Spring如何解决循环依赖的问题
前言
在面试的时候这两年有一个非常高频的关于spring的问题,那就是spring是如何解决循环依赖的。这个问题听着就是轻描淡写的一句话,其实考察的内容还是非常多的,主要还是考察的应聘者有没有研究过spring的源码。但是说实话,spring的源码其实非常复杂的,研究起来并不是个简单的事情,所以我们此篇文章只是为了解释清楚Spring是如何解决循环依赖的这个问题。
什么样的依赖算是循环依赖?
用过Spring框架的人都对依赖注入这个词不陌生,一个Java类A中存在一个属性是类B的一个对象,那么我们就说类A的对象依赖类B,而在Spring中是依靠的IOC来实现的对象注入,也就是说创建对象的过程是IOC容器来实现的,并不需要自己在使用的时候通过new关键字来创建对象。
那么当类A中依赖类B的对象,而类B中又依赖类C的对象,最后类C中又依赖类A的对象的时候,这种情况最终的依赖关系会形成一个环,这就是循环依赖。
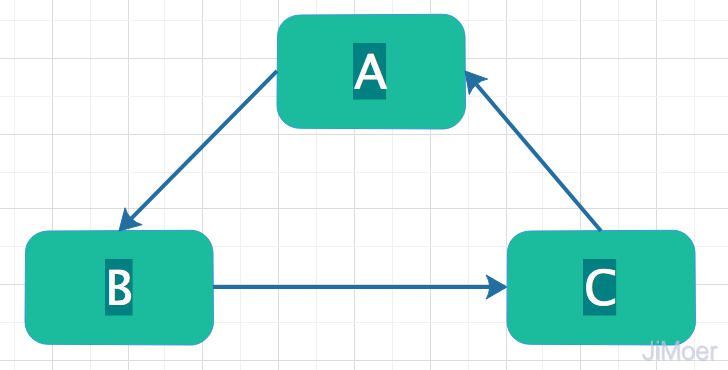
循环依赖的类型
根据注入的时机可以分为两种:
构造器循环依赖
依赖的对象是通过构造方法传入的,在实例化bean的时候发生。
赋值属性循环依赖
依赖的对象是通过setter方法传入的,对象已经实例化,在属性赋值和依赖注入的时候发生。
构造器循环依赖,本质上是无解的,实例化A的时候调用A的构造器,发现依赖了B,又去实例化B,然后调用B的构造器,发现又依赖的C,然后调用C的构造器去实例化,结果发起C的构造器里依赖了A,这就是个死循环无解。所以Spring也是不支持构造器循环依赖的,当发现存在构造器循环依赖时,会直接抛出BeanCurrentlyInCreationException 异常。
赋值属性循环依赖,Spring只支持bean在单例模式下的循环依赖,其他模式下的循环依赖Spring也是会抛出BeanCurrentlyInCreationException 异常的。Spring通过对还在创建过程中的单例bean,进行缓存并提前暴露该单例,使得其他实例可以提前引用到该单例bean。
Spring为什么只支持单例模式下的bean的赋值情况下的循环依赖
在prototype的模式下的bean,使用了一个ThreadLocal变量prototypesCurrentlyInCreation来记录当前线程正在创建中的bean,这个变量在AbtractBeanFactory类里。在创建前用beanName记录bean,在创建完成后删除bean。在prototypesCurrentlyInCreation里采用了一个Set对象来存储正在创建中的bean。我们都知道Set是不允许存在重复对象的,这样就能保证同一个bean在一个线程中只能有一个正在创建。
