go zero微服务实战处理每秒上万次的下单请求
目录
- 引言
- 处理热点数据
- 优化
- 限制
- 隔离
- 流量削峰
- 如何保证消息只被消费一次
- 代码实现
- 结束语
引言
在前几篇的文章中,我们花了很大的篇幅介绍如何利用缓存优化系统的读性能,究其原因在于我们的产品大多是一个读多写少的场景,尤其是在产品的初期,可能多数的用户只是过来查看商品,真正下单的用户非常少。
但随着业务的发展,我们就会遇到一些高并发写请求的场景,秒杀抢购就是最典型的高并发写场景。在秒杀抢购开始后用户就会疯狂的刷新页面让自己尽早的看到商品,所以秒杀场景同时也是高并发读场景。那么应对高并发读写场景我们怎么进行优化呢?
处理热点数据
秒杀的数据通常都是热点数据,处理热点数据一般有几种思路:一是优化,二是限制,三是隔离。
优化
优化热点数据最有效的办法就是缓存热点数据,我们可以把热点数据缓存到内存缓存中。
限制
限制更多的是一种保护机制,当秒杀开始后用户就会不断地刷新页面获取数据,这时候我们可以限制单用户的请求次数,比如一秒钟只能请求一次,超过限制直接返回错误,返回的错误尽量对用户友好,比如 "店小二正在忙" 等友好提示。
隔离
秒杀系统设计的第一个原则就是将这种热点数据隔离出来,不要让1%的请求影响到另外的99%,隔离出来后也更方便对这1%的请求做针对性的优化。
具体到实现上,我们需要做服务隔离,即秒杀功能独立为一个服务,通知要做数据隔离,秒杀所调用的大部分是热点数据,我们需要使用单独的Redis集群和单独的Mysql,目的也是不想让1%的数据有机会影响99%的数据。
流量削峰
- 针对秒杀场景,它的特点是在秒杀开始那一刹那瞬间涌入大量的请求,这就会导致一个特别高的流量峰值。但最终能够抢到商品的人数是固定的,也就是不管是100人还是10000000人发起请求的结果都是一样的,并发度越高,无效的请求也就越多。
