c++ Bellman-Ford算法的具体实现
Bellman-Ford算法用于解决有边数限制的最短路问题,且可以应对有负边权的图
其时间复杂度为O(nm),效率较低
代码实现:
#include<iostream>
#include<cstring>
#include<algorithm>
#define inf 0x3f3f3f3f
using namespace std;
const int N=1e4+10;
const int M=510;
int m,n,k,dis[M],backup[M];
//m条边,n个点,在1号点到n号点之间找到一条经过小于等于k条边的通路
//dis:各点到源点的距离,backup:备份
struct Node
{
int x,y,v;
}edge[N];//可以直接用结构体存边
int Bellman_Ford()
{
dis[1]=0;
memset(dis,0x3f,sizeof dis);
for(int i=1;i<=k;i++)
{
memcpy(backup,dis,sizeof dis);
for(int j=1;j<=m;j++)
{
Node t=edge[j];
dis[t.y]=min(dis[t.y],backup[t.x]+t.v);
}
}
if(dis[n]>inf/2) return -1;
return dis[n];
}
int main()
{
cin>>n>>m>>k;
for(int i=1;i<=m;i++)
{
int a,b,c;
cin>>a>>b>>c;
edge[i]={a,b,c};
}
int ans=Bellman_Ford();
if(ans==-1) cout<<"impossible";
else cout<<ans;
return 0;
}
对代码中的重难点的解释:
1.backup备份数组存在的意义:每一次“迭代”后,实现对dis数组的当前状态进行保存
这里详细解释一下“迭代”的含义:此处的迭代即为从源点开始,对所到达的点的出边进行松弛
举个例子:有一个如下的图,1号点为源点
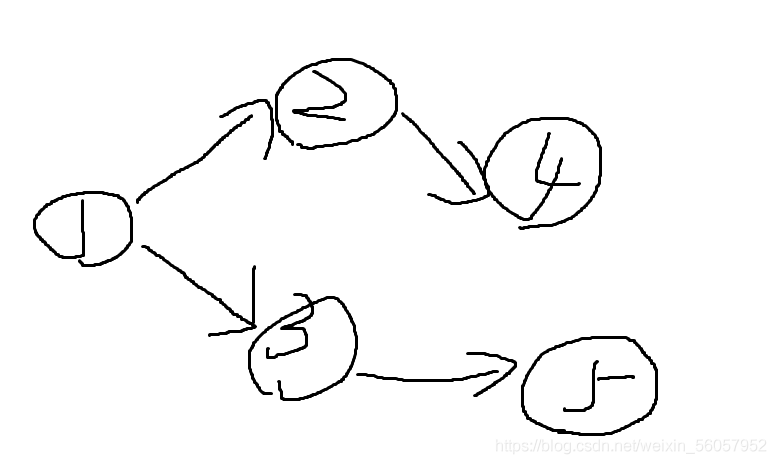
第一次迭代
找到2,3号点到源点的最短距离
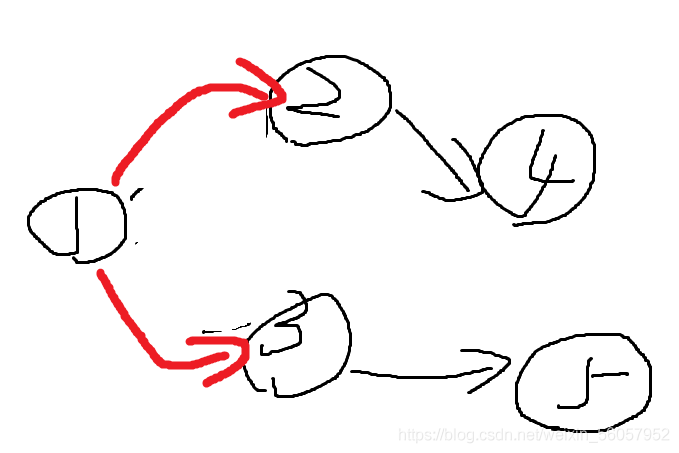
第二次迭代
找到4,5号点到源点的最短距离
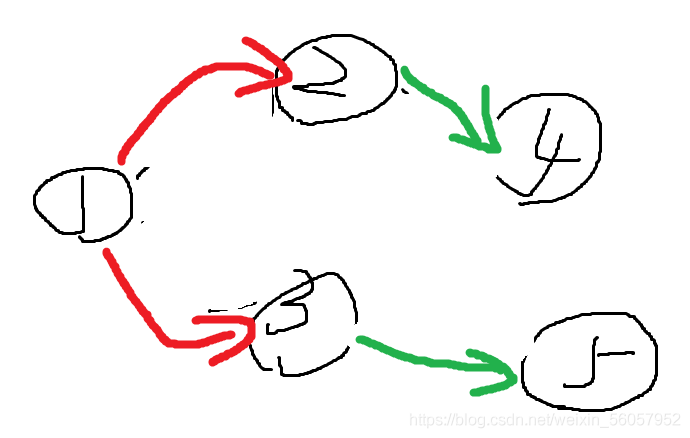
第三次迭代
由于所有边都已被遍历,没有边能够被松弛,迭代结束
由刚才的过程可知,每一次迭代后要对dis数组进行备份,若一直使用dis数组进行运算,程序则会失去迭代的控制(在代码中迭代体现为Bellman-Ford函数中的外重循环,题目要求最多经过k条边,实际上就是最多有k次迭代)
2.代码的最后的判断
为什么是if(dis[n]>inf/2),而不是if(dis[n]==inf)呢?
原因是Bellman-Ford算法可能处理含负权边的图,dis[n]可能会出现+∞-2这样的数值,所以进行大小比较判断时条件只需要让dis[n]大于一个同数量级的数(此处为inf/2)即可
到此这篇关于c++ Bellman-Ford算法的具体实现的文章就介绍到这了,更多相关c++ Bellman-Ford内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C++计算任意权值的单源最短路径(Bellman-Ford)
