python数据解析之XPath详解
目录
- XPath
- XPath使用方法
- 案例—58二手房
- 总结
XPath
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
xpath是最常用且最便捷高效的一种解析方式,通用型强,其不仅可以用于python语言中,还可以用于其他语言中,数据解析建议首先xpath。
XPath使用方法
xpath解析原理:
实例化一个etree的对象,且需要将被解析的页面源代码数据加载到该对象中
调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
安装lxml
pip install -i https://mirrors.aliyun.com/pypi/simple/ lxml
from lxml import etree
tree = etree.parse('./tree.html') #从本地加载源码,实例化一个etree对象。必须是本地的文件,不能是字符串
tree = etree.HTML(源码) #从互联网加载源码,实例化etree对象
# / 表示从从根节点开始,一个 / 表示一个层级,//表示多个层级
r = tree.xpath('//div//a') #以列表的形式返回div下的所有的a标签对象的地址
r = tree.xpath('//div//a')[1] #返回div下的第二个a标签对象地址
r = tree.xpath('//div[@class="tang"]') #以列表的形式返回tang标签地址
r = tree.xpath('//div[@class="tang"]//a') #以列表的形式返回tang标签下所有的a标签地址
#获取标签中的文本内容
r = tree.xpath('//div[@class="tang"]//a/text()') #以列表的形式返回所有a标签中的文本
#获取标签中属性值
r = tree.xpath('//div//a/@href') ##以列表的形式返回所有a标签中href属性值
tree.html
<html lang="en">
<head>
<meta charset="utf-8" />
<meta name="theme-color" content="#ffffff"></meta>
<title>xpaht测试</title>
</head>
<body>
<div>
<p>百里守约</p>
</div>
<div class="song">
<p>前程似锦</p>
</div>
<div class="song">
<p>前程似锦2</p>
</div>
<div class="ming"> #后面改了名字
<p>以梦为马</p>
</div>
<div class="tang">
<ul>
<li><a href='http://123.com' title='qing'>清明时节</a></li>
<li><a href='http://ws.com' title='qing'>秦时明月</a></li>
<li><a href='http://xzc.com' title='qing'>汉时关</a></li>
</ul>
</div>
<flink-root></flink-root>
<script type="text/javascript" src="runtime.0dcf16aad31edd73d8e8.js"></script>
<script type="text/javascript" src="es2015-polyfills.923637a8e6d276e6f6df.js"></script>
<script type="text/javascript" src="polyfills.bb2456cce5322b484b77.js"></script>
<script type="text/javascript" src="main.8128365baee3dc30e607.js"></script>
</body>
</html>
案例—58二手房
将页面中的房源名称解析出来,即将title值解析出来就行
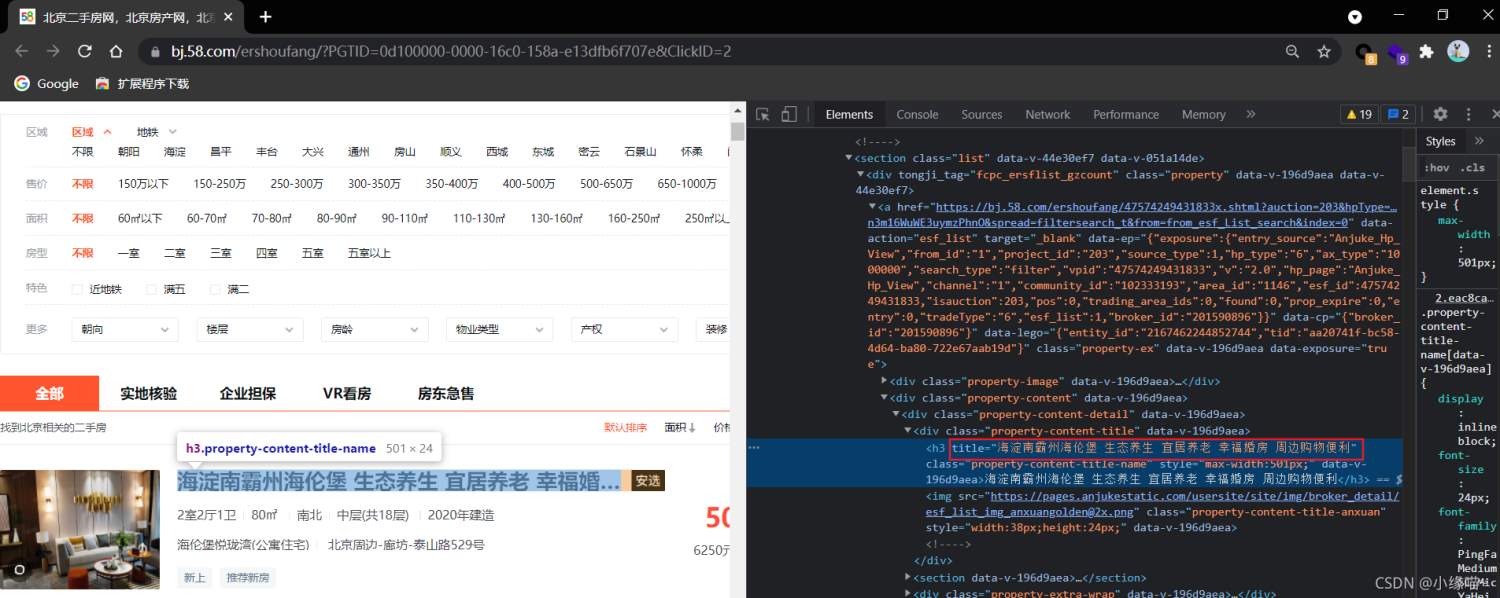
思路
- 获取房源名称所在的url,并获取其响应数据
- 数据解析,构造xpath表达式。提取目标数据
import requests
from lxml import etree
