Python实现8种常用抽样方法
今天来和大家聊聊抽样的几种常用方法,以及在Python中是如何实现的。
抽样是统计学、机器学习中非常重要,也是经常用到的方法,因为大多时候使用全量数据是不现实的,或者根本无法取到。所以我们需要抽样,比如在推断性统计中,我们会经常通过采样的样本数据来推断估计总体的样本。
上面所说的都是以概率为基础的,实际上还有一类非概率的抽样方法,因此总体上归纳为两大种类:
概率抽样:根据概率理论选择样本,每个样本有相同的概率被选中。
非概率抽样:根据非随机的标准选择样本,并不是每个样本都有机会被选中。
概率抽样技术
1.随机抽样(Random Sampling)
这也是最简单暴力的一种抽样了,就是直接随机抽取,不考虑任何因素,完全看概率。并且在随机抽样下,总体中的每条样本被选中的概率相等。
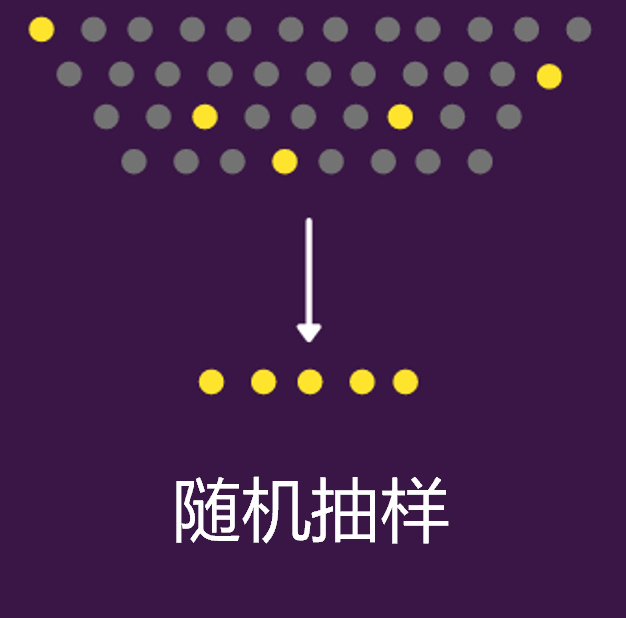
比如,现有10000条样本,且各自有序号对应的,假如抽样数量为1000,那我就直接从1-10000的数字中随机抽取1000个,被选中序号所对应的样本就被选出来了。
在Python中,我们可以用random函数随机生成数字。下面就是从100个人中随机选出5个。
import random population = 100 data = range(population) print(random.sample(data,5)) > 4, 19, 82, 45, 41
2.分层抽样(Stratified Sampling)
分层抽样其实也是随机抽取,不过要加上一个前提条件了。在分层抽样下,会根据一些共同属性将带抽样样本分组,然后从这些分组中单独再随机抽样。

因此,可以说分层抽样是更精细化的随机抽样,它要保持与总体群体中相同的比例。 比如,机器学习分类标签中的类标签0和1,比例为3:7,为保持原有比例,那就可以分层抽样,按照每个分组单独随机抽样。
Python中我们通过train_test_split设置stratify参数即可完成分层操作。
from sklearn.model_selection import train_test_split stratified_sample, _ = train_test_split(population, test_size=0.9, stratify=population[['label']]) print (stratified_sample)
3.聚类抽样(Cluster Sampling)
聚类抽样,也叫整群抽样。它的意思是,先将整个总体划分为多个子群体,这些子群体中的每一个都具有与总体相似的特征。也就是说它不对个体进行抽样,而是随机选择整个子群体。