本文实例为大家分享了C++计算任意权值单源最短路径的具体代码,供大家参考,具体内容如下 一.有Dijkstra算法求最短路径了,为什么还要用Bellman-Ford算法 Dijkstra算法不适合用于带有负权值的有向图. 如下图: 用Dijkstra算法求顶点0到各个顶点的最短路径: (1)首先,把顶点0添加到已访问顶点集合S中,选取权值最小的邻边<0, 2>,权值为5 记录顶点2的最短路径为:dist[2]=5, path[2]=0,把顶点2添加到集合S中. 顶点2,没有邻边(从顶点2出发,
-
路由选择协议 Routing Protocols
路由选择协议 Routing Protocols 当两台非直接连接的计算机需要经过几个网络通信时,通常就需要路由器.路由器提供一种方法来开辟通过一个网状联结的路径.这种网状网络提供了冗余路径以调整通信负载或倒行链路,通常有一条路径由于费用.速度或避开拥挤等理由优选于其它路径.路由选择协议的任务是,为路由器提供他们建立通过网状网络最佳路径所需要的相互共享的路由信息. 当一个计算机发送一个分组时,在网络上网络协议栈的每一层都附加一些信息给它.在接收方的对等层协议可以读出这些信息.这些信息类似于通信
-
路由选择协议 Routing Protocols
路由选择协议 Routing Protocols 当两台非直接连接的计算机需要经过几个网络通信时,通常就需要路由器.路由器提供一种方法来开辟通过一个网状联结的路径.这种网状网络提供了冗余路径以调整通信负载或倒行链路,通常有一条路径由于费用.速度或避开拥挤等理由优选于其它路径.路由选择协议的任务是,为路由器提供他们建立通过网状网络最佳路径所需要的相互共享的路由信息. 当一个计算机发送一个分组时,在网络上网络协议栈的每一层都附加一些信息给它.在接收方的对等层协议可以读出这些信息.这些信息类似于通信
-

Java编程实现轨迹压缩之Douglas-Peucker算法详细代码
第一部分 问题描述 1.1 具体任务 本次作业任务是轨迹压缩,给定一个GPS数据记录文件,每条记录包含经度和维度两个坐标字段,所有记录的经纬度坐标构成一条轨迹,要求采用合适的压缩算法,使得压缩后轨迹的距离误差小于30m. 1.2 程序输入 本程序输入是一个GPS数据记录文件. 1.3 数据输出 输出形式是文件,包括三部分,压缩后点的ID序列及坐标.点的个数.平均距离误差.压缩率 第二部分 问题解答 根据问题描述,我们对问题进行求解,问题求解分为以下几步: 2.1 数据预处理 本次程序输入为GPS
-
php实现的生成迷宫与迷宫寻址算法完整实例
本文实例讲述了php实现的生成迷宫与迷宫寻址算法.分享给大家供大家参考,具体如下: 较之前的终于有所改善.生成迷宫的算法和寻址算法其实是一样.只是一个用了遍历一个用了递归.参考了网上的Mike Gold的算法. <?php header('Content-Type: text/html; charset=utf-8'); error_reporting(E_ALL); //n宫格迷宫 define('M', 39);//宫数 define("S", 20);//迷宫格大小 $_p
-
荐书|程序员书单必不可少系列之算法篇
前言 又到了给大家"荐书"的时候了,如果计算机系只开三门课,那么这三门课就一定是:离散数学,数据结构与算法,编译原理.如果只开一门课,那剩下的就一定是:数据结构与算法.最近参加了很多线下的会议,发现一个点,就是不管什么技术主题的大会,人们都会找算法的书,小编再次深深地体会到算法是那么地必不可少,现在小编就来盘点一下算法书推荐给大家. 一.<程序员的数学>第3弹--线性代数 作者:[日] 平岡和幸,[日] 堀玄 译者:卢晓南 豆瓣评分:8.7分 机器学习.数据挖掘.模式识别必