url = "https://bj.58.com/ershoufang/p1/"
headers={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Mobile Safari/537.36'
}
pag_response = requests.get(url,headers=headers,timeout=3).text
#实例化一个etree对象
tree = etree.HTML(pag_response)
r = tree.xpath('//span[@class="content-title"]/text()') #获取所有//span标签为"content-title"的文本内容
print(r)
Tips:我们使用xpath进行数据解析时,不能直接看元素就进行构造xpath表达式,以为很多情况下从浏览中看的元素结构和爬取下来的源码结构不一样。所以正确方法是先将源码爬下来再观察进行构造xpath。
如下浏览器中的元素结构和爬取的元素结构就不一样。如果按照浏览器汇总的元素来构造xpath表达式,则不会解析成功!

总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

Python爬虫之用Xpath获取关键标签实现自动评论盖楼抽奖(二)
一.分析链接 上一篇文章指路 一般来说,我们参加某个网站的盖楼抽奖活动,并不是仅仅只参加一个,而是多个盖楼活动一起参加. 这个时候,我们就需要分析评论的链接是怎么区分不同帖子进行评论的,如上篇的刷帖链接,具体格式如下: https://club.hihonor.com/cn/forum.php?mod=post&action=reply&fid=154&tid=21089001&extra=page%3D1&replysubmit=yes&infloat=y
-
python动态网站爬虫实战(requests+xpath+demjson+redis)
目录 前言 一.主要思路 1.观察网站 2.编写爬虫代码 二.爬虫实战 1.登陆获取cookie 三.总结 前言 之前简单学习过python爬虫基础知识,并且用过scrapy框架爬取数据,都是直接能用xpath定位到目标区域然后爬取.可这次碰到的需求是爬取一个用asp.net编写的教育网站并且将教学ppt一次性爬取下来,由于该网站部分内容渲染采用了js,所以比较难用xpath直接定位,同时发起下载ppt的请求比较难找. 经过琢磨和尝试后爬取成功,记录整个爬取思路供自己和大家学习.文章比较详细,对
-
python数据XPath使用案例详解
目录 XPath XPath使用方法 xpath解析原理: 安装lxml 案例-58二手房 XPath XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言. XPath使用方法 xpath解析原理: 1.实例化一个etree的对象,且需要将被解析的页面源代码数据加载到该对象中 2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获 安装lxml pip install -i https://mirro
-
Python爬虫必备之XPath解析库
一.简介 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历.XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上. Xpath解析库介绍:数据解析的过程中使用过正则表达式, 但正则表达式想要进准匹配难度较高, 一旦正则表达式书写错误, 匹配的数据也会出错. 网页由三部分组成: HTML, Css, JavaScript, HTML页面标签存在层级关系, 即DOM树,
-
python网络爬虫精解之XPath的使用说明
目录 一.XPath的介绍 二.XPath使用 1.选取所有节点 2.获取子节点 3.获取父节点 4.属性匹配 5.文本获取 6.属性获取 7.属性多值匹配 8.多属性匹配 9.按序选择 10.节点轴选择 XPath的使用 一.XPath的介绍 XPath的几个常用规则: 表达式 描述 nodename 选取此节点的所有子节点 / 从当前节点选取直接子节点 // 从当前节点选取子孙节点 . 选取当前节点 - 选取当前节点的父节点 @ 选取属性 二.XPath使用 1.选取所有节点 test01.
