Golang超全面讲解并发
目录
- 1. goroutine
- 1.1 定义
- 1.2 goroutine切换点
- 2. channel
- 2.1 语法
- 2.2 channel作为参数
- 2.3 channel作为返回值
- 2.4 chan关闭
- 2.5 等待goroutine
- 3. select
- 4. 传统同步机制
- 5. 并发模式
- 5.1 生成器
- 5.2 定义接口
- 5.3 非阻塞管道
- 5.4 超时管道
- 6. 广度优先算法(迷宫)
- 6.1 代码实现
1. goroutine
1.1 定义
func main() {
for i := 0; i < 10; i++ {
//开启并发打印
go func(i int) {
fmt.Printf("hello goroutine : %d \n", i)
}(i)
}
time.Sleep(time.Millisecond)
}
go语言是采用一种叫 协程(Coroutine)
轻量级 “线程”
非抢占式 多任务处理,由协程主动交出CPU控制权
- 线程是由CPU来决定是否移交控制权,做到一半可能线程就会进行切换
- 协程则是由内部进行决定是否要移交CPU的控制权
编译器/解释器/虚拟机层面的多任务
多个协程可以在一个或者多个线程上运行 (由调度器来决定)
以下例子,通过 runtime.Gosched() 可以手动交出控制权,如果不交出控制权;还有如果在 gorotine 里面使用外部函数,如果不传入的话,就是一个闭包的变量,会导致数据冲突,就是通过不同的协程写入数据。检查数据是否有冲突可以通过以下语句进行检测
go run -race
func main() {
var a [10]int
for i := 0; i < 10; i++ {
//如果这里不将i传入参数直接引用外部的参数会出现:数据冲突(race condition)
go func(i int) {
// 打印语句会进行协程的调度,会交出控制权:fmt.Printf("hello goroutine : %d \n", i)
a[i]++
//通过 Gosched() 可以手动交出协程的控制权;如果不写这个语句协程就不会交出控制权进行调度执行,就会一直卡死在这里
runtime.Gosched()
}(i)
}
time.Sleep(time.Millisecond)
fmt.Println(a)
}
普通函数:在一个线程里面执行,调用完后释放资源,单向调用
协程:双向流通

但go的程序启动时,一个线程里面可能有多个 goroutine 执行,具体在哪个线程执行,由调度器决定;传统意义上的 routine 需要显示的写出释放控制权,而 goroutine 不需要写出来,调度器会进行切换
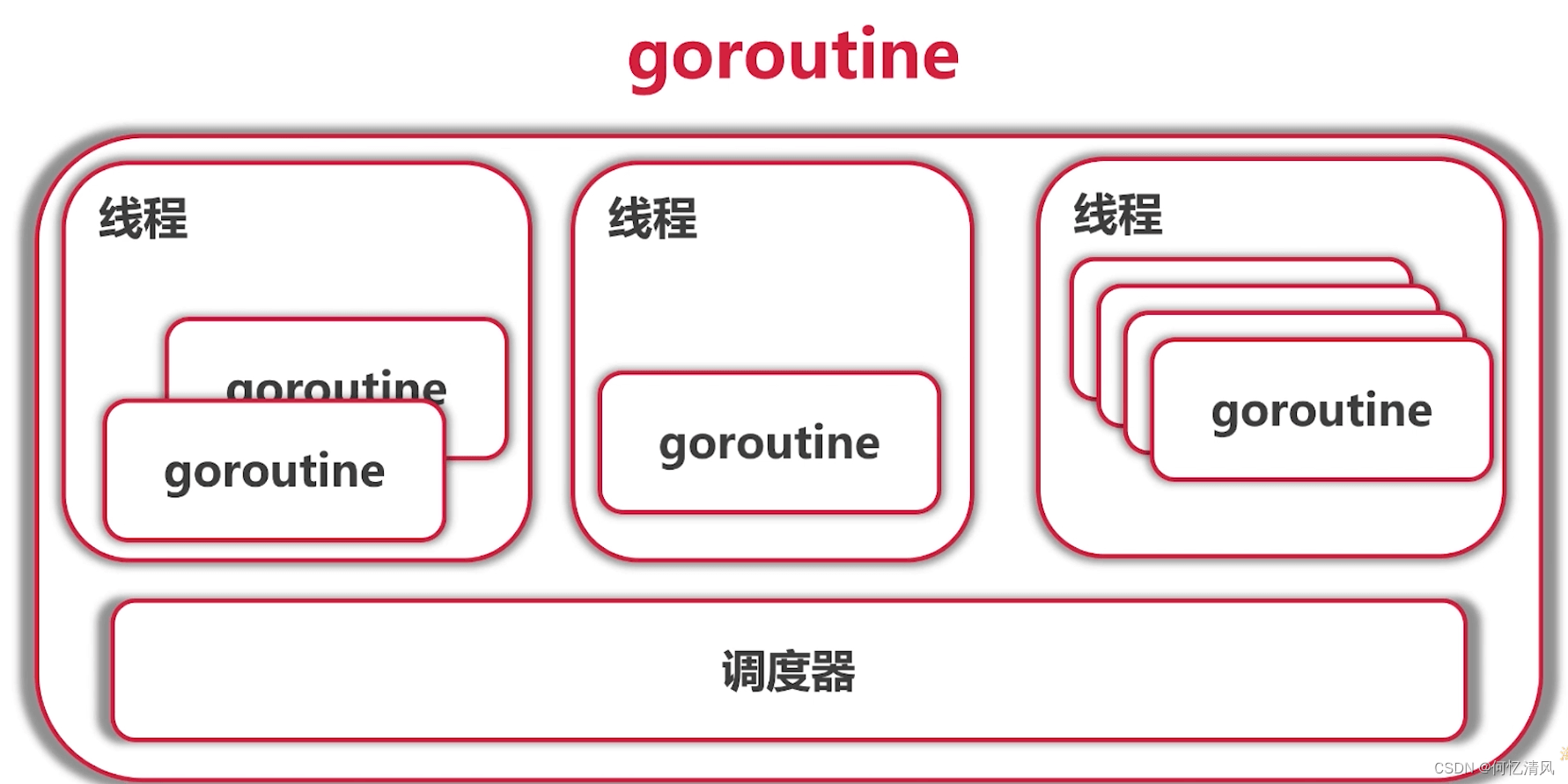
1.2 goroutine切换点
只是参考,不能保证肯定会切换
- I/O, select:打印数据的时候
- channel
- 等待锁
- 函数调用(有时)
- runtime.Gosched()
2. channel
协程与协程之间的双向通信
2.1 语法
func chanDemo() {
//var c chan int //为 nil 的chan不能使用
c := make(chan int)
