Java HashMap遍历方法汇总
目录
- 1.JDK 8 之前的遍历
- 1.1 EntrySet 遍历
- 1.2 KeySet 遍历
- 2.KeySet 性能问题
- 2.1 EntrySet 迭代器遍历
- 2.2 KeySet 迭代器遍历
- 2.3 迭代器的作用
- 2.4 不使用迭代器删除
- 2.5 使用迭代器删除
- 3.JDK 8 之后的遍历
- 3.1 Lambda 遍历
- 3.2 Stream 单线程遍历
- 3.3 Stream 多线程遍历
- 4.推荐使用哪种遍历方式?
- 总结
前言:
HashMap 的遍历方法有很多种,不同的 JDK 版本有不同的写法,其中 JDK 8 就提供了 3 种 HashMap 的遍历方法,并且一举打破了之前遍历方法“很臃肿”的尴尬。
1.JDK 8 之前的遍历
JDK 8 之前主要使用 EntrySet 和 KeySet 进行遍历,具体实现代码如下。
1.1 EntrySet 遍历
EntrySet 是早期 HashMap 遍历的主要方法,其实现代码如下:
public static void main(String[] args) {
// 创建并赋值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循环遍历
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
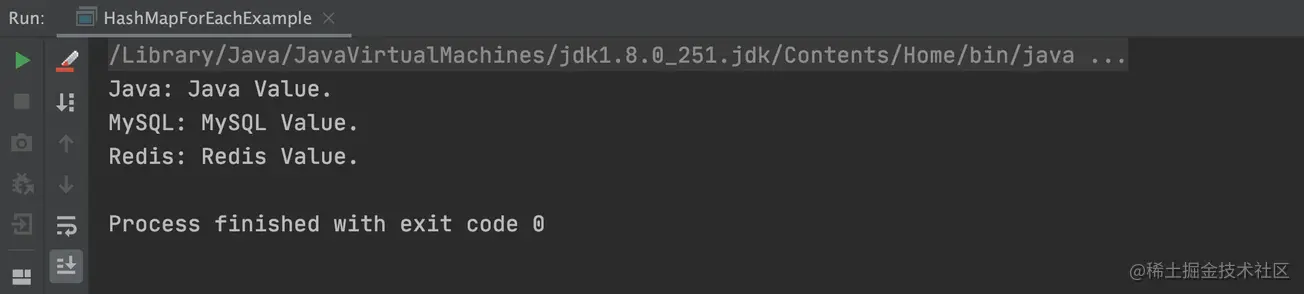
以上程序的执行结果,如下图所示:
1.2 KeySet 遍历
KeySet 的遍历方式是循环 Key 内容,再通过 map.get(key) 获取 Value 的值,具体实现如下:
public static void main(String[] args) {
// 创建并赋值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循环遍历
for (String key : map.keySet()) {
System.out.println(key + ":" + map.get(key));
}
}
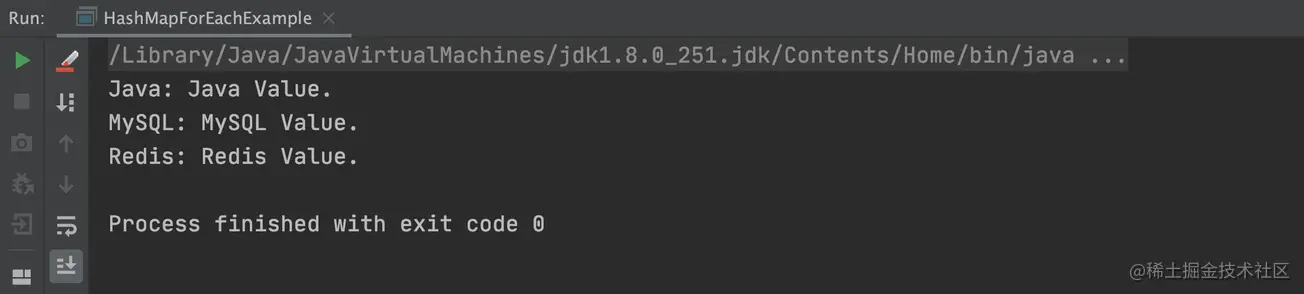
以上程序的执行结果,如下图所示:
2.KeySet 性能问题
通过以上代码,我们可以看出使用 KeySet 遍历,其性能是不如 EntrySet 的,因为 KeySet 其实循环了两遍集合,第一遍循环是循环 Key,而获取 Value 有需要使用 map.get(key),相当于有循环了一遍集合,所以 KeySet 循环不能建议使用,因为循环了两次,效率比较低。
2.1 EntrySet 迭代器遍历
EntrySet 和 KeySet 除了以上直接循环外,我们还可以使用它们的迭代器进行循环,
如 EntrySet 的迭代器实现代码如下:
public static void main(String[] args) {
// 创建并赋值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循环遍历
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
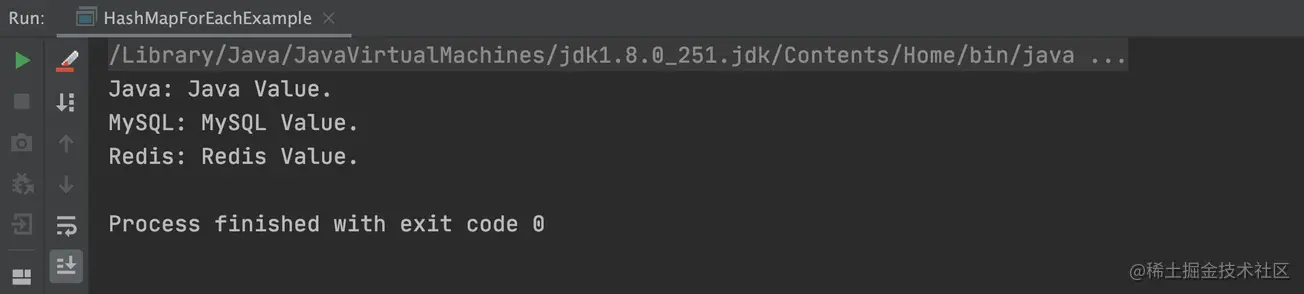
以上程序的执行结果,如下图所示:
2.2 KeySet 迭代器遍历
KeySet 也可以使用迭代器的方式进行遍历,实现代码如下:
public static void main(String[] args) {
// 创建并赋值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循环遍历
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
String key = iterator.next();
System.out.println(key + ":" + map.get(key));
}
}
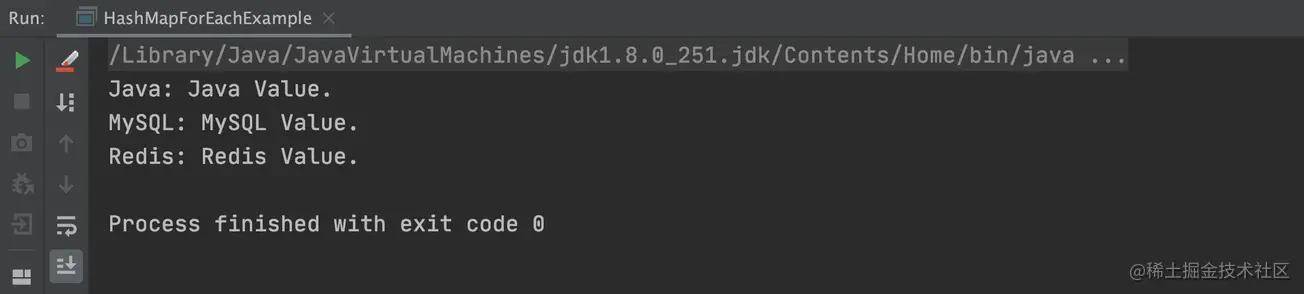
以上程序的执行结果,如下图所示:
虽然 KeySet 循环方式不推荐使用,但还是有必要了解一下的。
2.3 迭代器的作用
既然能直接遍历,那为什么还要用迭代器呢?通过以下例子我们就知道了。
2.4 不使用迭代器删除
如果不使用迭代器,假如我们在遍历 EntrySet 时,在遍历代码中删除元素,代码的实现如下:
public static void main(String[] args) {
// 创建并赋值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循环遍历
for (Map.Entry<String, String> entry : map.entrySet()) {
if ("Java".equals(entry.getKey())) {
// 删除此项
map.remove(entry.getKey());
continue;
}
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
以上程序的执行结果,如下图所示:

可以看到,如果在遍历的代码中动态删除元素,非迭代器的方式就会报错。
2.5 使用迭代器删除
接下来,我们使用迭代器循环 EntrySet,并且在循环中动态删除元素,实现代码如下:
public static void main(String[] args) {
// 创建并赋值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循环遍历
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
if ("Java".equals(entry.getKey())) {
// 删除此项
iterator.remove();
continue;
}
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
以上程序的执行结果,如下图所示:

从上述结果可以看出,使用迭代器的优点是可以在循环的时候,动态的删除集合中的元素。而上面非迭代器的方式则不能在循环的过程中删除元素(程序会报错)。
3.JDK 8 之后的遍历
在 JDK 8 之后 HashMap 的遍历就变得方便很多了,JDK 8 中包含了以下 3 种遍历方法:
- 使用 Lambda 遍历
- 使用 Stream 单线程遍历
- 使用 Stream 多线程遍历
我们分别来看。
3.1 Lambda 遍历
使用 Lambda 表达式的遍历方法实现代码如下:
public static void main(String[] args) {
// 创建并赋值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循环遍历
map.forEach((key, value) -> {