下面是prototypesCurrentlyInCreation变量在删除bean时的操作,在AbtractBeanFactory的beforePrototypeCreation操作里。
protected void afterPrototypeCreation(String beanName) {
Object curVal = this.prototypesCurrentlyInCreation.get();
if (curVal instanceof String) {
this.prototypesCurrentlyInCreation.remove();
}
else if (curVal instanceof Set) {
Set<String> beanNameSet = (Set<String>) curVal;
beanNameSet.remove(beanName);
if (beanNameSet.isEmpty()) {
this.prototypesCurrentlyInCreation.remove();
}
}
}
从上面的代码中看出,当变量为一个的时候采用了一个String对象来存储,节省了一些内存空间。
在AbstractBeanFactory类的doGetBean方法里先判断是否为单例对象,不是单例对象,则直接判断当前线程是否已经存在了正在创建的bean。存在的话直接抛出异常。
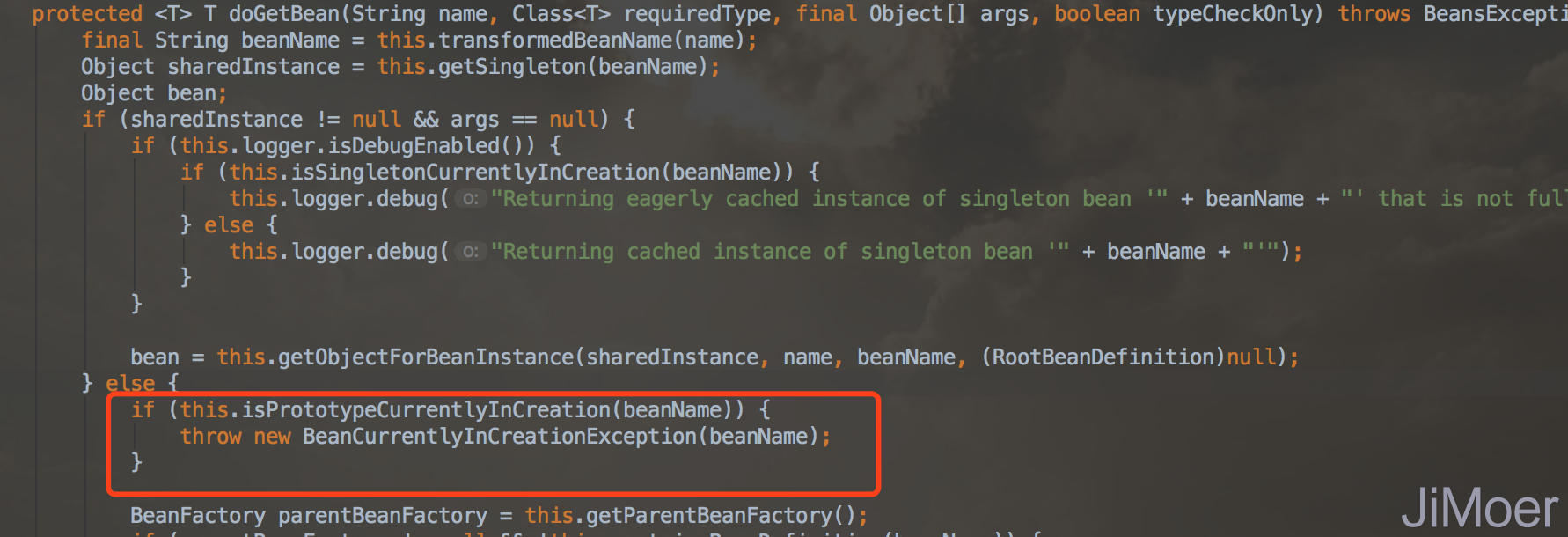
这个isPrototypeCurrentlyInCreation()方法的实现代码如下:
protected boolean isPrototypeCurrentlyInCreation(String beanName) {
Object curVal = this.prototypesCurrentlyInCreation.get();
return curVal != null && (curVal.equals(beanName) || curVal instanceof Set && ((Set)curVal).contains(beanName));
}
因为有了这个机制,spring在原型模式下是解决不了bean的循环依赖的,当发现有循环依赖的时候会直接抛出BeanCurrentlyInCreationException异常的。
那么为什么spring在单例模式下的构造赋值也不支持循环依赖呢?