go func() {
for {
n := <- c
fmt.Println(n)
}
}()
c <- 1 //向 c 里面发送数据(在发送时需要 goroutine 来进行接收,否则就会死锁)
c <- 2
}
2.2 channel作为参数
func worker(i int, c chan int) {
for {
fmt.Printf("Worker :%d, accpet: %c \n", i, <-c)
}
}
func chanDemo() {
var channels [10]chan int
for i := 0; i < 10; i++ {
channels[i] = make(chan int)
go worker(i, channels[i])
}
for i := 0; i < 10; i++ {
channels[i] <- 'a' + i
}
for i := 0; i < 10; i++ {
channels[i] <- 'A' + i
}
}
2.3 channel作为返回值
返回值定义:chan<- int :代表只能发数据; <-chan int:代表只能收数据
// chan<- int :代表只能发数据; <-chan int:代表只能收数据
func worker(i int) chan int {
c := make(chan int)
go func() {
for {
fmt.Printf("Worker :%d, accpet: %c \n", i, <-c)
}
}()
return c
}
func chanDemo() {
var channels [10]chan int
for i := 0; i < 10; i++ {
channels[i] = worker(i)
}
for i := 0; i < 10; i++ {
channels[i] <- 'a' + i
}
for i := 0; i < 10; i++ {
channels[i] <- 'A' + i
}
}
创建时可以指定 channel 的大小,make(chan int, 3) 如果数据超过3个就会死锁,对提升性能有好处。
2.4 chan关闭
如果不 close 那么会一直接收下去,可以是否 if、range 进行判断是否 close
不要通过共享内存来进行通信,要通过通信来共享内存
func chanClose() {
//创建一个缓冲区
c := make(chan int, 3)
c <- 1
c <- 2
c <- 3
//方法一:
go func() {
for {
//如果没有接收到数据就直接返回
if i, ok := <-c; !ok {
fmt.Println(" close channel.....")
break
} else {
//死循环读取,如果外部 chan 已经关闭了,这里会一直接收具体数据的默认值
fmt.Printf("%d\n", i)
}
}
}()
//方法二:
go func() {
for n := range c {
//如果没有接收到数据就直接返回
fmt.Printf("%d\n", n)
}
}()
//close关闭 channel
close(c)
}
2.5 等待goroutine
如何等待所有的 goroutine 执行完之后才退出程序?