- 但是从业务角度来说,秒杀活动是希望有更多的人来参与的,也就是秒杀开始的时候希望有更多的人来刷新页面,但是真正开始下单时,请求并不是越多越好。
- 因此我们可以设计一些规则,让并发请求更多的延缓,甚至可以过滤掉一些无效的请求。
- 削峰本质上是要更多的延缓用户请求的发出,以便减少和过滤掉一些无效的请求,它遵从请求数要尽量少的原则。
- 我们最容易想到的解决方案是用消息队列来缓冲瞬时的流量,把同步的直接调用转换成异步的间接推送,中间通过一个队列在一端承接瞬时的流量洪峰,在另一端平滑的将消息推送出去,如下图所示:
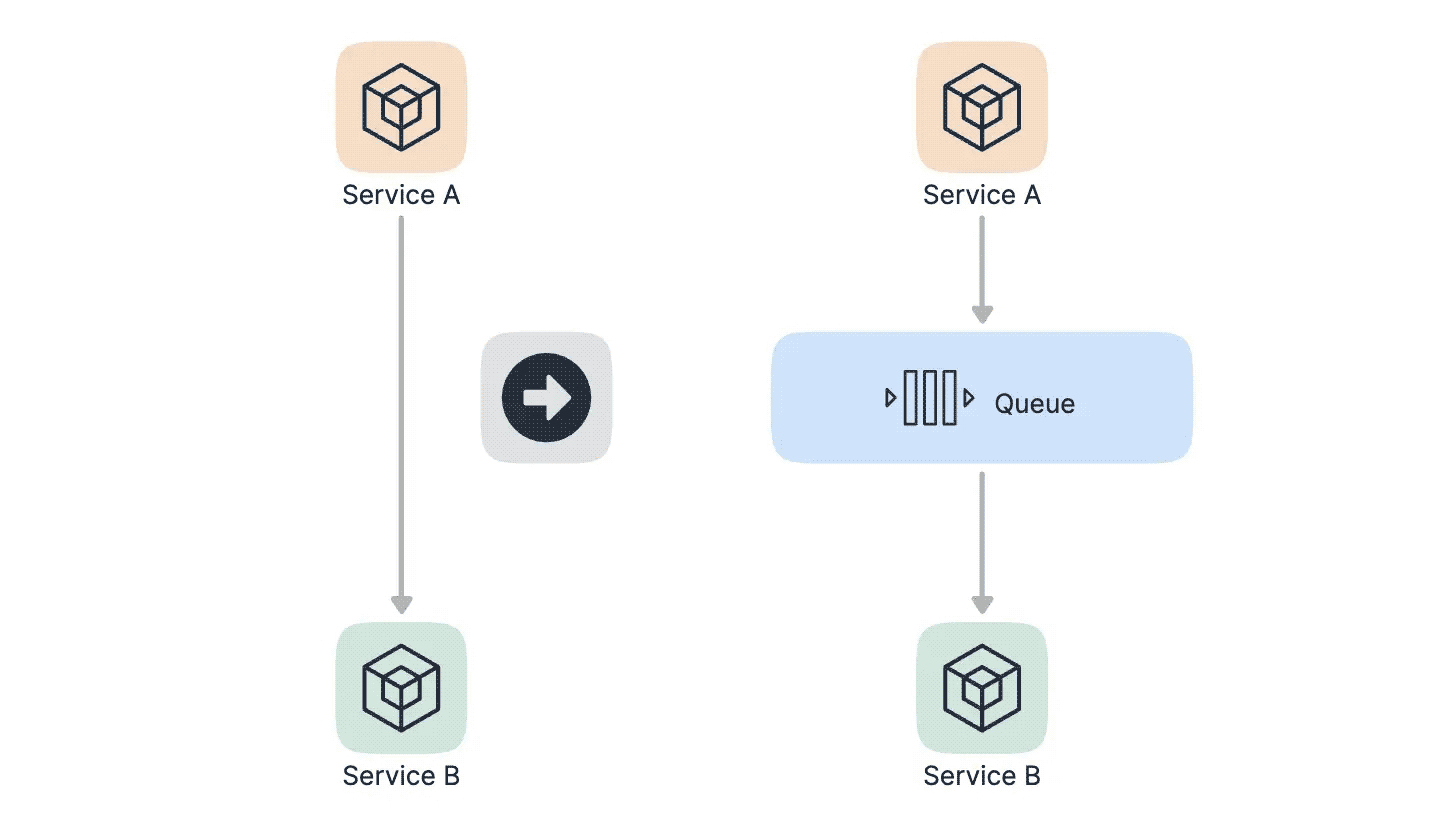
采用消息队列异步处理后,那么秒杀的结果是不太好同步返回的,所以我们的思路是当用户发起秒杀请求后,同步返回响应用户 "秒杀结果正在计算中..." 的提示信息,当计算完之后我们如何返回结果给用户呢?其实也是有多种方案的。
- 一是在页面中采用轮询的方式定时主动去服务端查询结果,例如每秒请求一次服务端看看有没有处理结果,这种方式的缺点是服务端的请求数会增加不少。
- 二是主动push的方式,这种就要求服务端和客户端保持长连接了,服务端处理完请求后主动push给客户端,这种方式的缺点是服务端的连接数会比较多。
还有一个问题就是如果异步的请求失败了该怎么办?我觉得对于秒杀场景来说,失败了就直接丢弃就好了,最坏的结果就是这个用户没有抢到而已。如果想要尽量的保证公平的话,那么失败了以后也可以做重试。
如何保证消息只被消费一次
kafka是能够保证"At Least Once"的机制的,即消息不会丢失,但有可能会导致重复消费,消息一旦被重复消费那么就会造成业务逻辑处理的错误,那么我们如何避免消息的重复消费呢?
我们只要保证即使消费到了重复的消息,从消费的最终结果来看和只消费一次的结果等同就好了,也就是保证在消息的生产和消费的过程是幂等的。
什么是幂等呢?