用Python可以先给聚类的群体分配聚类ID,然后随机抽取两个子群体,再找到相对应的样本值即可,如下。
import numpy as np clusters=5 pop_size = 100 sample_clusters=2 # 间隔为 20, 从 1 到 5 依次分配集群100个样本的聚类 ID,这一步已经假设聚类完成 cluster_ids = np.repeat([range(1,clusters+1)], pop_size/clusters) # 随机选出两个聚类的 ID cluster_to_select = random.sample(set(cluster_ids), sample_clusters) # 提取聚类 ID 对应的样本 indexes = [i for i, x in enumerate(cluster_ids) if x in cluster_to_select] # 提取样本序号对应的样本值 cluster_associated_elements = [el for idx, el in enumerate(range(1, 101)) if idx in indexes] print (cluster_associated_elements)
4.系统抽样(Systematic Sampling)
系统抽样是以预定的规则间隔(基本上是固定的和周期性的间隔)从总体中抽样。比如,每 9 个元素抽取一下。一般来说,这种抽样方法往往比普通随机抽样方法更有效。
下图是按顺序对每 9 个元素进行一次采样,然后重复下去。

用Python实现的话可以直接在循环体中设置step即可。
population = 100 step = 5 sample = [element for element in range(1, population, step)] print (sample)
5.多级采样(Multistage sampling)
在多阶段采样下,我们将多个采样方法一个接一个地连接在一起。比如,在第一阶段,可以使用聚类抽样从总体中选择集群,然后第二阶段再进行随机抽样,从每个集群中选择元素以形成最终集合。

Python代码复用了上面聚类抽样,只是在最后一步再进行随机抽样即可。
import numpy as np clusters=5 pop_size = 100 sample_clusters=2 sample_size=5 # 间隔为 20, 从 1 到 5 依次分配集群100个样本的聚类 ID,这一步已经假设聚类完成 cluster_ids = np.repeat([range(1,clusters+1)], pop_size/clusters) # 随机选出两个聚类的 ID cluster_to_select = random.sample(set(cluster_ids), sample_clusters) # 提取聚类 ID 对应的样本 indexes = [i for i, x in enumerate(cluster_ids) if x in cluster_to_select] # 提取样本序号对应的样本值 cluster_associated_elements = [el for idx, el in enumerate(range(1, 101)) if idx in indexes] # 再从聚类样本里随机抽取样本 print (random.sample(cluster_associated_elements, sample_size))
非概率抽样技术
非概率抽样,毫无疑问就是不考虑概率的方式了,很多情况下是有条件的选择。因此,对于无随机性我们是无法通过统计概率和编程来实现的。这里也介绍3种方法。
1.简单采样(convenience sampling)
简单采样,其实就是研究人员只选择最容易参与和最有机会参与研究的个体。比如下面的图中,蓝点是研究人员,橙色点则是蓝色点附近最容易接近的人群。

2.自愿抽样(Voluntary Sampling)
自愿抽样下,感兴趣的人通常通过填写某种调查表格形式自行参与的。所以,这种情况中,调查的研究人员是没有权利选择任何个体的,全凭群体的自愿报名。比如下图中蓝点是研究人员,橙色的是自愿同意参与研究的个体。

3.雪球抽样(Snowball Sampling)
雪球抽样是说,最终集合是通过其他参与者选择的,即研究人员要求其他已知联系人寻找愿意参与研究的人。比如下图中蓝点是研究人员,橙色的是已知联系人,黄色是是橙色点周围的其它联系人。

