深入Golang的接口interface
目录
- 前言
- 接口转换的原理
- 实现多态
前言
go不要求类型显示地声明实现了哪个接口,只要实现了相关的方法即可,编译器就能检测到
空接口类型可以接收任意类型的数据:
type eface struct {
// _type 指向接口的动态类型元数据
// 描述了实体类型、包括内存对齐方式、大小等
_type *_type
// data 指向接口的动态值
data unsafe.Pointer
}
空接口在赋值时,_type 和 data 都是nil。赋值后,_type 会指向赋值的数据元类型,data 会指向该值
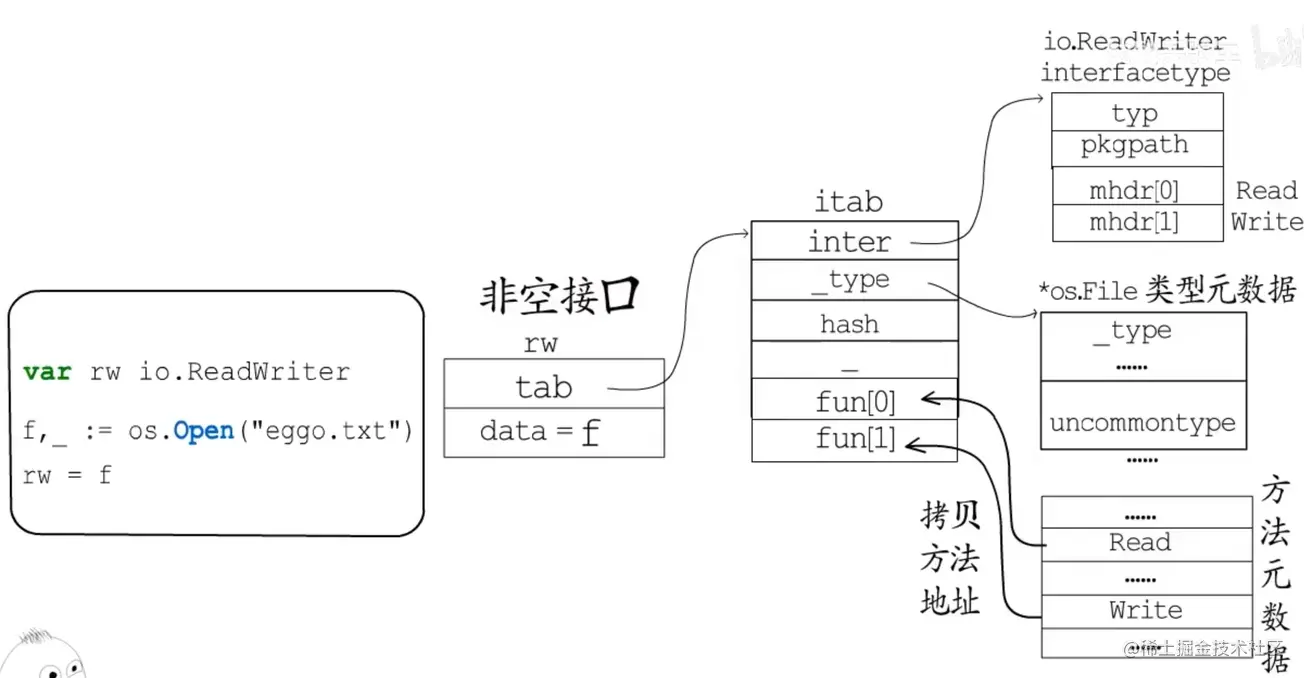
非空接口是有方法列表的接口类型,一个变量要赋值给非空接口,就要实现该接口里的所有方法
type iface struct {
// tab 接口表指针,指向一个itab实体,存储方法列表和接口动态类型信息
tab *itab
// data 指向接口的动态值(一般是指向堆内存的)
data unsafe.Pointer
}
// layout of Itab known to compilers
// allocated in non-garbage-collected memory
// Needs to be in sync with
// ../cmd/compile/internal/gc/reflect.go:/^func.dumptabs.
