R语言向量下标和子集的使用
目录
- 1.正整数下标
- 2.负整数下标
- 3.空下标与零下标
- 4.下标超界
- 5.逻辑下标
- 6. which()、which.min()、which.max()函数
- 7. 元素名
- 8.用R向量下标作映射
- 9.集合运算
- 练习
1.正整数下标
首先定义一个x,然后对向量 x, 在后面加方括号和下标可以访问向量的元素和子集,如:
定义一个x:
x <- c(1, 4, 6.25) x
返回:

我们取出第二个元素:
x[2]
返回:

我们再修改第二个元素为 99 :
x[2] <- 99; x
返回:

我们再取下第 1、3 号元素 :
x[c(1,3)]
返回:

我们再修改第 1、3 号元素为 11,13 :
x[c(1,3)] <- c(11, 13); x
返回:

若是下标可重复,又会如何,如:
x[c(1,3,1)]
返回:

2.负整数下标
负下标表示扣除相应的元素后的子集,如
x <- c(1,4,6.25) x[-2]
-2 表示倒数第二个;返回:

再比如:
x[-c(1,3)]
返回:

负整数下标不能与正整数下标同时用来从某一向量中取子集,比如
x[c(1,-2)]
返回结果会报错:

3.空下标与零下标
x[] 表示取 x 的全部元素作为子集。这与 x 本身不同,比如
x <- c(1,4,6.25) x[]
返回:

然后,我们对x 内的值进行修改
x[] <- 999 x
返回:

再如,另一种对x内的值进行修改
x <- c(1,4,6.25) x <- 999 x
返回结果只有一个值:

可能有人会问是否有 x[0] ,那就让我们看看
x[0]
返回:

那说明,x[0] 是一种少见的做法,结果返回类型相同、长度为零的向量,如 numeric(0)。
相当于空集;且当 0 与正整数下标一起使用时会被 忽略。当 0 与负整数下标一起使用时也会被 忽略。
4.下标超界
设向量 x 长度为 n , 则使用正整数下标时下标应在 { 1 , 2 , . . . , n } 中取值。
x <- c(1,4,6.25) x[2]
返回:

如果使用大于 n 的下标,读取时返回缺失值,并不出错。
x[5]
返回:

给超出 n 的下标元素赋值,则向量自动变长,中间没有赋值的元素为缺失值。例如
x[5] <- 9 x
返回:
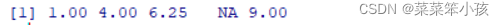
虽然 R 的语法对下标超界不视作错误,但是这样的做法往往来自不良的程序思路,而且对程序效率有影响,所以实际编程中应避免下标超界。
5.逻辑下标
下标可以是与向量等长的逻辑表达式,一般是关于本向量或者与本向量等长的其它向量的比较结果,如 定义x
x <- c(1,4,6.25)
取出 x 的大于 3 的元素组成的子集
x[x > 3]
返回:

逻辑下标除了用来对向量取子集,还经常用来对数据框取取子集,也用在向量化的运算中。例如,对如下示性函数

输入向量 x ,结果 y 需要也是一个向量,程序可以写成
f <- function(x){
y <- numeric(length(x))
y[x >= 0] <- 1
y[x < 0] <- 0 # 此语句多余
y }
事实上还有一种写法,向量化的逻辑选择有一个 ifelse() 函数,比如,对上面的示性函数,如果 x 是一个向量,输出 y 向量可以写成
y <- ifelse(x>=0, 1, 0)
要注意的是,如果逻辑下标中有缺失值,对应结果也是缺失值,如
x <- c(1, 4, 6.25, NA) x[x > 2]
返回:

所以,在用逻辑下标作子集选择时,一定要考虑到缺失值问题。 正确的做法是加上!is.na 前提,如
x[!is.na(x) & x > 2]
返回:

6. which()、which.min()、which.max() 函数
函数 which() 可以用来找到满足条件的下标,如
x <- c(3, 4, 3, 5, 7, 5, 9) which(x > 5)
返回:

seq(along=x) 会生成由 x 的下标组成的向量,如
seq(along=x)[x > 5]
返回:

用 which.min() 、which.max() 求最小值的下标和最大值的下标,不唯一时只取第一个。如
which.min(x) which.max(x)
返回:

7. 元素名
向量可以为每个元素命名。如
ages <- c(" 李明"=30, " 张聪"=25, " 刘颖"=28)
或
ages <- c(30, 25, 28)
names(ages) <- c(" 李明", " 张聪", " 刘颖")
或
ages <- setNames(c(30, 25, 28), c(" 李明", " 张聪", " 刘颖"))
这时可以用元素名或元素名向量作为向量的下标,如
ages[" 张聪"]
返回:

再如:
ages[c(" 李明", " 刘颖")]
返回:

再如,修改字符串数值:
ages[" 张聪"] <- 26
用字符串作为下标时,如果该字符串不在向量的元素名中,读取时返回缺失值结果,赋值时该向量会增加一个元素并以该字符串为元素名。 带有元素名的向量也可以是字符型或其它基本类型,如
sex <- c(" 李明"=" 男", " 张聪"=" 男", " 刘颖"=" 女")
除了给向量元素命名外,在矩阵和数据框中还可以给行、列命名,这会使得程序的扩展更为容易和安全。 R 允许仅给部分元素命名,这时其它元素名字为空字符串。不同元素的元素名一般应该是不同的,否则在使用元素作为下标时会发生误读,但是 R 语法允许存在重名。 用 unname(x) 返回去掉了元素名的 x 的副本,用 names(x) <- NULL 可以去掉 x 的元素名。
8.用 R 向量下标作映射
R 在使用整数作为向量下标时,允许使用重复下标,这样可以把数组 x 看成一个 1 : n 的整数到 x[1] , x[2] , . . . , x[n] 的一个映射表 , 其中 n 是 x 的长度。 比如,某商店有三种礼品,编号为 1,2,3 ,价格分别为 68, 88 和 168 。令
price.map <- c(68, 88, 168)
设某个收银员在一天内分别售出礼品编号为 3,2,1,1,2,2,3 ,可以用如下的映射方式获得售出的这些礼品对应的价格:
items <- c(3,2,1,1,2,2,3) y <- price.map[items] print(y)
返回:

R 向量可以用字符型向量作下标,字符型下标也允许重复,所以可以把带有元素名的 R 向量看成是元素名到元素值的映射表。 比如,设 sex 为 10 个学生的性别(男、女)
sex <- c(" 男", " 男", " 女", " 女", " 男", " 女", " 女", " 女", " 女", " 男")
希望把每个学生按照性别分别对应到蓝色和红色。首先建立一个 R 向量当作映射
sex.color <- c(' 男'='blue', ' 女'='red')
用 R 向量 sex.color 当作映射,可以获得每个学生对应的颜色
cols <- sex.color[sex]; print(cols)
返回:

这样的映射结果中带有不必要的元素名,用 unname() 函数可以去掉元素名,如
unname(cols)
返回:
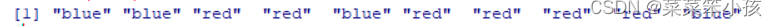
9.集合运算
可以把向量 x 看成一个集合,但是其中的元素允许有重复。用 unique(x) 可以获得 x 的所有不同值。如
unique(c(1, 5, 2, 5))
返回:
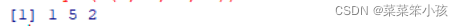
用 a %in% x 判断 a 的每个元素是否属于向量 x,如
5 %in% c(1,5,2)
返回:

c(5,6) %in% c(1,5,2)
返回

与 %in 运算符类似,函数 match(x, table) 对向量 x 的每个元素,从向量 table 中查找其首次出现位置并返回这些位置。没有匹配到的元素位置返回NA_integer_( 整数型缺失值) 。如
一个数值判断:
match(5, c(1,5,2))
返回:

若所匹配集合有重复元素,则返回为第一个元素的下标:
match(5, c(1,5,2,5))
返回:

若匹配两个元素的所属呢?
match(c(2,5), c(1,5,2,5))
返回:

若所匹配元素中,有集合中没有的呢?则返回空值,如
match(c(2,5,0), c(1,5,2,5))
返回:

用 intersect(x,y) 求交集,结果中不含重复元素,如
intersect(c(5, 7), c(1, 5, 2, 5))
返回:

用 union(x,y) 求并集,结果中不含重复元素,如
union(c(5, 7), c(1, 5, 2, 5))
返回:

用 setdiff(x,y) 求差集,即 x 的元素中不属于 y 的元素组成的集合,结果中不含重复元素,如
setdiff(c(5, 7), c(1, 5, 2, 5))
返回:

用 setequal(x,y) 判断两个集合是否相等,不受次序与重复元素的影响,如
setequal(c(1,5,2), c(2,5,1))

再如
setequal(c(1,5,2), c(2,5,1,5))
返回:

练习
设文件 class.csv 内容如下 :
name,sex,age,height,weight
Alice,F,13,56.5,84
Becka,F,13,65.3,98
Gail,F,14,64.3,90
Karen,F,12,56.3,77
Kathy,F,12,59.8,84.5
Mary,F,15,66.5,112
Sandy,F,11,51.3,50.5
Sharon,F,15,62.5,112.5
Tammy,F,14,62.8,102.5
Alfred,M,14,69,112.5
Duke,M,14,63.5,102.5
Guido,M,15,67,133
James,M,12,57.3,83
Jeffrey,M,13,62.5,84
John,M,12,59,99.5
Philip,M,16,72,150
Robert,M,12,64.8,128
Thomas,M,11,57.5,85
William,M,15,66.5,112
用如下程序可以把上述文件读入为 R 数据框 d.class, 并取出其中的 name 和
age 列到变量 name 和 age 中:
d.class <- read.csv ( 'class.csv' , header= TRUE , stringsAsFactors= FALSE )
name <- d.class[, 'name' ]
age <- d.class[, 'age' ]
(1) 求出 age 中第 3, 5, 7 号的值;
(2) 用变量 age, 求出达到 15 岁及以上的那些值;
(3) 用变量 name 和 age, 求出 Mary 与 James 的年龄。
(4) 求 age 中除 Mary 与 James 这两人之外的那些人的年龄值,保存到变量 age1 中。
(5) 假设向量 x 长度为 n , 其元素是 { 1 , 2 , . . . , n } 的一个重排。可以把 x 看成一个 i 到 x[i] 的映射 (i 在 { 1 , 2 , . . . , n } 中取值 ) 。求向量 y, 保存了上述映射的逆映射,即:如果 x[i]=j, 则 y[j]=i 。
到此这篇关于R语言向量下标和子集的使用的文章就介绍到这了,更多相关R语言向量下标和子集内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