-
Go语言排序算法之插入排序与生成随机数详解
前言 排序,对于每种编程语言都是要面对的.这里跟大家一起分享golang实现一些排序算法,并且说明如何生成随机数.下面话不多说了,来一起看看详细的介绍吧. 经典排序算法 算法的学习非常重要,是检验一个程序员水平的重要标准.学习算法不能死记硬背,需要理解其中的思想,这样才能灵活应用到实际的开发中. 七大经典排序算法 插入排序 选择排序 冒泡排序 希尔排序 归并排序 堆排序 快速排序 插入排序 先考虑一个问题:对于长度为n的数组,前n-1位都是递增有序的,如何排序? 1.从第1位至第n-1位遍历数组
-
JavaScript实现树的遍历算法示例【广度优先与深度优先】
本文实例讲述了JavaScript实现树的遍历算法.分享给大家供大家参考,具体如下: <script type="text/javascript"> var t = [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19]; //下面这段深度优先搜索方法出自Aimingoo的[JavaScript语言精髓与编程实践] var deepView = function(aTree,iNode) { (iNode in aTree)
-
Spark实现K-Means算法代码示例
K-Means算法是一种基于距离的聚类算法,采用迭代的方法,计算出K个聚类中心,把若干个点聚成K类. MLlib实现K-Means算法的原理是,运行多个K-Means算法,每个称为run,返回最好的那个聚类的类簇中心.初始的类簇中心,可以是随机的,也可以是KMean||得来的,迭代达到一定的次数,或者所有run都收敛时,算法就结束. 用Spark实现K-Means算法,首先修改pom文件,引入机器学习MLlib包: <dependency> <groupId>org.apache.
-
Perl实现高水线算法(解决多值比较问题方法)
"高水线"算法:大水过后,最后一波浪消退时,高水线会标示出所见过的最高水位. 下面看下"高水线"算法在Perl中的运用. #! /usr/bin/perl; use utf8; sub max { my($max_so_far) = shift @_; #数组中第一个值,暂时当成最大值. foreach(@_){ #遍历数组@_ if($_>$max_so_far){ #看其它元素是否有比$max_so_far大的值. $max_so_far = $_;} #
-
Python中使用hashlib模块处理算法的教程
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 什么是摘要算法呢?摘要算法又称哈希算法.散列算法.它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示). 举个例子,你写了一篇文章,内容是一个字符串'how to use python hashlib - by Michael',并附上这篇文章的摘要是'2d73d4f15c0db7f5ecb321b6a65e5d6d'.如果有人篡改了你的文章,并发表为'how to use pytho