Nacos源码阅读方法
为什么我会经常阅读源码呢,因为阅读源码能让你更加接近大佬,哈哈,这是我瞎扯的。
这篇文章将会带大家阅读Nacos源码 以及 教大家阅读源码的技巧,我们正式开始吧!
先给大家献上一张我梳理的高清源码图,方便大家对nacos的源码有一个整体上的认识。
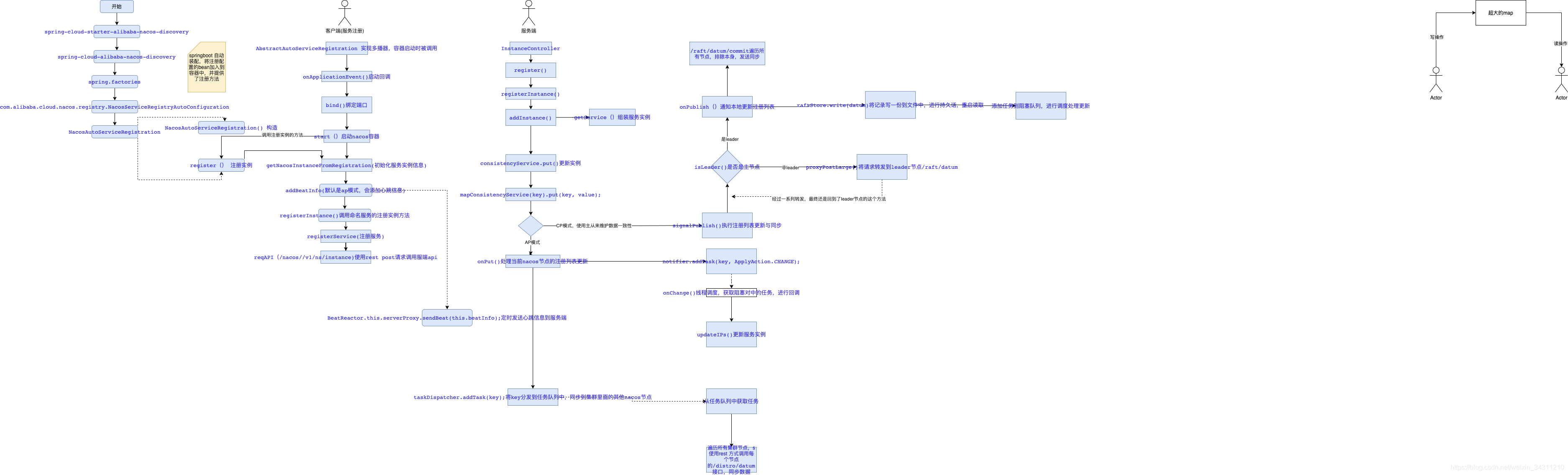
有了这张图,我们就很容易去看nacos源码了。
如何找切入点
首先我们得要找一个切入点进入到nacos源码中,那么就从nacos依赖入手
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
进入这个依赖文件,会发现它又依赖了一个组件:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-nacos-discovery</artifactId>
</dependency>
进入依赖之后,我们发现它长这样:
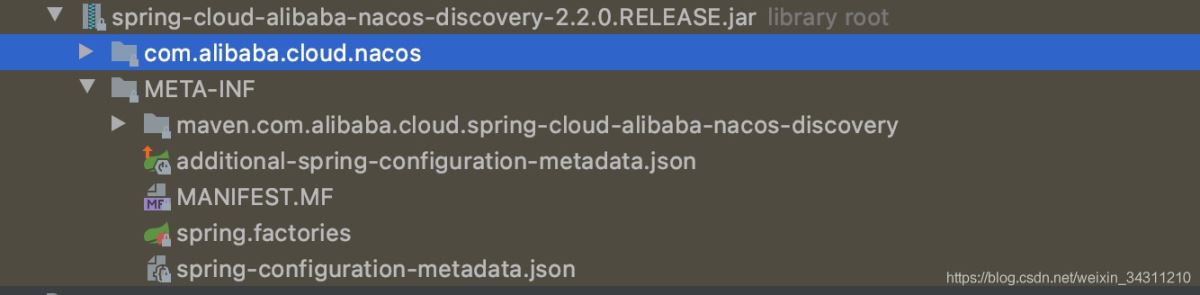
从这张图中,我们发现了一个熟悉的配置文件spring.factories,这是sringboot自动装配的必备文件
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.alibaba.cloud.nacos.discovery.NacosDiscoveryAutoConfiguration,\ com.alibaba.cloud.nacos.ribbon.RibbonNacosAutoConfiguration,\ com.alibaba.cloud.nacos.endpoint.NacosDiscoveryEndpointAutoConfiguration,\ com.alibaba.cloud.nacos.registry.NacosServiceRegistryAutoConfiguration,\ com.alibaba.cloud.nacos.discovery.NacosDiscoveryClientConfiguration,\ com.alibaba.cloud.nacos.discovery.reactive.NacosReactiveDiscoveryClientConfiguration,\ com.alibaba.cloud.nacos.discovery.configclient.NacosConfigServerAutoConfiguration org.springframework.cloud.bootstrap.BootstrapConfiguration=\ com.alibaba.cloud.nacos.discovery.configclient.NacosDiscoveryClientConfigServiceBootstrapConfiguration
因为这张主要说的是服务注册源码,所以我们可以只用关注(NacosServiceRegistryAutoConfiguration)自动装配文件
public class NacosServiceRegistryAutoConfiguration {
@Bean
public NacosServiceRegistry nacosServiceRegistry(
NacosDiscoveryProperties nacosDiscoveryProperties) {
return new NacosServiceRegistry(nacosDiscoveryProperties);
}
@ConditionalOnBean(AutoServiceRegistrationProperties.class)
public NacosRegistration nacosRegistration(
NacosDiscoveryProperties nacosDiscoveryProperties,
ApplicationContext context) {
return new NacosRegistration(nacosDiscoveryProperties, context);
public NacosAutoServiceRegistration nacosAutoServiceRegistration(
NacosServiceRegistry registry,
AutoServiceRegistrationProperties autoServiceRegistrationProperties,
NacosRegistration registration) {
return new NacosAutoServiceRegistration(registry,
autoServiceRegistrationProperties, registration);
}
我们看到的是三个bean注入,这里给大家介绍一个看源码的小技巧:自动装配的文件中申明的bean类,我们只需要看带有auto的bean,这个往往是入口;NacosAutoServiceRegistration 带有auto,我们点进去看看里面都有什么:
@Override
protected void register() {
if (!this.registration.getNacosDiscoveryProperties().isRegisterEnabled()) {
log.debug("Registration disabled.");
return;
}
if (this.registration.getPort() < 0) {
this.registration.setPort(getPort().get());
}
super.register();
}