type itab struct {
// inter 指向interface的类型元数据,描述了接口的类型
inter *interfacetype
// _type 描述了实体类型、包括内存对齐方式、大小等
_type *_type
// hash 从动态类型元数据中拷贝的hash值,用于快速判断类型是否相等
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
// fun 记录动态类型实现的那些接口方法的地址
// 存储的是第一个方法的函数指针
// 这些方法是按照函数名称的字典序进行排列的
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}
// interfacetype 接口的类型元数据
type interfacetype struct {
typ _type
// 记录定义了接口的包名
pkgpath name
// mhdr 标识接口所定义的函数列表
mhdr []imethod
}
itab是可复用的,go会将itab缓存起来,构造一个hash表用于查出和查询缓存信息<接口类型, 动态类型>
如果itab缓存中有,可以直接拿来使用,如果没有,则新创建一个itab,并放入缓存中
一个Iface中的具体类型中实现的方法会被拷贝到Itab的fun数组中
// Note: change the formula in the mallocgc call in itabAdd if you change these fields.
type itabTableType struct {
size uintptr // length of entries array. Always a power of 2.
count uintptr // current number of filled entries.
entries [itabInitSize]*itab // really [size] large
}
func itabHashFunc(inter *interfacetype, typ *_type) uintptr {
// compiler has provided some good hash codes for us.
// 用接口类型hash和动态类型hash进行异或
return uintptr(inter.typ.hash ^ typ.hash)
}
接口类型和nil作比较
接口值的零值指接口动态类型和动态值都为nil,当且仅当此时接口值==nil
如何打印出接口的动态类型和值?
定义一个iface结构体,用两个指针来描述itab和data,然后将具体遍历在内存中的内容强行解释为我们定义的iface
type iface struct{
itab, data uintptr
}
func main() {
var a interface{} = nil
var b interface{} = (*int)(nil)
x := 5
var c interface{} = (*int)(&x)
ia := *(*iface)(unsafe.Pointer(&a))
ib := *(*iface)(unsafe.Pointer(&b))
ic := *(*iface)(unsafe.Pointer(&c))
fmt.Println(ia, ib, ic)
fmt.Println(*(*int)(unsafe.Pointer(ic.data)))
}
// 输出
// {0 0} {17426912 0} {17426912 842350714568}
// 5
检测类型是否实现了接口:
赋值语句会发生隐式的类型转换,在转换过程中,编译器会检测等号右边的类型是否实现了等号左边接口所规定的函数
// 检查 *myWriter 类型是否实现了 io.Writer 接口
var _ io.Writer = (*myWriter)(nil)
// 检查 myWriter 类型是否实现了 io.Writer 接口
var _ io.Writer = myWriter{}
接口转换的原理
将一个接口转换为另一个接口:
- 实际上是调用了convI2I
- 如果目标是空接口或和目标接口的inter一样就直接返回
- 否则去获取itab,然后将值data赋入,再返回
// 接口间的赋值实际上是调用了runtime.convI2I
// 实际上是要找到新interface的tab和data
// convI2I returns the new itab to be used for the destination value
// when converting a value with itab src to the dst interface.
func convI2I(dst *interfacetype, src *itab) *itab {
if src == nil {
return nil
}
if src.inter == dst {
return src
}
return getitab(dst, src._type, false)
}
// 关键函数,获取itab
// getitab根据interfacetype和_type去全局的itab哈希表中查找,如果找到了直接返回
// 否则根据inter和typ新生成一个itab,插入到全局itab哈希表中
//
// 查找了两次,第二次上锁了,目的是可能会写入hash表,阻塞其余协程的第二次查找
func getitab(inter *interfacetype, typ *_type, canfail bool) *itab {
// 函数列表为空
if len(inter.mhdr) == 0 {
throw("internal error - misuse of itab")
}
// easy case
if typ.tflag&tflagUncommon == 0 {
if canfail {
return nil
}
name := inter.typ.nameOff(inter.mhdr[0].name)
panic(&TypeAssertionError{nil, typ, &inter.typ, name.name()})
}
var m *itab
// First, look in the existing table to see if we can find the itab we need.