方式一:
func ChanDemo() {
workers := make([]worker, 10)
for i, _ := range workers {
workers[i] = createWorker(i)
}
for i, worker := range workers{
worker.in <- 'a' + i
}
for i, worker := range workers{
worker.in <- 'A' + i
}
//这种方式可以接收消费者传入的数据,如果消费者传入的数据是同步的话,这里也会出现死锁
for _, worker := range workers {
<- worker.done
<- worker.done
}
}
//定义一个worker的结构用来存放 chan数据
type worker struct {
done chan bool
in chan int
}
func createWorker(id int) worker {
w := worker{
done: make(chan bool),
in: make(chan int),
}
go doWorker(id, w.in, w.done)
return w
}
func doWorker(id int, in chan int, done chan bool) {
for i := range in {
fmt.Printf("Worker:%d, accept:%c \n", id, i)
go func() {
//异步发送,否则会出现死锁,因为发送会加锁
done <- true
}()
}
}
方式二:
使用 sync.WaitGroup 等待所有的 gorounte 执行结束
//定义一个worker的结构用来存放 chan数据
type done2Worker struct {
in chan int
//使用指针传递
wg *sync.WaitGroup
}
func create2Worker(id int, group *sync.WaitGroup) done2Worker {
w := done2Worker{
wg: group,
in: make(chan int),
}
go do2Worker(id, w)
return w
}
func do2Worker(id int, worker2 done2Worker) {
for i := range worker2.in {
fmt.Printf("Worker:%d, accept:%c \n", id, i)
//执行完成
worker2.wg.Done()
}
}
func Chan2Demo() {
var wg sync.WaitGroup
workers := make([]done2Worker, 10)
for i, _ := range workers {
workers[i] = create2Worker(i, &wg)
}
wg.Add(20)
for i, worker := range workers {
worker.in <- 'a' + i
}
for i, worker := range workers {
worker.in <- 'A' + i
}
wg.Wait()
}
3. select
select 可以对 channel 进行非阻塞式调用,谁先来执行谁,在 select 中也可以使用 nil 进行调度
func generator() chan int {
out := make(chan int)
go func() {
i := 0
for {
//休眠随机数
time.Sleep(time.Duration(rand.Intn(1500)) * time.Millisecond)
out <- i
i++
}
}()
return out
}
func main() {
//非阻塞式获取数据,谁先出数据就执行哪一段逻辑
var c1, c2 = generator(), generator()
// 10秒钟后发送一次数据
after := time.After(time.Second * 10)
//每秒钟都会写一次数据
tick := time.Tick(time.Second)
//死循环获取channel中的数据
for {
select {
//会通过select关键字进行调用,谁先来数据,就执行谁
case n := <-c1:
fmt.Println("Received from c1:", n)
case n := <-c2:
fmt.Println("Received from c2:", n)
case <-after:
fmt.Println("ten second after......")
case <-tick:
fmt.Println("tick task exec .....")