System.out.println(key + ":" + value);
});
}
以上程序的执行结果,如下图所示:
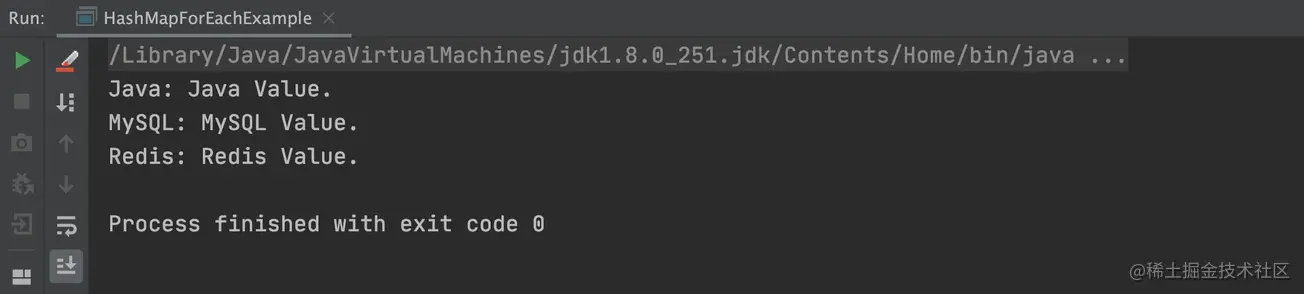
3.2 Stream 单线程遍历
Stream 遍历是先得到 map 集合的 EntrySet,然后再执行 forEach 循环,实现代码如下:
public static void main(String[] args) {
// 创建并赋值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循环遍历
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
}
以上程序的执行结果,如下图所示:

3.3 Stream 多线程遍历
Stream 多线程的遍历方式和上一种遍历方式类似,只是多执行了一个 parallel 并发执行的方法,此方法会根据当前的硬件配置生成对应的线程数,然后再进行遍历操作,
实现代码如下:
public static void main(String[] args) {
// 创建并赋值 hashmap
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
// 循环遍历
map.entrySet().stream().parallel().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
}
以上程序的执行结果,如下图所示:
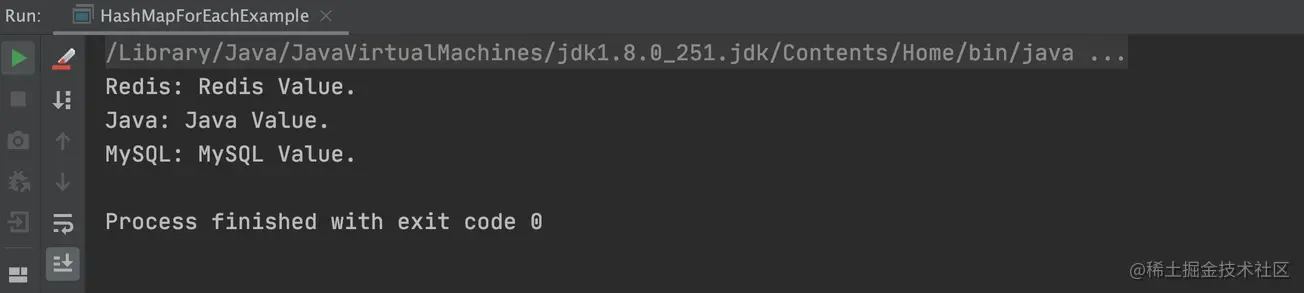
注意上述图片的执行结果,可以看出当前执行结果和之前的所有遍历结果都不一样(打印元素的顺序不一样),因为程序是并发执行的,所以没有办法保证元素的执行顺序和打印顺序,这就是并发编程的特点。
4.推荐使用哪种遍历方式?
不同的场景推荐使用的遍历方式是不同的,例如,如果是 JDK 8 之后的开发环境,推荐使用 Stream 的遍历方式,因为它足够简洁;而如果在遍历的过程中需要动态的删除元素,那么推荐使用迭代器的遍历方式;如果在遍历的时候,比较在意程序的执行效率,那么推荐使用 Stream 多线程遍历的方式,因为它足够快。所以这个问题的答案是不固定的,我们需要知道每种遍历方法的优缺点,再根据不同的场景灵活变通。
总结
本文介绍了 7 种 HashMap 的遍历方式,其中 JDK 8 之前主要使用 EntrySet 和 KeySet 的遍历方式,而 KeySet 的遍历方式性能比较低,一般不推荐使用。然而在 JDK 8 之后遍历方式就有了新的选择,可以使用比较简洁的 Lambda 遍历,也可以使用性能比较高的 Stream 多线程遍历。
到此这篇关于Java HashMap遍历方法汇总的文章就介绍到这了,更多相关HashMap方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java中的HashMap为什么会产生死循环
目录 前置知识 死循环执行步骤1 死循环执行步骤2 死循环执行步骤3 解决方案 总结 前言: HashMap 死循环是一个比较常见.比较经典的问题,在日常的面试中出现的频率比较高,所以接下来咱们通过图解的方式,带大家彻底理解死循环的原因. 前置知识 死循环问题发生在 JDK 1.7 版本中,造成这个问题主要是由于 HashMap 自身的运行机制,加上并发操作,从而导致了死循环. 在 JDK 1.7 中 HashMap 的底层数据实现是数组 + 链表的方式, 如下图所示: 而 HashMap