里面有一个register()方法,我在这里打个断点,因为我猜测这个就是注册的入口,我现在使用debug模式,启动一个服务,看它会不会调用这个方法:
客户端注册
这里贴上我debug后,进入register方法的调用链截图

看到这个调用链,看到一个onApplicationEvent的回调方法,找到这个方法所在的类AbstractAutoServiceRegistration
这个类继承了ApplicationListener这个多播器监听器,spring启动之后,会发布多播器事件,然后回调实现多播器组件的onApplicationEvent方法,我们从这个方法开始分析:
public void onApplicationEvent(WebServerInitializedEvent event) {
bind(event); // 绑定端口,并启动
}
@Deprecated
public void bind(WebServerInitializedEvent event) {
// 设置端口
this.port.compareAndSet(0, event.getWebServer().getPort());
// 启动客户端注册组件
this.start();
}
public void start() {
// 省略分支代码
// 调用注册
register();
}
因为springcloud提供了多种注册中心扩展,但是我们这里只引用了nacos注册中心,所以这里直接调用的是NacosServiceRegistry的register方法:
public void register(Registration registration) {
// 省略分支代码
// 获取服务id
String serviceId = registration.getServiceId();
// 获取组配置
String group = nacosDiscoveryProperties.getGroup();
// 封装服务实例
Instance instance = getNacosInstanceFromRegistration(registration);
// 调用 命名服务的 registerInstance方法 注册实例
namingService.registerInstance(serviceId, group, instance);
}
进入到registerInstance方法
public void registerInstance(String serviceName, String groupName, Instance instance) throws NacosException {
if (instance.isEphemeral()) {
// 省略分支代码
// 与服务端建立心跳,默认每隔5秒定时发送新跳包
this.beatReactor.addBeatInfo(NamingUtils.getGroupedName(serviceName, groupName), beatInfo);
}
// 通过http方式向服务端发送注册请求
this.serverProxy.registerService(NamingUtils.getGroupedName(serviceName, groupName), groupName, instance);
}
serverproxy通过调用对http进行封装的reapi方法,向服务端接口("/nacos/v1/ns/instance")发送请求,
public void registerService(String serviceName, String groupName, Instance instance) throws NacosException {
LogUtils.NAMING_LOGGER.info("[REGISTER-SERVICE] {} registering service {} with instance: {}", new Object[]{this.namespaceId, serviceName, instance});
Map<String, String> params = new HashMap(9);
params.put("namespaceId", this.namespaceId);
params.put("serviceName", serviceName);
params.put("groupName", groupName);
params.put("clusterName", instance.getClusterName());
params.put("ip", instance.getIp());
params.put("port", String.valueOf(instance.getPort()));
params.put("weight", String.valueOf(instance.getWeight()));
params.put("enable", String.valueOf(instance.isEnabled()));
params.put("healthy", String.valueOf(instance.isHealthy()));
params.put("ephemeral", String.valueOf(instance.isEphemeral()));
params.put("metadata", JSON.toJSONString(instance.getMetadata()));
this.reqAPI(UtilAndComs.NACOS_URL_INSTANCE, params, (String)"POST");
}
我们知道nacos经常是以集群形式部署的,那客户端是如何选择其中一个节点发送呢,肯定得实现负载均衡的逻辑,我们点击reqAPI,看它是如何实现的