default:
fmt.Println("No value received")
}
}
}
4. 传统同步机制
CSP : 模型下面尽量少用传统的同步方式,传统的方式使用共享变量进行使用
- WaitGroup
- Mutex
type atomicInt struct {
a int
//定义互斥量进行同步
lock sync.Mutex
}
func (a *atomicInt) add() {
a.lock.Lock()
defer a.lock.Unlock()
a.a++
}
func main() {
a := atomicInt{
a: 0,
}
a.add()
go a.add()
time.Sleep(time.Millisecond)
fmt.Println("value : ", a.a)
}
Cond
5. 并发模式
5.1 生成器
//传入多个chan,返回一个只能输出的chan
func fanIn(chs...chan string) <-chan string {
//创建管道
c := make(chan string)
//这里循环读取 chs 管道传入的数据
for _ , ch := range chs {
go func(in chan string) {
for {
//循环从chCopy里面读取数据后传入到返回出去的chan
//这里不能直接使用 ch ,因为该变量是一个闭包,后续遍历的管道会将其覆盖
c <- <-in
}
}(ch)
}
return c
}
//创建一个channel,循环的发送数据
func msgGen(serviceName string) chan string {
ch := make(chan string)
go func() {
for {
ch<- fmt.Sprintf("hello:%s", serviceName)
}
}()
return ch
}
func main() {
s1 := msgGen("service1")
s2 := msgGen("service2")
s3 := msgGen("service3")
//可以拿到返回出来的 channel 跟服务继续做交互
m := fanIn(s1, s2, s3)
for {
fmt.Println(<-m)
}
}
5.2 定义接口
// ChannelCreateFunc 创建接口,需要传入管道,以及参数
type ChannelCreateFunc interface {
// Create 创建函数传入一个任何类型的管道,后面参数选择性传入
Create(ch <-chan any, V...any) (any, bool)
}
func Creator(c ChannelCreateFunc, ch <-chan any) {
if r, ok := c.Create(ch, time.Duration(time.Second)); ok {
fmt.Println(r)
} else {
fmt.Println("未接收到数据")
}
}
func main() {
s1 := msgGen("service1")
m := fanIn(s1)
Creator(timeout.TimeoutCreator{}, m)
Creator(noblock.NotBlockCreator{}, m)
}
5.3 非阻塞管道
新建 noblock.go,定义下面这样的格式
type NotBlockCreator struct {
}
func (n NotBlockCreator) Create(ch <-chan any, V...any) (any, bool) {
select {
case m := <-ch:
return m, true
default:
return "", false
}
}
5.4 超时管道
新建 timeout.go
type TimeoutCreator struct {
}
func (t TimeoutCreator) Create(ch <-chan any, V...any) (any, bool) {
size := len(V)
if size == 1 {
var timeoutValue = V[0]
switch v := timeoutValue.(type) {
case time.Duration:
for {
select {
case m := <-ch:
return m, true
case <-time.After(v):
fmt.Println("数据超时接收,直接返回false")
return "", false
}
}
}
}
return "", false
}
6. 广度优先算法(迷宫)

每次探索都是一层一层的向外进行探索,如果起始为0,那么先将周边的 1 进行探索完毕,探索1时会将1的点位先存入到队列中,等后续所有的1都探索完成之后,再取出1的点位进行1周边的探索
通过上面的这种点位算法,就可以将迷宫的路画出来
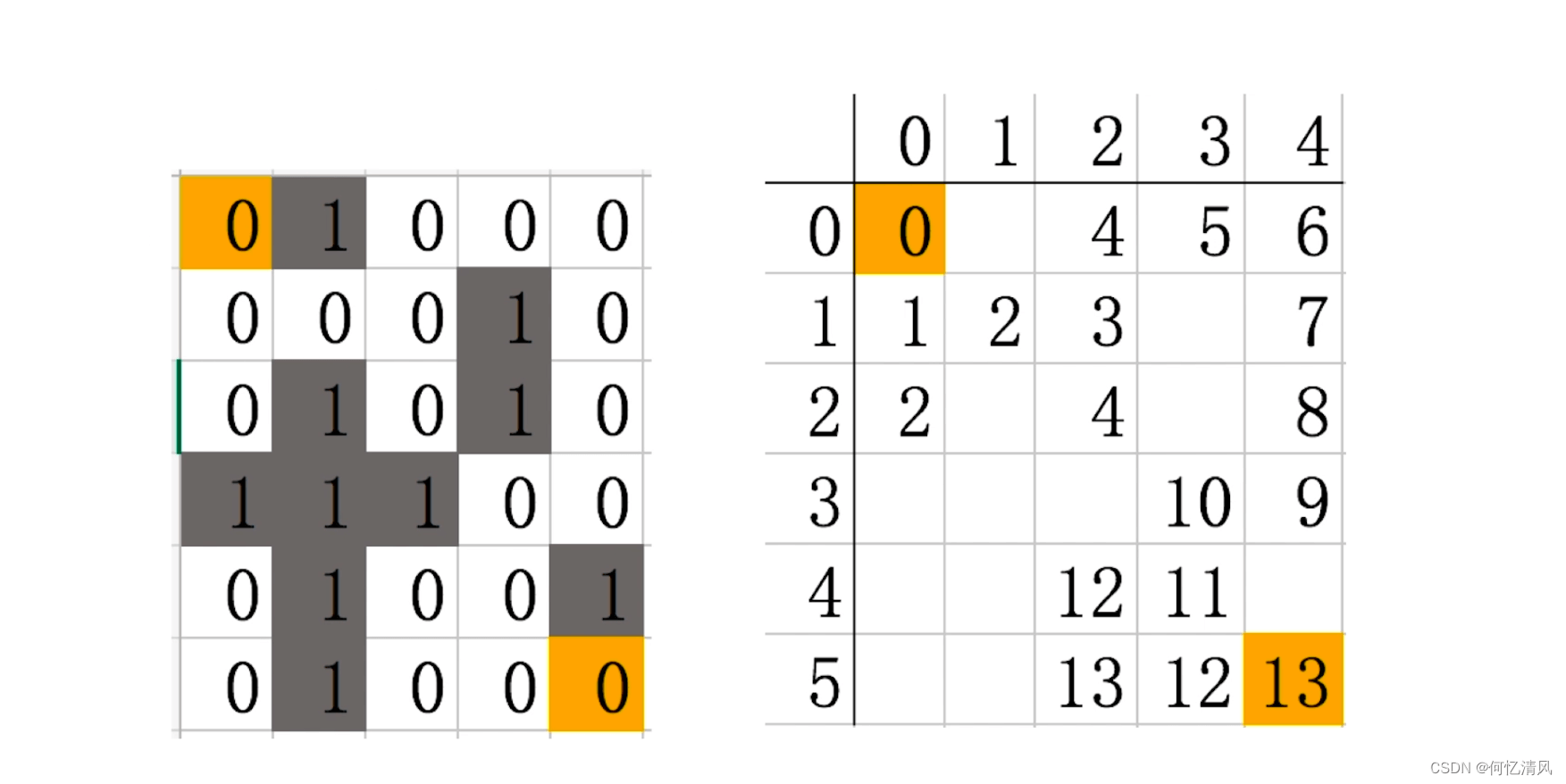
6.1 代码实现
创建文本,这里需要注意,idea创建文件分隔符编码需要设置以下,否则后续读取文件时会有问题
6 5
0 1 0 0 0
0 0 0 1 0
0 1 0 1 0
1 1 1 0 0
0 1 0 0 1
0 1 0 0 0
读取文件成二维数组
// Fscanf函数在读取文件时,遇到\r为默认替换为0,读取\n结束,如果编码不对,这里读取就会出问题
func readMaze(path string) [][]int {
file, err := os.Open(path)
if err != nil {
panic(err)
}
var row, col int
//这里需要取地址,函数里面会更改row和col的值
fmt.Fscanf(file, "%d %d", &row, &col)
fmt.Printf("%d\t%d\n", row, col)
//创建一个二位数组,一共有多少行
maze := make([][]int, row)
for i := range maze {
//创建列
maze[i] = make([]int, col)
for j := range maze[i] {
fmt.Fscanf(file, "%d", &maze[i][j])
}
}
return maze
}
func main() {
//读取迷宫文件
maze := readMaze("maze/maze.in")
for _, row := range maze {
for _, col := range row {
fmt.Printf("%d\t", col)
}
fmt.Println()
}
}
//点位的结构体
type point struct {
i, j int
}
//定义需要探索的方向
var dirs = [4]point {
//当前位置-1,就是向上
{-1, 0},
//左边的点位
{0, -1},
//向下的点位
{1, 0},
//向右的点位
{0, 1},
}
//将两个点位相加,就可以获取到下一个点位
func (p point) add(r point) point {
return point{p.i + r.i, p.j + r.j}
}
func (p point) at(grid [][]int) (int, bool) {
//首先判断点位是否越界了,例如传入的点位 (-1,0)或者(1, -1)
if p.i < 0 || p.i >= len(grid) {
return 0, false
}
//判断j列是否越界了
if p.j < 0 || p.j >= len(grid[p.i]) {
return 0, false
}
//返回数据
return grid[p.i][p.j], true
}
// walk 传入迷宫,指定迷宫开始的点位,以及出口的点位
func walk(maze [][]int, start, end point) [][]int {
//创建走过的步
steps := make([][]int, len(maze))
for i := range steps {
steps[i] = make([]int, len(maze[i]))
}
//创建需要探索的队列,初始的点位(0,0)
Q := []point{start}
for len(Q) > 0 {
cur := Q[0]
//截取出队列中的头部
Q = Q[1:]
//判断如果点位等于出口的点位,那么直接退出
if cur == end {
break
}
//dirs为点位周边的四个方向,我这里采用的是 上、左、下、右 的方向进行探索