总结
以上就是8种常用抽样方法,平时工作中比较常用的还是概率类抽样方法,因为没有随机性我们是无法通过统计学和编程完成自动化操作的。
比如在信贷的风控样本设计时,就需要从样本窗口通过概率进行抽样。因为采样的质量基本就决定了你模型的上限了,所以在抽样时会考虑很多问题,如样本数量、是否有显著性、样本穿越等等。在这时,一个良好的抽样方法是至关重要的。
以上就是本次分享,原创不易,欢迎点赞、留言、分享,支持我继续写下去。
参考:
[2] https://towardsdatascience.com/8-types-of-sampling-techniques-b21adcdd2124
到此这篇关于Python实现8种常用抽样方法的文章就介绍到这了,更多相关Python 抽样方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python Pandas如何对数据集随机抽样
摘要:有时候我们只需要数据集中的一部分,并不需要全部的数据.这个时候我们就要对数据集进行随机的抽样.pandas中自带有抽样的方法. 应用场景: 我有10W行数据,每一行都11列的属性. 现在,我们只需要随机抽取其中的2W行. 实现方法很简单: 利用Pandas库中的sample. DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None) n是要抽取的行数.(例如n
-
python使用pandas抽样训练数据中某个类别实例
废话真的一句也不想多说,直接看代码吧! # -*- coding: utf-8 -*- import numpy from sklearn import metrics from sklearn.svm import LinearSVC from sklearn.naive_bayes import MultinomialNB from sklearn import linear_model from sklearn.datasets import load_iris from sklearn.
-
python数据预处理 :数据抽样解析
何为数据抽样: 抽样是数据处理的一种基本方法,常常伴随着计算资源不足.获取全部数据困难.时效性要求等情况使用. 抽样方法: 一般有四种方法: 随机抽样 直接从整体数据中等概率抽取n个样本.这种方法优势是,简单.好操作.适用于分布均匀的场景:缺点是总体大时无法一一编号 系统抽样 又称机械.等距抽样,将总体中个体按顺序进行编号,然后计算出间隔,再按照抽样间隔抽取个体.优势,易于理解.简便易行.缺点是,如有明显分布规律时容易产生偏差. 群体抽样 总体分群,在随机抽取几个小群代表总体.优点是简单易行.便
-