if (servers != null && !servers.isEmpty()) {
Random random = new Random(System.currentTimeMillis());
// 随机获取一个索引,servers保存的是所有nacos节点地址
int index = random.nextInt(servers.size());
// 遍历所有节点,根据index值,从servers中找到对应位置的server,进行请求调用,如果调用成功则返回,否则依次往后遍历,直到请求成功
for(int i = 0; i < servers.size(); ++i) {
String server = (String)servers.get(index);
try {
return this.callServer(api, params, server, method);
} catch (NacosException var11) {
exception = var11;
LogUtils.NAMING_LOGGER.error("request {} failed.", server, var11);
} catch (Exception var12) {
exception = var12;
LogUtils.NAMING_LOGGER.error("request {} failed.", server, var12);
}
// index+1 然后取模 是保证index不会越界
index = (index + 1) % servers.size();
}
throw new IllegalStateException("failed to req API:" + api + " after all servers(" + servers + ") tried: " + ((Exception)exception).getMessage());
}
到这里,客户端注册的代码已经分析完了,不过这还不是本篇的结束,我们还得继续分析服务端是如何处理客户端发送过来的注册请求:
服务端处理客户端注册请求
如果需要查看服务端源码的话,则需要将nacos源码下下来下载地址
我们从服务注册api接口地址(/nacos/v1/ns/instance),可以找到对应的controller为(com.alibaba.nacos.naming.controllers.InstanceController)
因为注册实例发送的是post请求,所以直接找被postmapping注解的register方法
@CanDistro
@PostMapping
public String register(HttpServletRequest request) throws Exception {
// 获取服务名
String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
// 获取命名空间id
String namespaceId = WebUtils.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
// 注册实例
serviceManager.registerInstance(namespaceId, serviceName, parseInstance(request));
return "ok";
}
我们点击进入到registerInstance方法:
public void registerInstance(String namespaceId, String serviceName, Instance instance) throws NacosException {
createEmptyService(namespaceId, serviceName, instance.isEphemeral());
Service service = getService(namespaceId, serviceName);
if (service == null) {
throw new NacosException(NacosException.INVALID_PARAM,
"service not found, namespace: " + namespaceId + ", service: " + serviceName);
}
// 执行添加实例的操作
addInstance(namespaceId, serviceName, instance.isEphemeral(), instance);
}
分析
在nacos中,注册实例后,还需要将注册信息同步到其他节点,所有在nacos中存在两种同步模式AP和CP,ap和cp主要体现在集群中如何同步注册信息到其它集群节点的实现方式上;
nacos通过ephemeral 字段值来决定是使用ap方式同步还是cp方式同步,默认使用的的ap方式同步注册信息。com.alibaba.nacos.naming.core.ServiceManager.addInstance()
public void addInstance(String namespaceId, String serviceName, boolean ephemeral, Instance... ips) throws NacosException {
// 生成服务的key
String key = KeyBuilder.buildInstanceListKey(namespaceId, serviceName, ephemeral);
// 获取服务
Service service = getService(namespaceId, serviceName);
// 使用同步锁处理
synchronized (service) {