- 如果我们消费一条消息的时候,要给现有的库存数量减1,那么如果消费两条相同的消息就给库存的数量减2,这就不是幂等的。
- 而如果消费一条消息后处理逻辑是将库存的数量设置为0,或者是如果当前库存的数量为10时则减1,这样在消费多条消息时所得到的结果就是相同的,这就是幂等的。
- 说白了就是一件事无论你做多少次和做一次产生的结果都是一样的,那么这就是幂等性。
我们可以在消息被消费后,把唯一id存储在数据库中,这里的唯一id可以使用用户id和商品id的组合,在处理下一条消息之前先从数据库中查询这个id看是否被消费过,如果消费过就放弃。伪代码如下:
isConsume := getByID(id)
if isConsume {
return
}
process(message)
save(id)
还有一种方式是通过数据库中的唯一索引来保证幂等性,不过这个要看具体的业务,在这里不再赘述。
代码实现
整个秒杀流程图如下:

使用kafka作为消息队列,所以要先在本地安装kafka,我使用的是mac可以用homebrew直接安装,kafka依赖zookeeper也会自动安装
brew install kafka
安装完后通过brew services start启动zookeeper和kafka,kafka默认侦听在9092端口
brew services start zookeeper brew services start kafka
seckill-rpc的SeckillOrder方法实现秒杀逻辑,我们先限制用户的请求次数,比如限制用户每秒只能请求一次,这里使用go-zero提供的PeriodLimit功能实现,如果超出限制直接返回
code, _ := l.limiter.Take(strconv.FormatInt(in.UserId, 10))
if code == limit.OverQuota {
return nil, status.Errorf(codes.OutOfRange, "Number of requests exceeded the limit")
}
接着查看当前抢购商品的库存,如果库存不足就直接返回,如果库存足够的话则认为可以进入下单流程,发消息到kafka,这里kafka使用go-zero提供的kq库,非常简单易用,为秒杀新建一个Topic,配置初始化和逻辑如下:
Kafka:
Addrs:
- 127.0.0.1:9092
SeckillTopic: seckill-topic
KafkaPusher: kq.NewPusher(c.Kafka.Addrs, c.Kafka.SeckillTopic)
p, err := l.svcCtx.ProductRPC.Product(l.ctx, &product.ProductItemRequest{ProductId: in.ProductId})
if err != nil {
return nil, err
}
if p.Stock <= 0 {
return nil, status.Errorf(codes.OutOfRange, "Insufficient stock")
}
kd, err := json.Marshal(&KafkaData{Uid: in.UserId, Pid: in.ProductId})
if err != nil {
return nil, err
}
if err := l.svcCtx.KafkaPusher.Push(string(kd)); err != nil {
return nil, err
}
seckill-rmq消费seckill-rpc生产的数据进行下单操作,我们新建seckill-rmq服务,结构如下:
tree ./rmq ./rmq ├── etc │ └── seckill.yaml ├── internal │ ├── config │ │ └── config.go │ └── service │ └── service.go └── seckill.go 4 directories, 4 files
依然是使用kq初始化启动服务,这里我们需要注册一个ConsumeHand方法,该方法用以消费kafka数据
srv := service.NewService(c)
queue := kq.MustNewQueue(c.Kafka, kq.WithHandle(srv.Consume))
defer queue.Stop()
fmt.Println("seckill started!!!")