基于python进行抽样分布描述及实践详解
本次选取泰坦尼克号的数据,利用python进行抽样分布描述及实践. 备注:数据集的原始数据是泰坦尼克号的数据,本次截取了其中的一部分数据进行学习.Age:年龄,指登船者的年龄.Fare:价格,指船票价格.Embark:登船的港口. 1.按照港口分类,使用python求出各类港口数据 年龄.车票价格的统计量(均值.方差.标准差.变异系数等). import pandas as pd df = pd.read_excel('/Users/Downloads/data.xlsx',usecols =
-
python实现的分层随机抽样案例
昨天写了一段用来做分层随机抽样的代码,很粗糙,不过用公司的2万名导购名单试了一下,结果感人,我觉得此刻的我已经要上天了,哈哈哈哈哈哈 代码如下: #分层随机抽样 stratified sampling import xlrd, xlwt, time, random xl = xlrd.open_workbook(r'C:\Users\Administrator\Desktop\分层抽样.xlsx') xl_sht1 = xl.sheets()[0] xl_sht1_nrows = xl_sht1
-
Python实现8种常用抽样方法
今天来和大家聊聊抽样的几种常用方法,以及在Python中是如何实现的. 抽样是统计学.机器学习中非常重要,也是经常用到的方法,因为大多时候使用全量数据是不现实的,或者根本无法取到.所以我们需要抽样,比如在推断性统计中,我们会经常通过采样的样本数据来推断估计总体的样本. 上面所说的都是以概率为基础的,实际上还有一类非概率的抽样方法,因此总体上归纳为两大种类: 概率抽样:根据概率理论选择样本,每个样本有相同的概率被选中. 非概率抽样:根据非随机的标准选择样本,并不是每个样本都有机会被选中. 概率抽样
-
用python介绍4种常用的单链表翻转的方法小结
如何把一个单链表进行反转? 方法1:将单链表储存为数组,然后按照数组的索引逆序进行反转. 方法2:使用3个指针遍历单链表,逐个链接点进行反转. 方法3:从第2个节点到第N个节点,依次逐节点插入到第1个节点(head节点)之后,最后将第一个节点挪到新表的表尾. 方法4: 递归(相信我们都熟悉的一点是,对于树的大部分问题,基本可以考虑用递归来解决.但是我们不太熟悉的一点是,对于单链表的一些问题,也可以使用递归.可以认为单链表是一颗永远只有左(右)子树的树,因此可以考虑用递归来解决.或者说,因为单链表
-
python面向对象基础之常用魔术方法
一.类和对象 通俗理解:类就是模板,对象就是通过模板创造出来的物体 类(Class)由3个部分构成: 类的名称: 类名 类的属性: 一组数据 类的方法: 允许对进行操作的方法 (行为) 二.魔法方法 在python中,有一些内置好的特定的方法,方法名是"__xxx__",在进行特定的操作时会自动被调用,这些方法称之为魔法方法.下面介绍几种常见的魔法方法. 1.__init__方法 :初始化一个 类 ,在创建实例对象为其 赋值 时使用. 2.__str__方法:在将对象转换成字符串 st
-
python迭代器模块itertools常用的方法
目录 前言 1.无限迭代器 2.有限迭代器 3.组合迭代器 前言 itertools是python中内置的一种高效的生成各种迭代器或者是类的模块,这些函数的返回值为一个迭代器,经常被用在for循环中,当然,也可直接使用next()方法取值,今天就来说说itertools中的常用方法. itertools按照迭代器的功能可分为三类: 无限迭代器: 生成一个无限序列,比如自然数序列 1, 2, 3, 4, … 有限迭代器: 接收一个或多个序列(sequence)作为参数,进行组合.分组和过滤等: 组
-
Python 中几种字符串格式化方法及其比较
Python 中几种字符串格式化方法及其比较 起步 在 Python 中,提供了很多种字符串格式化的方式,分别是 %-formatting.str.format 和 f-string .本文将比较这几种格式化方法. %- 格式化 这种格式化方式来自于 C 语言风格的 sprintf 形式: name = "weapon" "Hello, %s." % name C 语言的给实话风格深入人心,通过 % 进行占位. 为什么 %-formatting不好 不好的地方在于,
-
详解Python图像处理库Pillow常用使用方法
PIL(Python Image Library)是python的第三方图像处理库,但是由于其强大的功能与众多的使用人数,几乎已经被认为是python官方图像处理库了. 其官方主页为:PIL. PIL历史悠久,原来是只支持python2.x的版本的,后来出现了移植到python3的库pillow,pillow号称是friendly fork for PIL,其功能和PIL差不多,但是支持python3. PIL(Python Imaging Library)是Python一个强大方便的图像处理库
-
C#窗体间通讯的几种常用处理方法总结
在进行C#应用程序开发的过程中,经常需要多窗体之间进行数据通信,本文举几个例子,把几种常用的通信方式总结一下,窗体界面如下图所示: 主窗体Form1是一个ListBox,单击选中某列时,弹出窗体Form2,Form2中两个控件,一个是TextBox,显示选中的该列的文本,另一个是按钮,点击时将修改后的值回传,且在Form1中修改相应的列的文本,同时Form2关闭. 方法一:传值 最先想到的,Form2构造函数中接收一个string类型参数,即Form1中选中行的文本,将Form2的TextBox
-
js跨域请求数据的3种常用的方法
由于js同源策略的影响,当在某一域名下请求其他域名,或者同一域名,不同端口下的url时,就会变成不被允许的跨域请求. 那这个时候通常怎么解决呢,对此菜鸟光头我稍作了整理: 1.JavaScript 在原生js(没有jQuery和ajax支持)的情况下,通常客户端代码是这样的(我假设是在localhost:8080的端口下的http://localhost:8080/webs/i.mediapower.mobi/wutao/index.html页面的body标签下面加入以下代码): <scr
-
基于Python实现2种反转链表方法代码实例
题目: 反转一个单链表. 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL 进阶: 你可以迭代或递归地反转链表.你能否用两种方法解决这道题? 思路: 主要需要注意反转过程中不要丢了节点.可以使用两个指针,也可以使用三个指针. Python解法一: class Solution: def reverseList(self, head): cur, prev = head, None while
-
R语言中的五种常用统计分析方法
1.分组分析aggregation 根据分组字段,将分析对象划分为不同的部分,以进行对比分析各组之间差异性的一种分析方法. 常用统计指标: 计数 length 求和 sum 平均值 mean 标准差 var 方差 sd 分组统计函数 aggregate(分组表达式,data=需要分组的数据框,function=统计函数) 参数说明 formula:分组表达式,格式:统计列~分组列1+分组列2+... data=需要分组的数据框 function:统计函数 aggregate(name ~ cla