List<Instance> instanceList = addIpAddresses(service, ephemeral, ips);
Instances instances = new Instances();
instances.setInstanceList(instanceList);
// 调用consistencyService.put 处理同步过来的服务
consistencyService.put(key, instances);
}
}
我们在进入到consistencyService.put方法中

点击put方法时,会看到有三个实现类,根据上下文(或者debug方式),可以推断出这里引用的是DelegateConsistencyServiceImpl实现类
@Override
public void put(String key, Record value) throws NacosException {
// 进入到这个put方法后,就可以知道应该使用ap方式同步还是cp方式同步
mapConsistencyService(key).put(key, value);
}
从下面的方法中 可以判断通过key来判断使用ap还是cp来同步注册信息,其中key是由ephemeral字段组成;
private ConsistencyService mapConsistencyService(String key) {
return KeyBuilder.matchEphemeralKey(key) ? ephemeralConsistencyService : persistentConsistencyService;
}
AP 方式同步的流程(ephemeralConsistencyService) 本地服务器处理注册信息&将注册信息同步到其它节点
@Override
public void put(String key, Record value) throws NacosException {
// 处理本地注册列表
onPut(key, value);
// 添加阻塞任务,同步信息到其他集群节点
taskDispatcher.addTask(key);
}
处理本地注册节点
nacos将key做为一个task,添加到notifer中阻塞队列tasks中,并且使用单线程执行,其中notifer是初始化的时候,作为一个线程被放到线程池中(线程池只设置了一个核心线程);
这里有一个点需要告诉大家:在大多数分布式框架,都会采用单线程的阻塞队列来处理耗时的任务,一方面解决并发问题,另一方面能够解决并发带来的写写冲突问题。
线程中的主要处理逻辑就是,循环读取阻塞队列中的内容,然后处理注册信息,更新到内存注册列表中。
同步注册信息到其他集群节点
nacos同样也是把注册key作为一个task存放到 TaskDispatcher 中的taskShedule阻塞队列中,然后开启线程循环读取阻塞队列:
@Override
public void run() {
List<String> keys = new ArrayList<>();
while (true) {
String key = queue.poll(partitionConfig.getTaskDispatchPeriod(),
TimeUnit.MILLISECONDS);
// 省略判断代码
// 添加同步的key
keys.add(key);
// 计数
dataSize++;
// 判断同步的key大小是否等于 批量同步设置的限量 或者 判断据上次同步时间 是否大于 配置的间隔周期,如果满足任意一个,则开始同步
if (dataSize == partitionConfig.getBatchSyncKeyCount() ||
(System.currentTimeMillis() - lastDispatchTime) > partitionConfig.getTaskDispatchPeriod()) {
// 遍历所有集群节点,直接调用http进行同步
for (Server member : dataSyncer.getServers()) {
if (NetUtils.localServer().equals(member.getKey())) {
continue;
}
SyncTask syncTask = new SyncTask();
syncTask.setKeys(keys);
syncTask.setTargetServer(member.getKey());
if (Loggers.DISTRO.isDebugEnabled() && StringUtils.isNotBlank(key)) {
Loggers.DISTRO.debug("add sync task: {}", JSON.toJSONString(syncTask));
}
dataSyncer.submit(syncTask, 0);
}
// 记录本次同步时间
lastDispatchTime = System.currentTimeMillis();
// 计数清零
dataSize = 0;
}
}
}
}
使用ap方式作同步的过程很简单,但是这里面有两种设计思路来解决单个key同步的问题:
如果有新的key推送上来,nacos就发起一次同步,这会造成网络资源浪费,因为每次同步的就只有一个key或者几个key;
同步少量的key解决方案: 只有积累到指定数量的key,才发起批量同步距离上次同步时间超过配置的限制时间,则忽略key数量,直接发起同步 CP 方式同步的流程(RaftConsistencyServiceImpl)
cp模式追求的是数据一致性,为了数据一致性,那么肯定得选出一个leader,由leader首先同步,然后再由leader通知follower前来获取最新的注册节点(或者主动推送给follower)
nacos使用raft协议来进行选举leader,来实现cp模式。