for _, dir := range dirs {
//将当前点位跟四个方向相加,例如 (0,0) 向上的方向就是(-1,0),将i的值进行减1
next := cur.add(dir)
//判断向上的点位不能超出迷宫的界限,并且返回在迷宫中的值,因为如果返回的值为1,就证明是墙
val, ok := next.at(maze)
if !ok || val == 1 {
continue
}
//不等0就证明是墙
val, ok = next.at(steps)
if !ok || val != 0 {
continue
}
//如果是起点,就跳过
if next == start {
continue
}
//获取到当前步数的值
curSteps, _ := cur.at(steps)
//将走过的点位追加到切片中
steps[next.i][next.j] = curSteps + 1
//继续将下一个点位添加到需要探索的队列当中
Q = append(Q, next)
}
}
return steps
}
到此这篇关于Golang超全面讲解并发的文章就介绍到这了,更多相关Golang并发内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

golang并发工具MapReduce降低服务响应时间
目录 前言 并发处理工具MapReduce MapReduce的用法演示 MapReduce使用注意事项 实现原理分析: 文末 前言 在微服务中开发中,api网关扮演对外提供restful api的角色,而api的数据往往会依赖其他服务,复杂的api更是会依赖多个甚至数十个服务.虽然单个被依赖服务的耗时一般都比较低,但如果多个服务串行依赖的话那么整个api的耗时将会大大增加. 那么通过什么手段来优化呢?我们首先想到的是通过并发来的方式来处理依赖,这样就能降低整个依赖的耗时,Go基础库中为我们提供
-
Golang 语言控制并发 Goroutine的方法
goroutine 是 Go语言中的轻量级线程实现,由 Go 运行时(runtime)管理.Go 程序会智能地将 goroutine 中的任务合理地分配给每个 CPU. 01介绍 Golang 语言的优势之一是天生支持并发,我们在 Golang 语言开发中,通常使用的并发控制方式主要有 Channel,WaitGroup 和 Context,本文我们主要介绍一下 Golang 语言中并发控制的这三种方式怎么使用?关于它们各自的详细介绍在之前的文章已经介绍过,感兴趣的读者朋友们可以按需翻阅. 02
-
Golang CSP并发机制及使用模型
目录 CSP并发模型 Golang CSP Channel Goroutine Goroutine 调度器 总结 今天介绍一下 go语言的并发机制以及它所使用的CSP并发模型 CSP并发模型 CSP模型是上个世纪七十年代提出的,用于描述两个独立的并发实体通过共享的通讯 channel(管道)进行通信的并发模型. CSP中channel是第一类对象,它不关注发送消息的实体,而关注与发送消息时使用的channel. Golang CSP Golang 就是借用CSP模型的一些概念为之实现并发进行理论
-
golang中的并发和并行
golang中默认使用一个CPU,这时程序无法并发,只能是并发.因为始终只有一个CPU在运行. package main import ( "fmt" "runtime" ) //并发和并行 var quit chan int = make(chan int) func loop() { for i := 0; i < 100; i++ { //为了观察,跑多些 fmt.Printf("%d ", i) } quit <- 0 } f
-
解析golang中的并发安全和锁问题
1. 并发安全 package main import ( "fmt" "sync" ) var ( sum int wg sync.WaitGroup ) func test() { for i := 0; i < 5000000; i++ { sum += 1 } wg.Done() } func main() { // 并发和安全锁 wg.Add(2) go test() go test() wg.Wait() fmt.Println(sum) } 上面
-