其实原理和原型模式下的情况类似,在单例模式下,bean也会用一个Set集合来保存正在创建中的bean,在创建前保存,创建完成后删除。
这个对象在DefaultSingletonBeanRegistry类下变量名为:singletonsCurrentlyInCreation
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
private final Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap(16));
}
判定代码在DefaultSingletonBeanRegistry类的beforeSingletonCreation方法下。
protected void beforeSingletonCreation(String beanName) {
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}
在上面这个方法中,判定singletonsCurrentlyInCreation是否能成功的保存一个单例bean。如果不能成功保存,那么就会直接抛出BeanCurrentlyInCreationException异常。
单例模式下的Setter赋值循环依赖
终于到了我们的重点,Spring是如何解决单例模式下的Setter赋值的循环依赖了。
其实主要的就是靠提前暴露创建中的单例实例。
那么具体是一个怎样的过程呢?
例如:上面那个图的例子,A依赖B,B依赖C,C又依赖B。
过程如下:
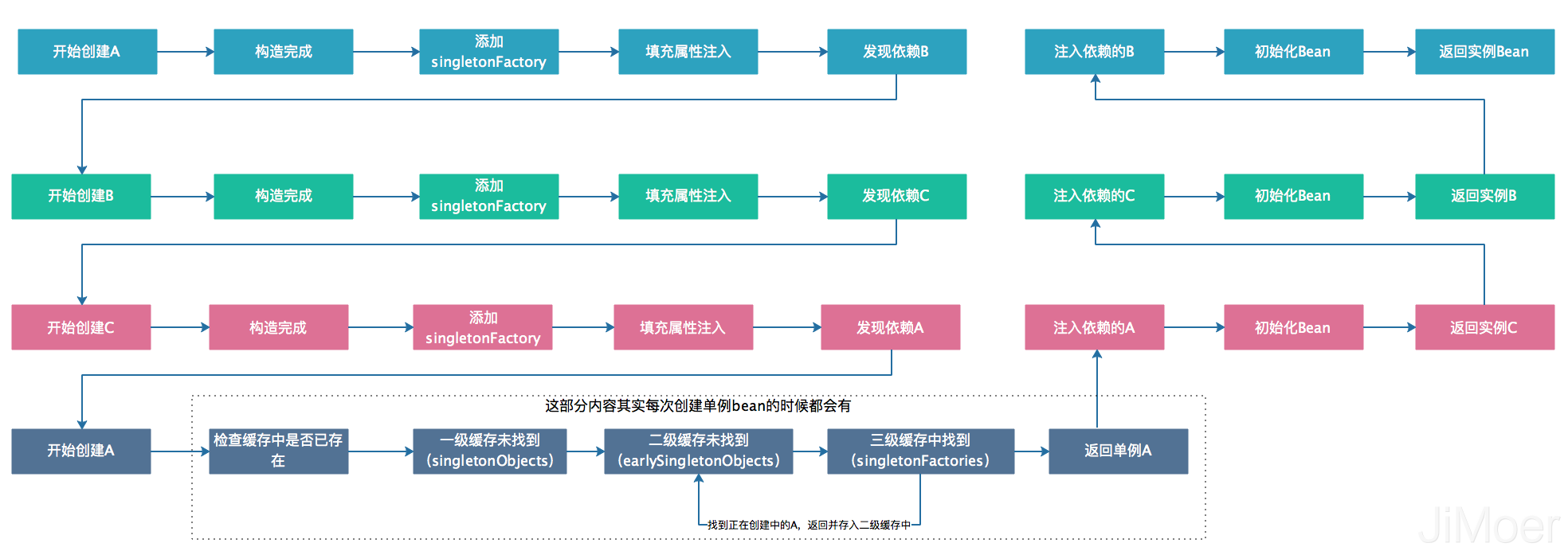
创建A,调用构造方法,完成构造,进行属性赋值注入,发现依赖B,去实例化B。创建B,调用构造方法,完成构造,进行属性赋值注入,发现依赖C,去实例化C。
创建C,调用构造方法,完成构造,进行属性赋值注入,发现依赖A。
这个时候就是解决循环依赖的关键了,因为A已经通过构造方法已经构造完成了,也就是说已经将Bean的在堆中分配好了内存,这样即使A再填充属性值也不会更改内存地址了,所以此时可以提前拿出来A的引用,来完成C的实例化。
这样上面创建C过程就会变成了:
创建C,调用构造方法,完成构造,进行属性赋值注入,发现依赖A,A已经构造完成,直接引用,完成C的实例化。C完成实例化后,注入B,B也完成了实例化,然后B注入A,A也完成了实例化。
为了能获取到创建中单例bean,spring提供了三级缓存来将正在创建中的bean提前暴露。
在类DefaultSingletonBeanRegistry下,即下图红框中的三个Map对象。

这三个缓存Map的作用如下:
- 一级缓存,
singletonObjects单例缓存,存储已经实例化的单例bean。 - 二级缓存,
earlySingletonObjects提前暴露的单例缓存,这里存储的bean是刚刚构造完成,但还会通过属性注入bean。 - 三级缓存,
singletonFactories生产单例的工厂缓存,存储工厂。
首先在创建bean的时候会先创建一个和bean同名的单例工厂,并将bean先放入到单例工厂中。代码在AbstractAutowireCapableBeanFactory类的doCreateBean方法中。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, Object[] args) throws BeanCreationException {
......
this.addSingletonFactory(beanName, new ObjectFactory<Object>() {
public Object getObject() throws BeansException {
