最小二乘法及其python实现详解
最小二乘法Least Square Method,做为分类回归算法的基础,有着悠久的历史(由马里·勒让德于1806年提出)。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。
那什么是最小二乘法呢?别着急,我们先从几个简单的概念说起。
假设我们现在有一系列的数据点 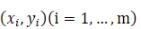 ,那么由我们给出的拟合函数h(x)得到的估计量就是
,那么由我们给出的拟合函数h(x)得到的估计量就是 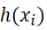 ,那么怎么评估我们给出的拟合函数与实际待求解的函数的拟合程度比较高呢?这里我们先定义一个概念:残差
,那么怎么评估我们给出的拟合函数与实际待求解的函数的拟合程度比较高呢?这里我们先定义一个概念:残差 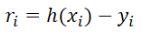 , 我们估计拟合程度都是在残差的基础上进行的。下面再介绍三种范数:
, 我们估计拟合程度都是在残差的基础上进行的。下面再介绍三种范数:
• ∞-范数:残差绝对值的最大值 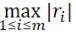 ,即所有数据点中残差距离的最大值
,即所有数据点中残差距离的最大值
• 1-范数:绝对残差和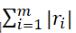 ,即所有数据点残差距离之和
,即所有数据点残差距离之和
• 2-范数:残差平方和 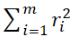
前两种范数是最容易想到,最自然的,但是不利于进行微分运算,在数据量很大的情况下计算量太大,不具有可操作性。因此一般使用的是2-范数。
说了这么多,那范数和拟合有什么关系呢?拟合程度,用通俗的话来讲,就是我们的拟合函数h(x)与待求解的函数y之间的相似性。那么2-范数越小,自然相似性就比较高了。
由此,我们可以写出最小二乘法的定义了:
对于给定的数据 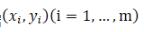 ,在取定的假设空间H中,求解h(x)∈H,使得残差
,在取定的假设空间H中,求解h(x)∈H,使得残差 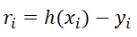 的2-范数最小,即
的2-范数最小,即
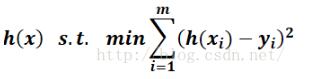
从几何上讲,就是寻找与给定点 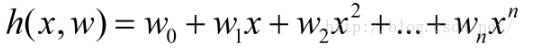 距离平方和最小的曲线y=h(x)。h(x)称为拟合函数或者最小二乘解,求解拟合函数h(x)的方法称为曲线拟合的最小二乘法。
距离平方和最小的曲线y=h(x)。h(x)称为拟合函数或者最小二乘解,求解拟合函数h(x)的方法称为曲线拟合的最小二乘法。
那么这里的h(x)到底应该长什么样呢?一般情况下,这是一条多项式曲线:
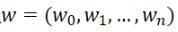
这里h(x,w)是一个n次多项式,w是其参数。
也就是说,最小二乘法就是要找到这样一组 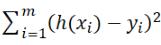 ,使得
,使得 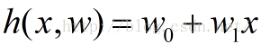 最小。
最小。
那么如何找到这样的w,使得其拟合函数h(x)与目标函数y具有最高拟合程度呢?即最小二乘法如何求解呢,这才是关键啊。
假设我们的拟合函数是一个线性函数,即:

(当然,也可以是二次函数,或者更高维的函数,这里仅仅是作为求解范例,所以采用了最简单的线性函数)那么我们的目标就是找到这样的w,
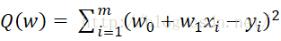
这里令 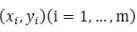 为样本
为样本  的平方损失函数
的平方损失函数
这里的Q(w)即为我们要进行最优化的风险函数。
学过微积分的同学应该比较清楚,这是一个典型的求解极值的问题,只需要分别对 18 求偏导数,然后令偏导数为0,即可求解出极值点,即:
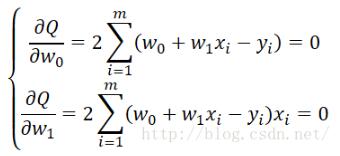
接下来只需要求解这个方程组即可解出w_i 的值
============ 分割分割 =============
上面我们讲解了什么是最小二乘法,以及如何求解最小二乘解,下面我们将通过Python来实现最小二乘法。
这里我们把目标函数选为y=sin(2πx),叠加上一个正态分布作为噪音干扰,然后使用多项式分布去拟合它。
代码:
# _*_ coding: utf-8 _*_ # 作者: yhao # 博客: http://blog.csdn.net/yhao2014 # 邮箱: yanhao07@sina.com import numpy as np # 引入numpy import scipy as sp import pylab as pl from scipy.optimize import leastsq # 引入最小二乘函数 n = 9 # 多项式次数 # 目标函数 def real_func(x): return np.sin(2 * np.pi * x) # 多项式函数 def fit_func(p, x): f = np.poly1d(p) return f(x) # 残差函数 def residuals_func(p, y, x): ret = fit_func(p, x) - y return ret x = np.linspace(0, 1, 9) # 随机选择9个点作为x x_points = np.linspace(0, 1, 1000) # 画图时需要的连续点 y0 = real_func(x) # 目标函数 y1 = [np.random.normal(0, 0.1) + y for y in y0] # 添加正太分布噪声后的函数 p_init = np.random.randn(n) # 随机初始化多项式参数 plsq = leastsq(residuals_func, p_init, args=(y1, x)) print 'Fitting Parameters: ', plsq[0] # 输出拟合参数 pl.plot(x_points, real_func(x_points), label='real') pl.plot(x_points, fit_func(plsq[0], x_points), label='fitted curve') pl.plot(x, y1, 'bo', label='with noise') pl.legend() pl.show()
输出拟合参数:

图像如下:
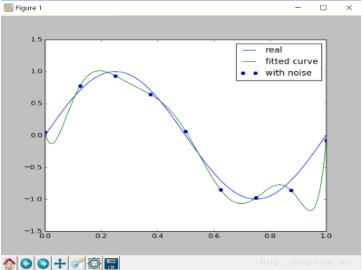
从图像上看,很明显我们的拟合函数过拟合了,下面我们尝试在风险函数的基础上加上正则化项,来降低过拟合的现象:
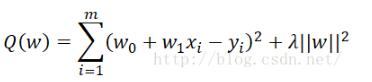
为此,我们只需要在残差函数中将lambda^(1/2)p加在了返回的array的后面
regularization = 0.1 # 正则化系数lambda # 残差函数 def residuals_func(p, y, x): ret = fit_func(p, x) - y ret = np.append(ret, np.sqrt(regularization) * p) # 将lambda^(1/2)p加在了返回的array的后面 return ret
输出拟合参数:

图像如下:
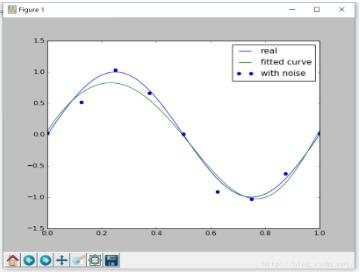
很明显,在适当的正则化约束下,可以比较好的拟合目标函数。
注意,如果正则化项的系数太大,会导致欠拟合现象(此时的惩罚项权重特别高)
如,设置regularization=0.1时,图像如下:
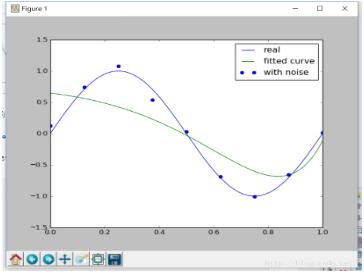
此时明显欠拟合。所以要慎重进行正则化参数的选择。
以上这篇最小二乘法及其python实现详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python中的几种矩阵乘法(小结)
一. np.dot() 1.同线性代数中矩阵乘法的定义.np.dot(A, B)表示: 对二维矩阵,计算真正意义上的矩阵乘积. 对于一维矩阵,计算两者的内积. 2.代码 [code] import numpy as np # 2-D array: 2 x 3 two_dim_matrix_one = np.array([[1, 2, 3], [4, 5, 6]]) # 2-D array: 3 x 2 two_dim_matrix_two = np.array([[1, 2], [3, 4],
-
关于多元线性回归分析——Python&SPSS
原始数据在这里 1.观察数据 首先,用Pandas打开数据,并进行观察. import numpy import pandas as pd import matplotlib.pyplot as plt %matplotlib inline data = pd.read_csv('Folds5x2_pp.csv') data.head() 会看到数据如下所示: 这份数据代表了一个循环发电厂,每个数据有5列,分别是:AT(温度), V(压力), AP(湿度), RH(压强), PE(输出电力).我
-
最小二乘法及其python实现详解
最小二乘法Least Square Method,做为分类回归算法的基础,有着悠久的历史(由马里·勒让德于1806年提出).它通过最小化误差的平方和寻找数据的最佳函数匹配.利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小.最小二乘法还可用于曲线拟合.其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达. 那什么是最小二乘法呢?别着急,我们先从几个简单的概念说起. 假设我们现在有一系列的数据点 ,那么由我们给出的拟合函数h(x)得到的估计量就是
-
Golang与python线程详解及简单实例
Golang与python线程详解及简单实例 在GO中,开启15个线程,每个线程把全局变量遍历增加100000次,因此预测结果是 15*100000=1500000. var sum int var cccc int var m *sync.Mutex func Count1(i int, ch chan int) { for j := 0; j < 100000; j++ { cccc = cccc + 1 } ch <- cccc } func main() { m = new(sync.