// This is by far the most common case, so do it without locks.
// Use atomic to ensure we see any previous writes done by the thread
// that updates the itabTable field (with atomic.Storep in itabAdd).
// 使用原子性去保证我们能看见在该线程之前的任意写操作
// 确保更新全局hash表的字段
t := (*itabTableType)(atomic.Loadp(unsafe.Pointer(&itabTable)))
// 遍历一次,找到了就返回
if m = t.find(inter, typ); m != nil {
goto finish
}
// 没找到就上锁,再试一次
// Not found. Grab the lock and try again.
lock(&itabLock)
if m = itabTable.find(inter, typ); m != nil {
unlock(&itabLock)
goto finish
}
// hash表中没找到itab就新生成一个itab
// Entry doesn't exist yet. Make a new entry & add it.
m = (*itab)(persistentalloc(unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*goarch.PtrSize, 0, &memstats.other_sys))
m.inter = inter
m._type = typ
// The hash is used in type switches. However, compiler statically generates itab's
// for all interface/type pairs used in switches (which are added to itabTable
// in itabsinit). The dynamically-generated itab's never participate in type switches,
// and thus the hash is irrelevant.
// Note: m.hash is _not_ the hash used for the runtime itabTable hash table.
m.hash = 0
m.init()
// 加到全局的hash表中
itabAdd(m)
unlock(&itabLock)
finish:
if m.fun[0] != 0 {
return m
}
if canfail {
return nil
}
// this can only happen if the conversion
// was already done once using the , ok form
// and we have a cached negative result.
// The cached result doesn't record which
// interface function was missing, so initialize
// the itab again to get the missing function name.
panic(&TypeAssertionError{concrete: typ, asserted: &inter.typ, missingMethod: m.init()})
}
// 查找全局的hash表,有没有itab
// find finds the given interface/type pair in t.
// Returns nil if the given interface/type pair isn't present.
func (t *itabTableType) find(inter *interfacetype, typ *_type) *itab {
// Implemented using quadratic probing.
// Probe sequence is h(i) = h0 + i*(i+1)/2 mod 2^k.
// We're guaranteed to hit all table entries using this probe sequence.
mask := t.size - 1
// 根据inter,typ算出hash值
h := itabHashFunc(inter, typ) & mask
for i := uintptr(1); ; i++ {
p := (**itab)(add(unsafe.Pointer(&t.entries), h*goarch.PtrSize))
// Use atomic read here so if we see m != nil, we also see
// the initializations of the fields of m.
// m := *p
m := (*itab)(atomic.Loadp(unsafe.Pointer(p)))
if m == nil {
return nil
}
// inter和typ指针都相同
if m.inter == inter && m._type == typ {
return m
}
h += i
h &= mask
}
}
// 核心函数。填充itab
// 检查_type是否符合interface_type并且创建对应的itab结构体将其放到hash表中
// init fills in the m.fun array with all the code pointers for
// the m.inter/m._type pair. If the type does not implement the interface,
// it sets m.fun[0] to 0 and returns the name of an interface function that is missing.
// It is ok to call this multiple times on the same m, even concurrently.
func (m *itab) init() string {
inter := m.inter
typ := m._type
x := typ.uncommon()
// both inter and typ have method sorted by name,
// and interface names are unique,
// so can iterate over both in lock step;
// the loop is O(ni+nt) not O(ni*nt).