return AbstractAutowireCapableBeanFactory.this.getEarlyBeanReference(beanName, mbd, bean);
}
});
.....
}
而上面的代码中的addSingletonFactory方法的代码如下:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
Map var3 = this.singletonObjects;
synchronized(this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
addSingletonFactory方法的作用通过代码就可以看到是将存在了正在创建中的bean的单例工厂,放在三级缓存里,这样保证了在循环依赖查找的时候是可以找到bean的引用的。
具体读取缓存获取bean的过程在类DefaultSingletonBeanRegistry的getSingleton方法里。
如下源码:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {
Map var4 = this.singletonObjects;
synchronized(this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject != NULL_OBJECT ? singletonObject : null;
}
通过上面的源码我们可以看到,在获取单例Bean的时候,会先从一级缓存singletonObjects里获取,如果没有获取到(说明不存在或没有实例化完成),会去第二级缓存earlySingletonObjects中去找,如果还是没有找到的话,就会三级缓存中获取单例工厂singletonFactory,通过从singletonFactory中获取正在创建中的引用,将singletonFactory存储在earlySingletonObjects 二级缓存中,这样就将创建中的单例引用从三级缓存中升级到了二级缓存中,二级缓存earlySingletonObjects,是会提前暴露已完成构造,还可以执行属性注入的单例bean的。
这个时候如何还有其他的bean也是需要属性注入,那么就可以直接从earlySingletonObjects中获取了。
上面的例子中的过程中的A,在注入C的时候,其实并没有真正的初始化完成,等到顺利的注入了B才算是真正的初始化完成。
整个过程如下图:
总结
到此这篇关于Spring如何解决循环依赖的问题的文章就介绍到这了,更多相关Spring解决循环依赖内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

浅谈Spring解决循环依赖的三种方式
引言:循环依赖就是N个类中循环嵌套引用,如果在日常开发中我们用new 对象的方式发生这种循环依赖的话程序会在运行时一直循环调用,直至内存溢出报错.下面说一下Spring是如果解决循环依赖的. 第一种:构造器参数循环依赖 表示通过构造器注入构成的循环依赖,此依赖是无法解决的,只能抛出BeanCurrentlyIn CreationException异常表示循环依赖. 如在创建TestA类时,构造器需要TestB类,那将去创建TestB,在创建TestB类时又发现需要TestC类,则又去创建Test
-
详解Spring Bean的循环依赖解决方案
如果使用构造函数注入,则可能会创建一个无法解析的循环依赖场景. 什么是循环依赖 循环依赖其实就是循环引用,也就是两个或则两个以上的bean互相持有对方,最终形成闭环.比如A依赖于B,B依赖于C,C又依赖于A.如下图: 注意,这里不是函数的循环调用,是对象的相互依赖关系.循环调用其实就是一个死循环,除非有终结条件. Spring中循环依赖场景有: (1)构造器的循环依赖 (2)field属性的循环依赖. 怎么检测是否存在循环依赖 检测循环依赖相对比较容易,Bean在创建的时候可以给该Bean打标,