-
python getopt详解及简单实例
python getopt详解 函数原型: getopt.getopt(args, shortopts, longopts=[]) 参数解释: args:args为需要解析的参数列表.一般使用sys.argv[1:],这样可以过滤掉第一个参数(ps:第一个参数是脚本的名称,它不应该作为参数进行解析) shortopts:简写参数列表 longopts:长参数列表 返回值: opts:分析出的(option, value)列表对. args:不属于格式信息的剩余命令行参数列表. 源码分析 在An
-
Python注释详解
注释用于说明代码实现的功能.采用的算法.代码的编写者以及创建和修改的时间等信息. 注释是代码的一部分,注释起到了对代码补充说明的作用. Python注释 Python单行注释以#开头,单行注释可以作为单独的一行放在被注释的代码行之上,也可以放在语句或者表达式之后. #Give you a chance to let you know me print("Give you a chance to let you know me") say_what = "this is a d
-
python 类详解及简单实例
python 类详解 类 1.类是一种数据结构,可用于创建实例.(一般情况下,类封装了数据和可用于该数据的方法) 2.Python类是可调用的对象,即类对象 3.类通常在模块的顶层进行定义,以便类实例能够在类所定义的源代码文件中的任何地方被创建. 4.实例初始化 instance = ClassName(args....) 类在实例化时可以使用__init__和__del__两个特殊的方法. class ClassName(base): 'class documentation string'
-

神经网络理论基础及Python实现详解
一.多层前向神经网络 多层前向神经网络由三部分组成:输出层.隐藏层.输出层,每层由单元组成: 输入层由训练集的实例特征向量传入,经过连接结点的权重传入下一层,前一层的输出是下一层的输入:隐藏层的个数是任意的,输入层只有一层,输出层也只有一层: 除去输入层之外,隐藏层和输出层的层数和为n,则该神经网络称为n层神经网络,如下图为2层的神经网络: 一层中加权求和,根据非线性方程进行转化输出:理论上,如果有足够多的隐藏层和足够大的训练集,可以模拟出任何方程: 二.设计神经网络结构 使用神经网络之前,必须
-
对YOLOv3模型调用时候的python接口详解
需要注意的是:更改完源程序.c文件,需要对整个项目重新编译.make install,对已经生成的文件进行更新,类似于之前VS中在一个类中增加新函数重新编译封装dll,而python接口的调用主要使用的是libdarknet.so文件,其余在配置文件中的修改不必重新进行编译安装. 之前训练好的模型,在模型调用的时候,总是在 lib = CDLL("/home/*****/*******/darknet/libdarknet.so", RTLD_GLOBAL)这里读不到darknet编译
-
.dcm格式文件软件读取及python处理详解
要处理一些.DCM格式的焊接缺陷图像,需要读取和显示.dcm格式的图像.通过搜集资料收集到一些医学影像,并通过pydicom模块查看.dcm格式文件. 若要查看dcm格式文件,可下Echo viewer 进行查看. 若用过pycharm进行处理,可选用如下的代码: # -*-coding:utf-8-*- import cv2 import numpy import dicom from matplotlib import pyplot as plt dcm = dicom.read_file(
-
python 伯努利分布详解
伯努利分布 是一种离散分布,有两种可能的结果.1表示成功,出现的概率为p(其中0<p<1).0表示失败,出现的概率为q=1-p.这种分布在人工智能里很有用,比如你问机器今天某飞机是否起飞了,它的回复就是Yes或No,非常明确,这个分布在分类算法里使用比较多,因此在这里先学习 一下. 概率分布有两种类型:离散(discrete)概率分布和连续(continuous)概率分布. 离散概率分布也称为概率质量函数(probability mass function).离散概率分布的例子有伯努利分布(B
-
Python基础详解之描述符
一.描述符定义 描述符是一种类,我们把实现了__get__().__set__()和__delete__()中的其中任意一种方法的类称之为描述符. 描述符的作用是用来代理一个类的属性,需要注意的是描述符不能定义在被使用类的构造函数中,只能定义为类的属性,它只属于类的,不属于实例,我们可以通过查看实例和类的字典来确认这一点. 描述符是实现大部分Python类特性中最底层的数据结构的实现手段,我们常使用的@classmethod.@staticmethd.@property.甚至是__slots__