同样进入到 RaftConsistencyServiceImpl的put方法
@Override
public void put(String key, Record value) throws NacosException {
try {
raftCore.signalPublish(key, value);
} catch (Exception e) {
Loggers.RAFT.error("Raft put failed.", e);
throw new NacosException(NacosException.SERVER_ERROR, "Raft put failed, key:" + key + ", value:" + value, e);
}
}
进入到raftCore.signalPublish方法中,我提取几个关键的代码
// 首先判断当前nacos节点是否是leader,如果不是leader,则获取leader节点的ip,然后将请求转发到leader处理,否则往下走
if (!isLeader()) {
JSONObject params = new JSONObject();
params.put("key", key);
params.put("value", value);
Map<String, String> parameters = new HashMap<>(1);
parameters.put("key", key);
raftProxy.proxyPostLarge(getLeader().ip, API_PUB, params.toJSONString(), parameters);
return;
}
同样采用同样队列的方式,去处理本地注册列表
onPublish(datum, peers.local());
public void onPublish(Datum datum, RaftPeer source) throws Exception {
// 添加同步key任务到阻塞队列中
notifier.addTask(datum.key, ApplyAction.CHANGE);
Loggers.RAFT.info("data added/updated, key={}, term={}", datum.key, local.term);
}
遍历所有集群节点,发送http同步请求
for (final String server : peers.allServersIncludeMyself()) {
// 如果是leader,则不进行同步
if (isLeader(server)) {
latch.countDown();
continue;
}
// 组装url 发送同步请求到其它集群节点
final String url = buildURL(server, API_ON_PUB);
HttpClient.asyncHttpPostLarge(url, Arrays.asList("key=" + key), content, new AsyncCompletionHandler<Integer>() {
@Override
public Integer onCompleted(Response response) throws Exception {
if (response.getStatusCode() != HttpURLConnection.HTTP_OK) {
Loggers.RAFT.warn("[RAFT] failed to publish data to peer, datumId={}, peer={}, http code={}",
datum.key, server, response.getStatusCode());
return 1;
}
latch.countDown();
return 0;
}
@Override
public STATE onContentWriteCompleted() {
return STATE.CONTINUE;
}
});
}
到此,nacos服务注册及服务实例同步的主干源码已经分析完了。
总结
对于刚开始接触nacos源码的同学,可以先把头上的图多看几遍,然后对照着源码找到对应的位置 ,最后结合图再结合本文,整体连贯的看下来,相信会有很大收获的;虽然阅读源码的过程很痛苦,但是你只要坚持下来了,掌握到了阅读源码的技巧,你就会发现再难的源码,你都能把它啃下来;后面我会专门写一篇教你如何高效阅读源码的文章,希望对于刚接触源码的同学能有所帮助。
到此这篇关于Nacos源码阅读方法的文章就介绍到这了,更多相关Nacos源码阅读内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅析Alibaba Nacos注册中心源码剖析
Nacos&Ribbon&Feign核心微服务架构图 架构原理 微服务系统在启动时将自己注册到服务注册中心,同时外发布 Http 接口供其它系统调用(一般都是基于Spring MVC) 服务消费者基于 Feign 调用服务提供者对外发布的接口,先对调用的本地接口加上注解@FeignClient,Feign会针对加了该注解的接口生成动态代理,服务消费者针对 Feign 生成的动态代理去调用方法时,会在底层生成Http协议格式的请求,类似 /stock/deduct?productId=100
-
Nacos源码阅读方法
为什么我会经常阅读源码呢,因为阅读源码能让你更加接近大佬,哈哈,这是我瞎扯的. 这篇文章将会带大家阅读Nacos源码 以及 教大家阅读源码的技巧,我们正式开始吧! 先给大家献上一张我梳理的高清源码图,方便大家对nacos的源码有一个整体上的认识. 有了这张图,我们就很容易去看nacos源码了. 如何找切入点 首先我们得要找一个切入点进入到nacos源码中,那么就从nacos依赖入手 <dependency> <groupId>com.alibaba.cloud</groupI