-
Spring循环依赖正确性及Bean注入的顺序关系详解
一.前言 我们知道 Spring 可以是懒加载的,就是当真正使用到 Bean 的时候才实例化 Bean.当然也不全是这样,例如配置 Bean 的 lazy-init 属性,可以控制 Spring 的加载时机.现在机器的性能.内存等都比较高,基本上也不使用懒加载,在容器启动时候来加载bean,启动时间稍微长一点儿,这样在实际获取 bean 供业务使用时,就可以减轻不少负担,这个后面再做分析. 我们使用到 Bean 的时候,最直接的方式就是从 Factroy 中获取,这个就是加载 Bean 实例的源
-
详解Spring循环依赖的解决方案
spring针对Bean之间的循环依赖,有自己的处理方案.关键点就是三级缓存.当然这种方案不能解决所有的问题,他只能解决Bean单例模式下非构造函数的循环依赖. 我们就从A->B->C-A这个初始化顺序,也就是A的Bean中需要B的实例,B的Bean中需要C的实例,C的Bean中需要A的实例,当然这种需要不是构造函数那种依赖.前提条件有了,我们就可以开始了.毫无疑问,我们会先初始化A.初始化的方法是org.springframework.beans.factory.support.Abstra
-
Spring循环依赖的三种方式(推荐)
引言:循环依赖就是N个类中循环嵌套引用,如果在日常开发中我们用new 对象的方式发生这种循环依赖的话程序会在运行时一直循环调用,直至内存溢出报错.下面说一下spring是如果解决循环依赖的. 第一种:构造器参数循环依赖 Spring容器会将每一个正在创建的Bean 标识符放在一个"当前创建Bean池"中,Bean标识符在创建过程中将一直保持 在这个池中,因此如果在创建Bean过程中发现自己已经在"当前创建Bean池"里时将抛出 BeanCurrentlyInCrea
-
浅谈Spring如何解决循环依赖的问题
在关于Spring的面试中,我们经常会被问到一个问题,就是Spring是如何解决循环依赖的问题的.这个问题算是关于Spring的一个高频面试题,因为如果不刻意研读,相信即使读过源码,面试者也不一定能够一下子思考出个中奥秘.本文主要针对这个问题,从源码的角度对其实现原理进行讲解. 1. 过程演示 关于Spring bean的创建,其本质上还是一个对象的创建,既然是对象,读者朋友一定要明白一点就是,一个完整的对象包含两部分:当前对象实例化和对象属性的实例化.在Spring中,对象的实例化是通过反射实
-
Spring如何解决循环依赖的问题
前言 在面试的时候这两年有一个非常高频的关于spring的问题,那就是spring是如何解决循环依赖的.这个问题听着就是轻描淡写的一句话,其实考察的内容还是非常多的,主要还是考察的应聘者有没有研究过spring的源码.但是说实话,spring的源码其实非常复杂的,研究起来并不是个简单的事情,所以我们此篇文章只是为了解释清楚Spring是如何解决循环依赖的这个问题. 什么样的依赖算是循环依赖? 用过Spring框架的人都对依赖注入这个词不陌生,一个Java类A中存在一个属性是类B的一个对象,那么我
-
spring 如何解决循环依赖
首先解释下什么是循环依赖,其实很简单,就是有两个类它们互相都依赖了对方,如下所示: @Component public class AService { @Autowired private BService bService; } @Component public class BService { @Autowired private AService aService; } AService和BService显然两者都在内部依赖了对方,单拎出来看仿佛看到了多线程中常见的死锁代码,但很显然S