R语言-如何将list转换为向量
从excel中直接读取的数据为list,如下转换为向量 as.vector(unlist(x)) 补充:R语言基本运算,向量,矩阵,list,数组 1. 基本运算 1.1 加.减.乘.除 赋值可以使用a=数值,亦可以用a<-数值 1.2 余数.整除 1.3 绝对值: abs() .判断正负:sign() .幂.指数:^ .平方根:sqrt() 1.4 以二为底的对数: log2() .以十为底的对数:log10() .自定义底的对数:log(c,base=) .自然常数e的对数:log(a,ba
-
R语言实现支持向量机SVM应用案例
IRIS数据集简介 IRIS数据集中的数据源于1936年费希尔法发表的一篇论文.彼时他收集了三种鸢尾花(分别标记为setosa.versicolor和virginical)的花萼和花瓣数据.包括花萼的长度和宽度,以及花瓣的长度和宽度.我们将根据这四个特征来建立支持向量机模型从而实现对三种鸢尾花的分类判别任务. 有关数据可以从datasets软件包中的iris数据集里获取,下面我们演示性地列出了前5行数据.成功载入数据后,易见其中共包含了150个样本(被标记为setosa.versicolor和v
-
R语言最简单的向量赋值方法示例
1. 生成等差数列的向量x x <- 1:10 #将x向量赋值为1 2 3 4 5 6 7 8 9 10 结果为 > x [1] 1 2 3 4 5 6 7 8 9 10 2. 将x的值全部修改成0 x[] <- 0 #非常简洁的赋值方法,建议使用 x[1:length(x)] <- 0 #不建议使用的赋值方法 结果为: > x[] <- 0 > x [1] 0 0 0 0 0 0 0 0 0 0 3.使用seq函数 x <- seq(
-
R语言中向量的加法和乘法运算
在R语言中,不同长度的向量也是可以相加和相乘的,乘法的规则和加法类似 1,相同长度的向量相加 > x<- 1:4 > y<- 1:4 > z<- x+y > z [1] 2 4 6 8 规则就是 x[1]+y[1],x[2]+y[2],x[3]+y[3],x[4]+y[4] > x<- 1:4 > y<- 1:4 > z<- x*y > z [1] 1 4 9 16 乘法也类似 2,不同长度的向量相加 > x<
-
R语言中向量和矩阵简单运算的实现
一.向量运算 向量是有相同基本类型的元素序列,一维数组,定义向量的最常用办法是使用函数c(),它把若干个数值或字符串组合为一个向量. 1.R语言向量的产生方法 > x <- c(1,2,3) > x [1] 1 2 3 2.向量加减乘除都是对其对应元素进行的,例如下面 > x <- c(1,2,3) > y <- x*2 > y [1] 2 4 6 (注:向量的整数除法是%/%,取余是%%.) 3.向量的内积,有两种方法. 第一种方法:%*% > x
-
R语言-实现将向量转换成一个字符串
将向量a,b装换成一个字符串,其中: a=c(1,2,3,4) b=c(2,3,4,5) 为了将其转化成一个字符串可以通过引入包stringr,使用str_c实现,使用paste也一样可以达到目的,如下: library(stringr) a_b=str_c(a,b,collapse='') paste(a,b,sep='') 输出为: [1] "12233445" 在实际的数据处理中看可以用来给数据框建联合索引,比如数据框中需要用到的索引列联接成一列,则在实际中可以方便很多,避免很多
-
R语言中的vector(向量),array(数组)使用总结
对于那些有一点编程经验的人来说,vector,matrix,array,list,data.frame就相当于编程语言中的容器,因为只是将R看做数据处理工具所以它们的底层是靠什么实现的,内存怎么处理的具体也不要深究. R语言很奇怪的是它是面向对象的语言,所以经常会调用系统的方法,而且更奇怪的是总是调用"谓语"的方法,用起来像是写句子一样,记起来真是让人费解.比如is.vector(),read.table(),as.vector().. 直接开始吧:(由于习惯,大部分用"=&
-
R语言-因子与向量的转换方式
一.因子的特点或性质 1.因子可视为C或JAVA语言中的枚举,适用于有限状态的表示. 2.因子不可以赋枚举集合外的值,如一个因子包含male,female,则不能再赋male和female以为的值,赋其他值会将该元素设置为空值. 二.因子的建立 1.因子的建立 假定有因子gendor,为一组人的性别: > gendor<-factor(c('m','f','f','m'),labels=c('male','female')) 则通过上式建立一个性别因子. > gendor [1] fem
-
R语言向量知识点及实例讲解
有常见的六种基本的向量类型 创建向量 设定recursive = T,c函数可以从其他数据结构中递归形成向量 > v <- c(.295, .300, .250, .287, list(.102, .200, .303), recursive = T) > v [1] 0.295 0.300 0.250 0.287 0.102 0.200 0.303 > typeof(v) [1] "double" > v <- c(.295, .300, .250
-
R语言向量下标操作
向量下标即元素在向量中的位置,在实践中我们可以利用下标(元素的位置)来找出自己想要的数. 利用runif函数生成包含10个正整数的向量x. options(digits = 1) set.seed(1234) x <- runif(10,min = 1,max = 20) x [1] 3 13 13 13 17 13 1 5 14 11 正整数下标 我们可以输入正整数作为下标来找出对应位置的元素. 在[]内输入下标. #向量x的第一位置的元素 x[1] [1] 3 #向量x的第2位置的元素 x[