Golang 并发下的问题定位及解决方案
目录 问题描述 解决方案 实现思路 2.1通过栈信息解析后获取 2.2修改Go源码获取 2.3通过CGO获取 问题描述 在使用 gin-swagger 的过程中, 经常会发生因为缺少 json 等 tag 而导致的异常. 由于 gin-swagger 是并发执行的, 输出的日志本身是错位的. 这就导致无法定义是哪一个结构体缺少 tag 导致的. 一般而言, 这种时候只能一个个点开去检查. 解决方案 思路 : 要是每行日志带当前 goroutine_id 的话, 是不是就可以准确定位到报错的 go
-
解决Golang并发工具Singleflight的问题
目录 前言 定义 用途 简单Demo 源码分析 结构 对外暴露的方法 重点方法分析 Do 流程图 Forget doCall 实际使用 弊端与解决方案 参考文章 前言 前段时间在一个项目里使用到了分布式锁进行共享资源的访问限制,后来了解到Golang里还能够使用singleflight对共享资源的访问做限制,于是利用空余时间了解,将知识沉淀下来,并做分享 文章尽量用通俗的语言表达自己的理解,从入门demo开始,结合源码分析singleflight的重点方法,最后分享singleflight的实际
-
Golang并发读取文件数据并写入数据库的项目实践
目录 需求 项目结构 获取data目录下的文件 按行读取文本数据 数据类型定义 并发读取文件 将数据写入数据库 完整main.go代码 测试运行 需求 最近接到一个任务,要把一批文件中的十几万条JSON格式数据写入到Oracle数据库中,Oracle是企业级别的数据库向来以高性能著称,所以尽可能地利用这一特性.当时第一时间想到的就是用多线程并发读文件并操作数据库,而Golang是为并发而生的,用Golang进行并发编程非常方便,因此这里选用Golang并发读取文件并用Gorm操作数据库.然而Go
-
Golang并发操作中常见的读写锁详析
互斥锁简单粗暴,谁拿到谁操作.今天给大家介绍一下读写锁,读写锁比互斥锁略微复杂一些,不过我相信我们今天能够把他拿下! golang读写锁,其特征在于 读锁:可以同时进行多个协程读操作,不允许写操作 写锁:只允许同时有一个协程进行写操作,不允许其他写操作和读操作 读写锁有两种模式.没错!一种是读模式,一种是写模式.当他为写模式的话,作用和互斥锁差不多,只允许有一个协程抢到这把锁,其他协程乖乖排队.但是读模式就不一样了,他允许你多个协程读,但是不能写.总结起来就是: 仅读模式: 多协程可读不可写 仅
-
Golang超全面讲解并发
目录 1. goroutine 1.1 定义 1.2 goroutine切换点 2. channel 2.1 语法 2.2 channel作为参数 2.3 channel作为返回值 2.4 chan关闭 2.5 等待goroutine 3. select 4. 传统同步机制 5. 并发模式 5.1 生成器 5.2 定义接口 5.3 非阻塞管道 5.4 超时管道 6. 广度优先算法(迷宫) 6.1 代码实现 1. goroutine 1.1 定义 func main() { for i := 0;
-
Python多进程并发与同步机制超详细讲解
目录 多进程 僵尸进程 Process类 函数方式 继承方式 同步机制 状态管理Managers 在<多线程与同步>中介绍了多线程及存在的问题,而通过使用多进程而非线程可有效地绕过全局解释器锁. 因此,通过multiprocessing模块可充分地利用多核CPU的资源. 多进程 多进程是通过multiprocessing包来实现的,multiprocessing.Process对象(和多线程的threading.Thread类似)用来创建一个进程对象: 在类UNIX平台上,需要对每个Proce
-
GoLang中panic与recover函数以及defer语句超详细讲解
目录 一.运行时恐慌panic 二.panic被引发到程序终止经历的过程 三.有意引发一个panic并让panic包含一个值 四.施加应对panic的保护措施从而避免程序崩溃 五.多条defer语句多条defer语句的执行顺序 一.运行时恐慌panic panic是一种在运行时抛出来的异常.比如"index of range". panic的详情: package main import "fmt" func main() { oneC := []int{1, 2,