-
spring如何解决循环依赖问题详解
循环依赖其实就是循环引用,很多地方都说需要两个或则两个以上的bean互相持有对方最终形成闭环才是循环依赖,比如A依赖于B,B依赖于C,C又依赖于A.其实一个bean持有自己类型的属性也会产生循环依赖. setter singleton循环依赖 使用 SingleSetterBeanA依赖SingleSetterBeanB,SingleSetterBeanB依赖SingleSetterBeanA. @Data public class SingleSetterBeanA { @Autowired
-
Spring为何要用三级缓存来解决循环依赖问题
我们都知道Spring为了解决循环依赖使用了三级缓存 Spring三级缓存 一级缓存singletonObjects 用于保存BeanName和创建bean实例之间的关系,beanName -> bean instance private final Map<String, Object> singletonObjects = new ConcurrentHashMap(256); 二级缓存earlySingletonObjects 保存提前曝光的单例bean对象 private fin
-
Spring解决循环依赖的方法(三级缓存)
说起Spring,作为流水线上装配工的小码农,可能是我们最熟悉不过的一种技术框架.但是对于Spring到底是个什么东西,我猜作为大多数的你可能跟我一样,只知道IOC.DI,却并不明白这其中的原理究竟是怎样的.在这儿你可能想得完整的关于Spring相关的知识,但是我要告诉你对不起.这里不是教程,只能作为你窥探spring核心的窗口.我不做教程,因为网上的教程.源码解析太多,你可以自行选择学习.但我要提醒你的是,看再多的教程也不如你一次的主动去追踪源码. 好了,废话说了这么多就是提醒你这里不是一个教
-
Spring为何需要三级缓存解决循环依赖详解
目录 前言 bean生命周期 三级缓存解决循环依赖 总结 前言 在使用spring框架的日常开发中,bean之间的循环依赖太频繁了,spring已经帮我们去解决循环依赖问题,对我们开发者来说是无感知的,下面具体分析一下spring是如何解决bean之间循环依赖,为什么要使用到三级缓存,而不是二级缓存 bean生命周期 首先大家需要了解一下bean在spring中的生命周期,bean在spring的加载流程,才能够更加清晰知道spring是如何解决循环依赖的 我们在spring的BeanFacto
-
Spring详细讲解循环依赖是什么
目录 前言 什么是循环依赖 Spring如何处理的循环依赖 只用一级缓存会存在什么问题 只用二级缓存会存在什么问题 Spring 为什么不用二级缓存来解决循环依赖问题 总结 前言 Spring在我们实际开发过程中真的太重要了,当你在公司做架构升级.沉淀工具等都会多多少少用到Spring,本人也一样,在研习了好几遍Spring源码之后,产生一系列的问题, 也从网上翻阅了各种资料,最近说服了自己,觉得还是得整理一下,有兴趣的朋友可以一起讨论沟通一波.回到标题,我们要知道以下几点: (1)什么是循环依
-
spring解决循环依赖的简单方法
Spring内部如何解决循环依赖,一定是单默认的单例Bean中,属性互相引用的场景.比如几个Bean之间的互相引用: 或者 setter方式原型,prototype 原型(Prototype)的场景是不支持循环依赖的,因为"prototype"作用域的Bean,为每一个bean请求提供一个实例,Spring容器不进行缓存,因此无法提前暴露一个创建中的Bean,会抛出异常. 构造器参数循环依赖 Spring容器会将每一个正在创建的Bean 标识符放在一个"当前创建Bean池&q