-
java 中的HashMap的底层实现和元素添加流程
目录 HashMap 底层实现 HashMap 插入流程 为什么要将链表转红黑树? 哈希算法实现 总结 前言: HashMap 是使用频率最高的数据类型之一,同时也是面试必问的问题之一,尤其是它的底层实现原理,既是常见的面试题又是理解 HashMap 的基石,所以重要程度不言而喻. HashMap 底层实现 HashMap 在 JDK 1.7 和 JDK 1.8 的底层实现是不一样的,在 JDK 1.7 中,HashMap 使用的是数组 + 链表实现的,而 JDK 1.8 中使用的是数组 + 链
-
Java HashMap中除了死循环之外的那些问题
目录 1.死循环问题 1.1 死循环执行流程一 1.2 死循环执行流程二 1.3 死循环执行流程三 1.4 解决方案 2.数据覆盖问题 2.1 数据覆盖执行流程一 2.2 数据覆盖执行流程二 2.3 数据覆盖执行流程三 2.4 解决方案 3.无序性问题 3.1 解决方案 总结 前言: 本篇的这个问题是一个开放性问题,HashMap 除了死循环之外,还有其他什么问题?总体来说 HashMap 的所有“问题”,都是因为使用(HashMap)不当才导致的,这些问题大致可以分为两类: 程序问题:比如 H
-
Java中HashMap 中的一个坑
目录 前言 问题展示 原因分析 解决方案 LinkedHashMap 的魔力 总结 前言 最近公司的系统要增加一个新的列表展示功能,功能本身难度并不大,但遇到了一个很“奇怪”的问题.小伙伴在执行查询列表时,明明已经使用了 order by 进行排序了,但最终查询出来的数据却还是乱的. 预期中的(正确)结果: 现实中的(非预期)结果: 那到底是哪里出现了问题呢? 问题展示 为了方便展示,我把复杂的业务程序简化成了以下代码: import java.util.HashMap; public c
-
Java详细分析讲解HashMap
目录 1.HashMap数据结构 2.HashMap特点 3.HashMap中put方法流程 java集合容器类分为Collection和Map两大类,Collection类的子接口有Set.List.Queue,Map类子接口有SortedMap.如ArrayList.HashMap的继承实现关系分别如下 1.HashMap数据结构 在jdk1.8中,底层数据结构是“数组+链表+红黑树”.HashMap其实底层实现还是数组,只是数组的每一项都是一条链,如下 当链表过长时,会严重影响HashMa
-
Java单例模式利用HashMap实现缓存数据
本文实例为大家分享了Java单例模式利用HashMap实现缓存数据的具体代码,供大家参考,具体内容如下 一.单例模式是什么? 单例模式是一种对象创建模式,它用于产生一个对象的具体实例,它可以确保系统中一个类只产生一个实例.Java 里面实现的单例是一个虚拟机的范围,因为装载类的功能是虚拟机的,所以一个虚拟机在通过自己的 ClassLoad 装载实现单例类的时候就会创建一个类的实例.在 Java 语言中,这样的行为能带来两大好处: 1.对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重
-
Java中HashMap如何解决哈希冲突