queue.Start()
在Consume方法中,消费到数据后先反序列化,然后调用product-rpc查看当前商品的库存,如果库存足够的话我们认为可以下单,调用order-rpc进行创建订单操作,最后再更新库存
func (s *Service) Consume(_ string, value string) error {
logx.Infof("Consume value: %s\n", value)
var data KafkaData
if err := json.Unmarshal([]byte(value), &data); err != nil {
return err
}
p, err := s.ProductRPC.Product(context.Background(), &product.ProductItemRequest{ProductId: data.Pid})
if err != nil {
return err
}
if p.Stock <= 0 {
return nil
}
_, err = s.OrderRPC.CreateOrder(context.Background(), &order.CreateOrderRequest{Uid: data.Uid, Pid: data.Pid})
if err != nil {
logx.Errorf("CreateOrder uid: %d pid: %d error: %v", data.Uid, data.Pid, err)
return err
}
_, err = s.ProductRPC.UpdateProductStock(context.Background(), &product.UpdateProductStockRequest{ProductId: data.Pid, Num: 1})
if err != nil {
logx.Errorf("UpdateProductStock uid: %d pid: %d error: %v", data.Uid, data.Pid, err)
return err
}
// TODO notify user of successful order placement
return nil
}
在创建订单过程中涉及到两张表orders和orderitem,所以我们要使用本地事务进行插入,代码如下:
func (m *customOrdersModel) CreateOrder(ctx context.Context, oid string, uid, pid int64) error {
_, err := m.ExecCtx(ctx, func(ctx context.Context, conn sqlx.SqlConn) (sql.Result, error) {
err := conn.TransactCtx(ctx, func(ctx context.Context, session sqlx.Session) error {
_, err := session.ExecCtx(ctx, "INSERT INTO orders(id, userid) VALUES(?,?)", oid, uid)
if err != nil {
return err
}
_, err = session.ExecCtx(ctx, "INSERT INTO orderitem(orderid, userid, proid) VALUES(?,?,?)", "", uid, pid)
return err
})
return nil, err
})
return err
}
订单号生成逻辑如下,这里使用时间加上自增数进行订单生成
var num int64
func genOrderID(t time.Time) string {
s := t.Format("20060102150405")
m := t.UnixNano()/1e6 - t.UnixNano()/1e9*1e3
ms := sup(m, 3)
p := os.Getpid() % 1000
ps := sup(int64(p), 3)
i := atomic.AddInt64(&num, 1)
r := i % 10000
rs := sup(r, 4)
n := fmt.Sprintf("%s%s%s%s", s, ms, ps, rs)
return n
}
func sup(i int64, n int) string {
m := fmt.Sprintf("%d", i)
for len(m) < n {
m = fmt.Sprintf("0%s", m)
}
return m
}
最后分别启动product-rpc、order-rpc、seckill-rpc和seckill-rmq服务还有zookeeper、kafka、mysql和redis,启动后我们调用seckill-rpc进行秒杀下单
grpcurl -plaintext -d '{"user_id": 111, "product_id": 10}' 127.0.0.1:9889 seckill.Seckill.SeckillOrder
在seckill-rmq中打印了消费记录,输出如下
{"@timestamp":"2022-06-26T10:11:42.997+08:00","caller":"service/service.go:35","content":"Consume value: {\"uid\":111,\"pid\":10}\n","level":"info"}
这个时候查看orders表中已经创建了订单,同时商品库存减一

结束语
本质上秒杀是一个高并发读和高并发写的场景,上面我们介绍了秒杀的注意事项以及优化点,我们这个秒杀场景相对来说比较简单,但其实也没有一个通用的秒杀的框架,我们需要根据实际的业务场景进行优化,不同量级的请求优化的手段也不尽相同。
这里我们只展示了服务端的相关优化,但对于秒杀场景来说整个请求链路都是需要优化的,比如对于静态数据我们可以使用CDN做加速,为了防止流量洪峰我们可以在前端设置答题功能等等。
代码仓库: https://github.com/zhoushuguang/lebron
项目地址 https://github.com/zeromicro/go-zero
以上就是go zero微服务实战处理每秒上万次的下单请求的详细内容,更多关于go zero每秒上万次请求处理的资料请关注我们其它相关文章!
