门城市的奶茶店名单, 城市包括:北京.上海.广州.深圳.天津.西安.重庆.杭州.南京.武汉.成都和长沙. 共计68614家奶茶店,3万多个奶茶品牌. 在构建抓取URL时, 需要注意将城市的维度具体到城市商圈, 因为每个URL最多只显示32页内容
-
用Python爬取各大高校并可视化帮弟弟选大学,弟弟直呼牛X
一.获取url 打开中国教育在线网,按 F12,顶部选择NetWork,选择XHR 刷新页面,观察url,通过对Reponse的分析找到真正的url为:https://api.eol.cn/gkcx/api/ 数据存储在Json中. 再点击Headers,查看请求参数 请求方式为POST 二.发送请求 拿到url,我们就可以利用requests模拟浏览器发送请求,拿到返回的Json数据.代码如下: # 导入包 import numpy as np import pandas as pd impo
-
Python爬取附近餐馆信息代码示例
本代码主要实现抓取大众点评网中关村附近的餐馆有哪些,具体如下: import urllib.request import re def fetchFood(url): # 模拟使用浏览器浏览大众点评的方式浏览大众点评 headers = {'User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'} ope
-
详解python 爬取12306验证码
一个简单的验证码爬取程序 本文介绍了在Python2.7环境下爬取网站验证码: 思路就是获取验证码对应的url,然后发起requst请求,读取该URL对应的内容,然后写入到一个本地文件,实现一个验证码的保存.大量下载可以把以上程序写入一个死循环 代码实现部分: import ssl import urllib2 i=1 import time while(1): #不加的话,无法访问12306 ssl._create_default_https_context = ssl._create_unv
-
python爬取Ajax动态加载网页过程解析
常见的反爬机制及处理方式 1.Headers反爬虫 :Cookie.Referer.User-Agent 解决方案: 通过F12获取headers,传给requests.get()方法 2.IP限制 :网站根据IP地址访问频率进行反爬,短时间内进制IP访问 解决方案: 1.构造自己IP代理池,每次访问随机选择代理,经常更新代理池 2.购买开放代理或私密代理IP 3.降低爬取的速度 3.User-Agent限制 :类似于IP限制 解决方案: 构造自己的User-Agent池,每次访问随机选择 5.
-
python 爬取疫情数据的源码
疫情数据 程序源码 // An highlighted block import requests import json class epidemic_data(): def __init__(self, province): self.url = url self.header = header self.text = {} self.province = province # self.r=None def down_page(self): r = requests.get(url=url
-
Python爬取新型冠状病毒“谣言”新闻进行数据分析
一.爬取数据 话不多说了,直接上代码( copy即可用 ) import requests import pandas as pd class SpiderRumor(object): def __init__(self): self.url = "https://vp.fact.qq.com/loadmore?artnum=0&page=%s" self.header = { "User-Agent": "Mozilla/5.0 (iPhone;
-
用Python 爬取猫眼电影数据分析《无名之辈》
前言 作者: 罗昭成 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef 获取猫眼接口数据 作为一个长期宅在家的程序员,对各种抓包简直是信手拈来.在 Chrome 中查看原代码的模式,可以很清晰地看到接口,接口地址即为:http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&o