// inter和typ的方法都按方法名称进行排序
// 并且方法名是唯一的,因此循环次数的固定的
// 复杂度为O(ni+nt),而不是O(ni*nt)
ni := len(inter.mhdr)
nt := int(x.mcount)
xmhdr := (*[1 << 16]method)(add(unsafe.Pointer(x), uintptr(x.moff)))[:nt:nt]
j := 0
methods := (*[1 << 16]unsafe.Pointer)(unsafe.Pointer(&m.fun[0]))[:ni:ni]
var fun0 unsafe.Pointer
imethods:
for k := 0; k < ni; k++ {
i := &inter.mhdr[k]
itype := inter.typ.typeOff(i.ityp)
name := inter.typ.nameOff(i.name)
iname := name.name()
ipkg := name.pkgPath()
if ipkg == "" {
ipkg = inter.pkgpath.name()
}
// 第二层循环是从上一次遍历到的位置开始的
for ; j < nt; j++ {
t := &xmhdr[j]
tname := typ.nameOff(t.name)
// 检查方法名字是否一致
if typ.typeOff(t.mtyp) == itype && tname.name() == iname {
pkgPath := tname.pkgPath()
if pkgPath == "" {
pkgPath = typ.nameOff(x.pkgpath).name()
}
if tname.isExported() || pkgPath == ipkg {
if m != nil {
// 获取函数地址,放入itab.func数组中
ifn := typ.textOff(t.ifn)
if k == 0 {
fun0 = ifn // we'll set m.fun[0] at the end
} else {
methods[k] = ifn
}
}
continue imethods
}
}
}
// didn't find method
m.fun[0] = 0
return iname
}
m.fun[0] = uintptr(fun0)
return ""
}
// 检查是否需要扩容,并调用方法将itab存入
// itabAdd adds the given itab to the itab hash table.
// itabLock must be held.
func itabAdd(m *itab) {
// Bugs can lead to calling this while mallocing is set,
// typically because this is called while panicing.
// Crash reliably, rather than only when we need to grow
// the hash table.
if getg().m.mallocing != 0 {
throw("malloc deadlock")
}
t := itabTable
// 检查是否需要扩容
if t.count >= 3*(t.size/4) { // 75% load factor
// Grow hash table.
// t2 = new(itabTableType) + some additional entries
// We lie and tell malloc we want pointer-free memory because
// all the pointed-to values are not in the heap.
t2 := (*itabTableType)(mallocgc((2+2*t.size)*goarch.PtrSize, nil, true))
t2.size = t.size * 2
// Copy over entries.
// Note: while copying, other threads may look for an itab and
// fail to find it. That's ok, they will then try to get the itab lock
// and as a consequence wait until this copying is complete.
iterate_itabs(t2.add)
if t2.count != t.count {
throw("mismatched count during itab table copy")
}
// Publish new hash table. Use an atomic write: see comment in getitab.
atomicstorep(unsafe.Pointer(&itabTable), unsafe.Pointer(t2))
// Adopt the new table as our own.
t = itabTable
// Note: the old table can be GC'ed here.
}
// 核心函数
t.add(m)
}
// 核心函数
// add adds the given itab to itab table t.
// itabLock must be held.
func (t *itabTableType) add(m *itab) {
// See comment in find about the probe sequence.
// Insert new itab in the first empty spot in the probe sequence.
// 在探针序列第一个空白点插入itab
mask := t.size - 1
// 计算hash值
h := itabHashFunc(m.inter, m._type) & mask
for i := uintptr(1); ; i++ {
p := (**itab)(add(unsafe.Pointer(&t.entries), h*goarch.PtrSize))
m2 := *p
if m2 == m {
// itab已被插入
// A given itab may be used in more than one module
// and thanks to the way global symbol resolution works, the
// pointed-to itab may already have been inserted into the
// global 'hash'.
return
}
if m2 == nil {
// Use atomic write here so if a reader sees m, it also
// sees the correctly initialized fields of m.
// NoWB is ok because m is not in heap memory.