相关推荐
-

go zero微服务实战系服务拆分
目录 微服务概述 服务划分 BFF层 工程结构 代码初始化 结束语 微服务概述 微服务架构是一种架构风格,它将一个大的系统构建为多个微服务的集合,这些微服务是围绕业务功能构建的,服务关注单一的业务功能,这些服务具有以下特点: 高度可维护和可测试 松散的耦合 可独立部署 围绕业务功能进行构建 由不同的小团队进行维护 微服务架构能够快速.频繁.可靠地交付大型.复杂的应用程序,通过业务拆分实现服务组件化,使用组件进行组合从而快速开发系统. 服务划分 我们首先进行微服务的划分,在实际的项目开发中,我们通
-
利用go-zero在Go中快速实现JWT认证的步骤详解
关于JWT是什么,大家可以看看官网,一句话介绍下:是可以实现服务器无状态的鉴权认证方案,也是目前最流行的跨域认证解决方案. 要实现JWT认证,我们需要分成如下两个步骤 客户端获取JWT token. 服务器对客户端带来的JWT token认证. 1. 客户端获取JWT Token 我们定义一个协议供客户端调用获取JWT token,我们新建一个目录jwt然后在目录中执行 goctl api -o jwt.api,将生成的jwt.api改成如下: type JwtTokenRequest stru
-
gorm整合进go-zero的实现方法
go-zero提供的代码生成器里面,没有提供orm框架操作,但是提供了遍历的缓存操作.但是gorm框架的话,没有比较好的缓存插件,虽然有一个gcache,但不支持gorm2.0版本. 所以我打算把这两个结合起来.在gorm官方文档中提到了一个接口,可以获取到生成的sql语句. 所以可以利用gorm当作一个sql语句的生成器,把生成后的sql语句放到go-zero生成的模板中去执行. gorm中的sql生成器 stmt := DB.Session(&Session{DryRun: true}).F
-
如何用go-zero 实现中台系统
最近发现golang社区里出了一个新星的微服务框架,来自好未来,光看这个名字,就很有奔头,之前,也只是玩过go-micro,其实真正的还没有在项目中运用过,只是觉得 微服务,grpc 这些很高大尚,还没有在项目中,真正的玩过,我看了一下官方提供的工具真的很好用,只需要定义好,舒适文件jia结构 都生成了,只需要关心业务, 加上最近 有个投票的活动,加上最近这几年中台也比较火,所以决定玩一下, 先聊聊中台架构思路吧,look 先看架 中台的概念大概就是把一个一个的app 统一起来,反正我是这样理解
-
go-zero 如何应对海量定时/延迟任务
一个系统中存在着大量的调度任务,同时调度任务存在时间的滞后性,而大量的调度任务如果每一个都使用自己的调度器来管理任务的生命周期的话,浪费cpu的资源而且很低效. 本文来介绍 go-zero 中 延迟操作,它可能让开发者调度多个任务时,只需关注具体的业务执行函数和执行时间「立即或者延迟」.而 延迟操作,通常可以采用两个方案: Timer:定时器维护一个优先队列,到时间点执行,然后把需要执行的 task 存储在 map 中collection 中的 timingWheel ,维护一个存放任务组的数组
-
如何使用go-zero开发线上项目
前言 说在最前面,我是一个外表谦让,内心狂热,外表斯文,内心贪玩的一个普通人.我的职业是程序员,是一个golang语言爱好者,一半是因为golang好用,一半是因为其他语言学不好.我是从phper转为gopher的,写php的时候我认识了互联网软件,写go的时候感觉自己终于在编程. 初见golang 我大学专业是软件.第一门编程语言是C++,知道了指针,知道了加减乘除,知道了编程去控制软硬件.后来选修了java,被ssh框架戏耍了一个暑假.再后来进入了一个社团技术部,再被html/css/j
-
go zero微服务实战处理每秒上万次的下单请求
目录 引言 处理热点数据 优化 限制 隔离 流量削峰 如何保证消息只被消费一次 代码实现 结束语 引言 在前几篇的文章中,我们花了很大的篇幅介绍如何利用缓存优化系统的读性能,究其原因在于我们的产品大多是一个读多写少的场景,尤其是在产品的初期,可能多数的用户只是过来查看商品,真正下单的用户非常少. 但随着业务的发展,我们就会遇到一些高并发写请求的场景,秒杀抢购就是最典型的高并发写场景.在秒杀抢购开始后用户就会疯狂的刷新页面让自己尽早的看到商品,所以秒杀场景同时也是高并发读场景.那么应对高并发读写场
-
go zero微服务实战性能优化极致秒杀