-
python使用xpath获取页面元素的使用
关于python 使用xpath获取网页信息的方法? 1.xpath的使用方法? XPath 使用路径表达式来选取 XML 文档中的节点或节点集.节点是通过沿着路径 (path) 或者步 (steps) 来选取的. 常用路径表达式含义 表达式 描述 / 从根节点选取(取子节点) // 选择的当前节点选择文档中的节点 . 选取当前节点. - 选取当前节点的父节点. @ 选取属性 * 表示任意内容(通配符) | 运算符可以选取多个路径 常用功能函数 函数 用法 解释 startswith() x
-
python数据解析之XPath详解
目录 XPath XPath使用方法 案例-58二手房 总结 XPath XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言. xpath是最常用且最便捷高效的一种解析方式,通用型强,其不仅可以用于python语言中,还可以用于其他语言中,数据解析建议首先xpath. XPath使用方法 xpath解析原理: 实例化一个etree的对象,且需要将被解析的页面源代码数据加载到该对象中 调用etree对象中的xpath方法结合着xpath
-
Python数据存储之 h5py详解
1.Python数据存储(压缩) (1)numpy.save , numpy.savez , scipy.io.savemat numpy和scipy内建的数据存储方式. (2)cPickle + gzip cPickle是pickle内建的数据存储方式,gzip是常用的文件压缩模块. (3)h5py h5py是对HDF5文件格式进行读写的python包,关于h5py更多介绍与安装,参考官方网站 关于HDF5,参考官方网站.: 一个HDF5文件就是一个由两种基本数据对象(groups and d
-
Python数据可视化绘图实例详解
目录 利用可视化探索图表 1.数据可视化与探索图 2.常见的图表实例 数据探索实战分享 1.2013年美国社区调查 2.波士顿房屋数据集 利用可视化探索图表 1.数据可视化与探索图 数据可视化是指用图形或表格的方式来呈现数据.图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义.用户通过探索图(Exploratory Graph)可以了解数据的特性.寻找数据的趋势.降低数据的理解门槛. 2.常见的图表实例 本章主要采用 Pandas 的方式来画图,而不是使用 Matpl
-
Python 数据科学 Matplotlib图库详解
Matplotlib 是 Python 的二维绘图库,用于生成符合出版质量或跨平台交互环境的各类图形. 图形解析与工作流 图形解析 工作流 Matplotlib 绘图的基本步骤: 1 准备数据 2 创建图形 3 绘图 4 自定义设置 5 保存图形 6 显示图形 import matplotlib.pyplot as plt x = [1,2,3,4] # step1 y = [10,20,25,30] fig = plt.figure() # step2 ax = fig.add_subpl
-
Python 数据可视化之Matplotlib详解
目录 使用的数据库 tips 数据库 Matplotlib 散点图 折线图 条形图 直方图 总结 在深入研究这些库之前,首先,我们需要一个数据库来绘制数据.我们将在本完整教程中使用 tips database.让我们讨论一下这个数据库的简介. 使用的数据库 tips 数据库 tips 数据库是20世纪90年代初期顾客在餐厅的两个半月的小费记录.它包含 6 列,例如 total_bill.tip.sex.smoker.day.time.size. 您可以从这里下载 tips 数据库. 例子: im
-
Python 数据可视化之Bokeh详解
目录 安装 散点图 折线图 条形图 交互式数据可视化 Interactive Legends 添加小部件 按钮 复选框 单选按钮 总结 安装 要安装此类型,请在终端中输入以下命令. pip install bokeh 散点图 散点图中散景可以使用绘图模块的散射()方法被绘制.这里分别传递 x 和 y 坐标. 例子: # 导入模块 from bokeh.plotting import figure, output_file, show from bokeh.palettes import magm
-
Python 数据可视化之Seaborn详解
目录 安装 散点图 线图 条形图 直方图 总结 安装 要安装 seaborn,请在终端中输入以下命令. pip install seaborn Seaborn 建立在 Matplotlib 之上,因此它也可以与 Matplotlib 一起使用.一起使用 Matplotlib 和 Seaborn 是一个非常简单的过程.我们只需要像之前一样调用 Seaborn Plotting 函数,然后就可以使用 Matplotlib 的自定义函数了. 注意: Seaborn 加载了提示.虹膜等数据集,但在本教程
-
Python命令行解析器argparse详解
目录 第1章 argparse简介 1.1 解析 1.2 argparse定义三步骤 1.3 代码示例 第2章 参数详解 2.1 创建一个命令行解析器对象:ArgumentParser() 2.2 为命令行添加参数: add_argument() 方法 2.3 解析命令行的参数:parse_args() 2.4 命令行参数的输入 2.5 命令行参数的使用 总结 第1章 argparse简介 1.1 解析 argparse 模块是 Python 内置的一个用于命令项选项与参数解析的模块,argp
-
Python实现数据的序列化操作详解
目录 Json 模块 dumps()函数 dump()函数 loads()函数 load()函数 Pickle 模块 dumps()函数 dump()函数 loads()函数 load()函数 总结 在日常开发中,对数据进行序列化和反序列化是常见的数据操作,Python提供了两个模块方便开发者实现数据的序列化操作,即 json 模块和 pickle 模块.这两个模块主要区别如下: json 是一个文本序列化格式,而 pickle 是一个二进制序列化格式: json 是我们可以直观阅读的,而 p
-
Python统计学一数据的概括性度量详解
一.数据的概括性度量 1.统计学概括: 统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析.总结,并进而进行推断和预测,为相关决策提供依据和参考.统计学主要又分为描述统计学和推断统计学.给定一组数据,统计学可以摘要并且描述这份数据,这个用法称作为描述统计学.另外,观察者以数据的形态建立出一个用以解释其随机性和不确定性的数学模型,以之来推论研究中的步骤及母体,这种用法被称做推论统计学. 2.数据的概括性度量: 1)集中趋势的度量: 众数:众数(Mode