// *p = m
// 使用原子操作确保其余的goroutine下次查找的时候可以看到他
atomic.StorepNoWB(unsafe.Pointer(p), unsafe.Pointer(m))
t.count++
return
}
h += i
h &= mask
}
}
// hash函数,编译期间提供较好的hash codes
func itabHashFunc(inter *interfacetype, typ *_type) uintptr {
// compiler has provided some good hash codes for us.
return uintptr(inter.typ.hash ^ typ.hash)
}
具体类型转空接口时,_type 字段直接复制源类型的 _type;调用 mallocgc 获得一块新内存,把值复制进去,data 再指向这块新内存。
具体类型转非空接口时,入参 tab 是编译器在编译阶段预先生成好的,新接口 tab 字段直接指向入参 tab 指向的 itab;调用 mallocgc 获得一块新内存,把值复制进去,data 再指向这块新内存。
而对于接口转接口,itab 调用 getitab 函数获取。只用生成一次,之后直接从 hash 表中获取。
实现多态
- 多态的特点
- 一种类型具有多种类型的能力
- 允许不同的对象对同一消息做出灵活的反应
- 以一种通用的方式对待多个使用的对象
- 非动态语言必须通过继承和接口的方式实现
实现函数的内部,接口绑定了实体类型,会直接调用fun里保存的函数,类似于s.tab->fun[0],而fun数组中保存的是实体类型实现的函数,当函数传入不同实体类型时,实际上调用的是不同的函数实现,从而实现了多态
到此这篇关于深入Golang的接口interface的文章就介绍到这了,更多相关Go 接口 interface内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
golang基础之Interface接口的使用
接口是一个或多个方法签名名的集合,定义方式如下 type Interface_Name interface { method_a() string method_b() int .... } 只要某个类型拥有该接口的所有方法签名,就算实现该接口,无需显示声明实现了那个接口,这称为structural Typing package main import "fmt" type USB interface { //定义一个接口:方法的集合 Name() string //Name方法,返回
-

golang中interface接口的深度解析
一 接口介绍 如果说gorountine和channel是支撑起Go语言的并发模型的基石,让Go语言在如今集群化与多核化的时代成为一道亮丽的风景,那么接口是Go语言整个类型系列的基石,让Go语言在基础编程哲学的探索上达到前所未有的高度.Go语言在编程哲学上是变革派,而不是改良派.这不是因为Go语言有gorountine和channel,而更重要的是因为Go语言的类型系统,更是因为Go语言的接口.Go语言的编程哲学因为有接口而趋于完美.C++,Java 使用"侵入式"接口,主要表现在实现
-
深入Golang的接口interface
目录 前言 接口转换的原理 实现多态 前言 go不要求类型显示地声明实现了哪个接口,只要实现了相关的方法即可,编译器就能检测到 空接口类型可以接收任意类型的数据: type eface struct { // _type 指向接口的动态类型元数据 // 描述了实体类型.包括内存对齐方式.大小等 _type *_type // data 指向接口的动态值 data unsafe.Pointer } 空接口在赋值时,_type 和 data 都是nil.赋值后,_type 会指向赋值的数据元类型,d
-
浅谈Go语言中的结构体struct & 接口Interface & 反射
结构体struct struct 用来自定义复杂数据结构,可以包含多个字段(属性),可以嵌套: go中的struct类型理解为类,可以定义方法,和函数定义有些许区别: struct类型是值类型. struct定义 type User struct { Name string Age int32 mess string } var user User var user1 *User = &User{} var user2 *User = new(User) struct使用 下面示例中user1和
-
Golang 使用接口实现泛型的方法示例