目录 1. Hash算法和Hash表 2. Hash冲突 3. 解决Hash冲突的方法有四种 4.HashMap在JDK1.8版本的优化 1. Hash算法和Hash表 了解Hash冲突首先了解Hash算法和Hash表 Hash算法就是把任意长度的输入通过散列算法变成固定长度的输出,这个输出结果就是一个散列值 Hash表又叫做“散列表”,它是通过key直接访问到内存存储位置的数据结构,在具体的实现上,我们通过Hash函数,把key映射到表中的某个位置,来获取这个位置的数据,从而加快数据的查找 2
-
Java实现HashMap排序方法的示例详解
目录 简介 排序已有数据 按key排序 按value排序 按插入顺序存放 HashMap不按插入顺序存放 LinkedHashMap会按照插入顺序存放 简介 本文用示例介绍HashMap排序的方法. 排序已有数据 按key排序 使用stream进行排序(按key升序/降序) package org.example.a; import java.util.*; public class Demo { public static void main(String[] args) { Map<Stri
-
Java HashMap遍历方法汇总
目录 1.JDK 8 之前的遍历 1.1 EntrySet 遍历 1.2 KeySet 遍历 2.KeySet 性能问题 2.1 EntrySet 迭代器遍历 2.2 KeySet 迭代器遍历 2.3 迭代器的作用 2.4 不使用迭代器删除 2.5 使用迭代器删除 3.JDK 8 之后的遍历 3.1 Lambda 遍历 3.2 Stream 单线程遍历 3.3 Stream 多线程遍历 4.推荐使用哪种遍历方式? 总结 前言: HashMap 的遍历方法有很多种,不同的 JDK 版本有不同的写法
-
Java读取文件方法汇总
本文实例为大家分享了Java读取文件的方法,供大家参考,具体内容如下 1.按字节读取文件内容 2.按字符读取文件内容 3.按行读取文件内容 4.随机读取文件内容 public class ReadFromFile { /** * 以字节为单位读取文件,常用于读二进制文件,如图片.声音.影像等文件. */ public static void readFileByBytes(String fileName) { File file = new File(fileName); InputStream
-
Java正则表达式工具方法汇总
1.获取某字符串中汉字的个数 ... private int getChineseCount(String text) { String Reg = "^[\u4e00-\u9fa5]{1}$";// 正则 int result = 0; for (int i = 0; i < text.length(); i++) { String b = Character.toString(text.charAt(i)); if (b.matches(Reg)) result++; } r
-
Java HashMap 如何正确遍历并删除元素的方法小结
(一)HashMap的遍历 HashMap的遍历主要有两种方式: 第一种采用的是foreach模式,适用于不需要修改HashMap内元素的遍历,只需要获取元素的键/值的情况. HashMap<K, V> myHashMap; for (Map.entry<K, V> item : myHashMap.entrySet()){ K key = item.getKey(); V val = item.getValue(); //todo with key and val //WARNI