-
超详细讲解Linux C++多线程同步的方式
目录 一.互斥锁 1.互斥锁的初始化 2.互斥锁的相关属性及分类 3,测试加锁函数 二.条件变量 1.条件变量的相关函数 1)初始化的销毁读写锁 2)以写的方式获取锁,以读的方式获取锁,释放读写锁 四.信号量 1)信号量初始化 2)信号量值的加减 3)对信号量进行清理 背景问题:在特定的应用场景下,多线程不进行同步会造成什么问题? 通过多线程模拟多窗口售票为例: #include <iostream> #include<pthread.h> #include<stdio.h&
-
超详细讲解Java线程池
目录 池化技术 池化思想介绍 池化技术的应用 如何设计一个线程池 Java线程池解析 ThreadPoolExecutor使用介绍 内置线程池使用 ThreadPoolExecutor解析 整体设计 线程池生命周期 任务管理解析 woker对象 Java线程池实践建议 不建议使用Exectuors 线程池大小设置 线程池监控 带着问题阅读 1.什么是池化,池化能带来什么好处 2.如何设计一个资源池 3.Java的线程池如何使用,Java提供了哪些内置线程池 4.线程池使用有哪些注意事项 池化技术
-
Java 超详细讲解对象的构造及初始化
目录 如何初始化对象 构造方法 特性 默认初始化 就地初始化 如何初始化对象 我们知道再Java方法内部定义一个局部变量的时候,必须要初始化,否则就会编译失败 要让这串代码通过编译,很简单,只需要在正式使用a之前,给a设置一个初始值就好那么对于创造好的对象来说,我们也要进行相对应的初始化我们先写一个Mydate的类 public class MyDate { public int year; public int month; public int day; /** * 设置日期: */ pub
-
Mysql超详细讲解死锁问题的理解
目录 1.什么是死锁? 2.Mysql出现死锁的必要条件 资源独占条件 请求和保持条件 不剥夺条件 相互获取锁条件 3. Mysql经典死锁案例 3.1 建表语句 3.2 初始化相关数据 3.3 正常转账过程 3.4 死锁转账过程 3.5 死锁导致的问题 4.如何解决死锁问题? 4.1 打破请求和保持条件 4.2 打破相互获取锁条件(推荐) 5.总结 1.什么是死锁? 死锁指的是在两个或两个以上不同的进程或线程中,由于存在共同资源的竞争或进程(或线程)间的通讯而导致各个线程间相互挂起等待,如果没
-
Java超详细讲解多线程中的Process与Thread
目录 进程和线程的关系 操作系统是如何管理进程的 并行和并发 创建线程的方法 串行执行和并发执行 Thread中的一次额重要方法 中断线程 线程等待 线程休眠(sleep) 进程和线程的关系 在操作系统中运行的程序就是进程,比如说QQ,播放器,游戏等等…程序是指令和数据的有序集合,其本身没有任何运行的含义,是一个静态的概念. 进程和线程都是为了处理并发编程这样的场景,但是进程有问题,频繁拆功创建和释放资源的时候效率低,相比之下,线程更轻量,创建和释放效率更高. 进程具有独立性,每个进程有各自独立
-
SpringCloud超详细讲解Feign声明式服务调用
目录 入门案例 @FeignClient注解详解 Feign Client的配置 Feign请求添加headers 负载均衡 (Ribbon) 容错机制 Hystrix支持 Sentinel支持 Feign开启容错机制支持后的使用方式 请求压缩feign.compression 日志级别 入门案例 在服务消费者导入依赖 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>
-
Spring超详细讲解事务
目录 什么是事务 事务的四个特性(ACID) Spring对事务的支持 编程式事务管理 声明式事务管理 基于注解的声明式事务管理 Spring事务管理的三个接口 Spring事务属性 什么是事务 一个数据库事务是一个被视为一个工作单元的逻辑上的一组操作,这些操作要么全部执行,要么全部不执行. 需要注意的是,并不是所有的数据库(引擎)都支持事务,比如说MySQL的MyISAM存储引擎 事务的四个特性(ACID) 原子性:事务是一个原子性操作,一个事务由一系列操作组成,这一系列操作要么全部执行完成,