目录 引言 批量数据聚合 降低消息的消费延迟 怎么保证不会超卖 结束语 引言 上一篇文章中引入了消息队列对秒杀流量做削峰的处理,我们使用的是Kafka,看起来似乎工作的不错,但其实还是有很多隐患存在,如果这些隐患不优化处理掉,那么秒杀抢购活动开始后可能会出现消息堆积.消费延迟.数据不一致.甚至服务崩溃等问题,那么后果可想而知.本篇文章我们就一起来把这些隐患解决掉. 批量数据聚合 在SeckillOrder这个方法中,每来一次秒杀抢购请求都往往Kafka中发送一条消息.假如这个时候有一千万的用户同
-
解析docker妙用SpringBoot构建微服务实战记录
它是啥? Spring Boot 是 Spring 开源组织的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手. 为啥用它? 五大优点: 1.起步依赖 官方为我们整合了大量的起步依赖,简化了我们搭建项目的工作,同时,起步依赖提供了可靠的依赖管理,降低了项目引入问题版本和依赖冲突的风险. 2. 自动配置 开启组件扫描和自动配置. 通过exclude参数关闭特定 的自动配置. 3. 应用监控 Spring Bo
-
SpringSecurity微服务实战之公共模块详解
目录 前言 模块结构 前言 在项目中安全框架是必不可少的,在微服务架构中更是尤为重要,我们项目中将安全模块单独抽离了一个公共模块出来,因为在我的项目架构中 需要用到的SpringSecurity 至少有三个地方 boss服务 admin服务 user服务(saas)模式的一个微服务架构 模块结构 主要分为 base服务(提供数据,可以部署多份进行负载均衡) boss模块 admin模块 gateway模块 以及公共模块其中就包含我们今天的主角 安全模块. 我们在TokenLoginFilter中
-
Java微服务实战项目尚融宝接口创建详解
目录 需求 一.创建父工程srb 二.创建模块guigu-common 1.创建Maven模块 2.配置pom 三.创建模块service-base 1.创建Maven模块 2.配置pom 四.创建模块service-core 1.创建Maven模块 2.配置pom 五.代码生成器 1.创建数据库 2.创建代码生成器 六.启动应用程序 1.创建application.yml 2.创建SpringBoot配置文件 3.创建SpringBoot启动类 需求 积分等级CRUD列表和表单 一.创建父工程
-
idea2020中复制一个微服务实例的方法
推荐阅读: 最新idea2020注册码永久激活(激活到2100年) IDEA2020.2.2激活与IntelliJ IDEA2020注册码及IntelliJ全家桶激活码的详细教程(有你足矣) 由于在开发过程中,如果需要调用多个服务提供者,就只能一个一个创建,对于两个功能相同的服务提供者可以使用创建其"分身",达到快速测试的目的. 首先,创建好一个服务提供者微服务(ServerProviderApp 端口:8000) 开始创建"分身". 1. 在idea2020中 打
-
SpringCloud让微服务实现指定程序调用
我们在做微服务时,有时候需要将微服务做一些限制,比如只能我们自己的服务调用,不能通过浏览器直接调用等. 我们可以使用spring cloud sleuth,在应用调用微服务时通过Tracer产生一个traceId,并通过request设置到header里面, 然后sleuth会将该traceId在整个链路传递,我们在微服务中定义一个拦截器,取到header里面的traceId并和链路中的traceId比较, 如果相等,则表明是我们自己的应用调用,拦截器通过,否则这次请求被拦截 代码详见githu
-
SSH框架网上商城项目第24战之Struts2中处理多个Model请求的方法
1. 问题的提出 Struts2中如果实现了ModelDriven<model>接口就可以将传来的参数注入到model中了,就可以在Action中使用该model,但是如果现在有两个model都需要在同一个Action中使用该咋整呢?比如上一节我们完成了在线支付功能,但是支付完成了还没结束,我们需要接收从第三方那边反馈回来的信息,比如成功支付后,我们需要给付款方发送邮件和短信等.所以我们还需要在payAction中获取从第三方传过来的参数,由于从第三方传过来的参数与我们传过去的参数是不同的,所
-
Spring Cloud 专题之Sleuth 服务跟踪实现方法
目录 准备工作 实现跟踪 抽样收集 整合Zipkin 1.下载Zipkin 2.引入依赖配置 3.测试与分析 持久化到mysql 1.创建zipkin数据库 2.启动zipkin 3.测试与分析 在一个微服务架构中,系统的规模往往会比较大,各微服务之间的调用关系也错综复杂.通常一个有客户端发起的请求在后端系统中会经过多个不同的微服务调用阿里协同产生最后的请求结果.在复杂的微服务架构中,几乎每一个前端请求都会形成一条复杂的分布式的服务调用链路,在每条链路中任何一个依赖服务出现延迟过高或错误的时候都