-
基于HashMap遍历和使用方法(详解)
map的几种遍历方式: Map< String, String> map = new HashMap<>(); map.put("aa", "@sohu.com"); map.put("bb","@163.com"); map.put("cc", "@sina.com"); System.out.println("普通的遍历方法,通过Map.keySet
-
java实现遍历Map的方法
本文实例讲述了java实现遍历Map的方法.分享给大家供大家参考.具体如下: package com.yenange.test3; import java.util.HashMap; import java.util.Iterator; import java.util.Map; public class TestMap { public static void main(String[] args) { Map map=new HashMap(); map.put(1, 1); map.put
-
使用多种方式实现遍历HashMap的方法
今天讲解的主要是使用多种方式来实现遍历HashMap取出Key和value,首先在java中如果想让一个集合能够用for增强来实现迭代,那么此接口或类必须实现Iterable接口,那么Iterable究竟是如何来实现迭代的,在这里将不做讲解,下面主要讲解一下遍历过程. //定义一个泛型集合 Map<String, String> map = new HashMap<String, String>(); //通过Map的put方法向集合中添加数据 map.put("001&
-
java中关于Map的三种遍历方法详解
map的三种遍历方法!集合的一个很重要的操作---遍历,学习了三种遍历方法,三种方法各有优缺点~~ 复制代码 代码如下: /* * To change this template, choose Tools | Templates * and open the template in the editor. */package cn.tsp2c.liubao;import java.util.Collection;import java.util.HashMap;import java.util
-
Java中遍历Map的多种方法示例及优缺点总结
前言 关于java中的map遍历有多种方法,从最早的Iterator,到java5支持的foreach,再到java8 Lambda,让我们一起来看下具体的用法以及各自的优缺点 先初始化一个map public class TestMap { public static Map<Integer, Integer> map = new HashMap<Integer, Integer>(); } keySet values 如果只需要map的key或者value,用map的keySe
-
Java完全二叉树的创建与四种遍历方法分析
本文实例讲述了Java完全二叉树的创建与四种遍历方法.分享给大家供大家参考,具体如下: 有如下的一颗完全二叉树: 先序遍历结果应该为:1 2 4 5 3 6 7 中序遍历结果应该为:4 2 5 1 6 3 7 后序遍历结果应该为:4 5 2 6 7 3 1 层序遍历结果应该为:1 2 3 4 5 6 7 二叉树的先序遍历.中序遍历.后序遍历其实都是一样的,都是执行递归操作. 我这记录一下层次遍历吧:层次遍历需要用到队列,先入队在出队,每次出队的元素