-
CloudStack SSVM启动条件源码阅读与问题解决方法
CloudStack SSVM启动条件源码阅读与问题解决方法: 在CloudStack建立zone的时候,经常遇到SSVM不启动,或者根本就没有SSVM的情况,分析CloudStack日志,会发现有"Zone 1 is not ready to launch secondary storage VM yet"打印,意思是zone还未准备好启动SSVM. 通过查询CloudStack源代码,发现启动SSVM前有如下检查: 获取Zone里的template. select
-
Java终止线程实例和stop()方法源码阅读
了解线程 概念 线程 是程序中的执行线程.Java 虚拟机允许应用程序并发地运行多个执行线程. 线程特点 拥有状态,表示线程的状态,同一时刻中,JVM中的某个线程只有一种状态; ·NEW 尚未启动的线程(程序运行开始至今一次未启动的线程) ·RUNNABLE 可运行的线程,正在JVM中运行,但它可能在等待其他资源,如CPU. ·BLOCKED 阻塞的线程,等待某个锁允许它继续运行 ·WAITING 无限等待(再次运行依赖于让它进入该状态的线程执行某个特定操作) ·TIMED_WAITING 定时
-
Go Excelize API源码阅读Close及NewSheet方法示例解析
目录 一.Go-Excelize简介 二.Close() 三.NewSheet() 一.Go-Excelize简介 Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库,基于 ECMA-376,ISO/IEC 29500 国际标准.可以使用它来读取.写入由 Microsoft Excel™ 2007 及以上版本创建的电子表格文档. 支持 XLAM / XLSM / XLSX / XLTM / XLTX 等多种文档格式,高度兼容带有样式.图片(表).透视表.切片器等
-
Three.js源码阅读笔记(Object3D类)
这是Three.js源码阅读笔记的第二篇,直接开始. Core::Object3D Object3D似乎是Three.js框架中最重要的类,相当一部分其他的类都是继承自Object3D类,比如场景类.几何形体类.相机类.光照类等等:他们都是3D空间中的对象,所以称为Object3D类.Object3D构造函数如下: 复制代码 代码如下: THREE.Object3D = function () { THREE.Object3DLibrary.push( this ); this.id = THR
-
Three.js源码阅读笔记(物体是如何组织的)
这是Three.js源码阅读笔记第三篇.之前两篇主要是关于核心对象的,这些核心对象主要围绕着矢量vector3对象和矩阵matrix4对象展开的,关注的是空间中的单个顶点的位置和变化.这一篇将主要讨论Three.js中的物体是如何组织的:即如何将顶点.表面.材质组合成为一个具体的对象. Object::Mesh 该构造函数构造了一个空间中的物体.之所以叫"网格"是因为,实际上具有体积的物体基本都是建模成为"网格"的. 复制代码 代码如下: THREE.Mesh =
-
源码阅读之storm操作zookeeper-cluster.clj
storm操作zookeeper的主要函数都定义在命名空间backtype.storm.cluster中(即cluster.clj文件中). backtype.storm.cluster定义了两个重要protocol:ClusterState和StormClusterState. clojure中的protocol可以看成java中的接口,封装了一组方法.ClusterState协议中封装了一组与zookeeper进行交互的基础函数,如获取子节点函数,获取子节点数据函数等,ClusterStat
-
jdk源码阅读Collection详解
见过一句夸张的话,叫做"没有阅读过jdk源码的人不算学过java".从今天起开始精读源码.而适合精读的源码无非就是java.io,.util和.lang包下的类. 面试题中对于集合的考察还是比较多的,所以我就先从集合的源码开始看起. (一)首先是Collection接口. Collection是所有collection类的根接口;Collection继承了Iterable,即所有的Collection中的类都能使用foreach方法. /** * Collection是所有collec
-
Integer IntegerCache源码阅读
先看一段测试结果: /*public static void main(String[] args) { Integer a = 128, b = 128; Integer c = 127, d = 127; System.out.println(a == b);//false System.out.println(c == d);//true }*/ /*public static void main(String[] args) { Integer int1 = Integer.valueO
-
java源码阅读之java.lang.Object
Object是所有类的父类,任何类都默认继承Object.Object类到底实现了哪些方法? 1.clone方法 保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常. 2.getClass方法 final方法,获得运行时类型. 3.toString方法 该方法用得比较多,一般子类都有覆盖. 4.finalize方法 该方法用于释放资源.因为无法确定该方法什么时候被调用,很少使用. 5.equals方法 该