在C/C++中我们可以使用泛型的方法使代码得以重复使用,最常见例如stl functions:vector<int> vint or vector<float> vfloat等.这篇文章将使用interface{...}接口使Golang实现泛型. interface{...}是实现泛型的基础.如一个数组元素类型是interface{...}的话,那么实现了该接口的实体都可以被放置入数组中.注意其中并不一定必须是空接口(简单类型我们可以通过把他转化为自定义类型后实现接口).为什么i
-
golang中接口对象的转型两种方式
接口对象的转型有两种方式: 1. 方式一:instance,ok:=接口对象.(实际类型) 如果该接口对象是对应的实际类型,那么instance就是转型之后对象,ok的值为true 配合if...else if...使用 2. 方式二: 接口对象.(type) 配合switch...case语句使用 示例: package main import ( "fmt" "math" ) type shape interface { perimeter() int area
-
从零开始学Golang的接口
目录 前言 1.为什么需要接口? 2.接口是什么?如何定义? 3.接口实战初体验 4.如何测试是否已实现该接口? 5.空接口&类型断言 6.接口零值 7.一个类型实现多个接口 8.指针与值类型实现接口的区别 9.接口嵌套 前言 接口在面向对象编程中是经常使用的招式,也是体现多态很重要的手段.是的.Golang中也有接口这玩意儿. 1.为什么需要接口? 多数情况下,数据可能包含不同的类型,却会有一个或者多个共同点,这些共同点就是抽象的基础.前文讲到的Golang继承解决的是is-a的问题,单一继承
-
深入解析Java接口(interface)的使用
Java接口(interface)的概念及使用 在抽象类中,可以包含一个或多个抽象方法:但在接口(interface)中,所有的方法必须都是抽象的,不能有方法体,它比抽象类更加"抽象". 接口使用 interface 关键字来声明,可以看做是一种特殊的抽象类,可以指定一个类必须做什么,而不是规定它如何去做. 现实中也有很多接口的实例,比如说串口电脑硬盘,Serial ATA委员会指定了Serial ATA 2.0规范,这种规范就是接口.Serial ATA委员会不负责生产硬盘,只是指定
-
C#接口(Interface)用法分析
本文实例分析了C#接口(Interface)用法.分享给大家供大家参考.具体分析如下: 继承"基类"跟继承"接口"都能实现某些相同的功能,但有些接口能够完成的功能是只用基类无法实现的 1.接口用于描述一组类的公共方法/公共属性. 它不实现任何的方法或属性,只是告诉继承它的类至少要实现哪些功能,继承它的类可以增加自己的方法. 2.使用接口可以使继承它的类: 命名统一/规范,易于维护.比如: 两个类 "狗"和"猫",如果它们都继承
-
C#接口interface用法实例
本文实例讲述了C#接口interface用法.分享给大家供大家参考.具体如下: using System; //example of interfaces public class Animals { //simple interface interface IAnimal { void Breathes(); } //interfaces can inherent from other interfaces interface IMammal : IAnimal { int HairLengt
-
C#中接口(Interface)的深入详解
定义 在 C# 语言中,类之间的继承关系仅支持单重继承,而接口是为了实现多重继承关系设计的.一个类能同时实现多个接口,还能在实现接口的同时再继承其他类,并且接口之间也可以继承.无论是表示类之间的继承还是类实现接口.接口之间的继承,都使用":"来表示. 接口定义了属性.方法和事件,这些都是接口的成员.接口只包含了成员的声明.成员的定义是派生类的责任.接口提供了派生类应遵循的标准结构.接口定义了语法合同 "是什么" 部分,派生类定义了语法合同 "怎么做&quo
-
TypeScript定义接口(interface)案例教程
接口的作用: 接口,英文:interface,其作用可以简单的理解为:为我们的代码提供一种约定. 在Typescript中是这么描述的: TypeScript的核心原则之一是对值所具有的结构进行类型检查.它有时被称做"鸭式辨型法"或"结构性子类型化". 在TypeScript里,接口的作用就是为这些类型命名和为你的代码或第三方代码定义契约. 举个例子: // 定义接口 Person interface Person { name: string; age: numb