Java中关于字符串的编码方式
目录
- 字符串的编码方式
- idea中默认的字符串编码方式为utf-8
- utf-8和GBK中字符串所占用的字节数
- 设置字符串编码、转码
- UTF-8
- UTF-16
- UTF-32
- java中编码
- 解决编码乱码
字符串的编码方式
UTF-8是Unicode的一种实现方式,也就是它的字节结构有特殊要求,所以我们说一个汉字的范围是0X4E00到0x9FA5,是指unicode值,至于放在utf-8的编码里去就是由三个字节来组织,所以可以看出unicode是给出一个字符的范围,定义了这个字是码值是多少,至于具体的实现方式可以有多种多样来实现。
idea中默认的字符串编码方式为utf-8
System.out.println(System.getProperty("file.encoding"));
更改编码方式:settings->fileCoding->GlobalEncoding = GBK
输出结果:

utf-8和GBK中字符串所占用的字节数
public static void print(String s) {
for (byte aByte : s.getBytes()) {
System.out.println(aByte);
}
System.out.println("----------------");
}
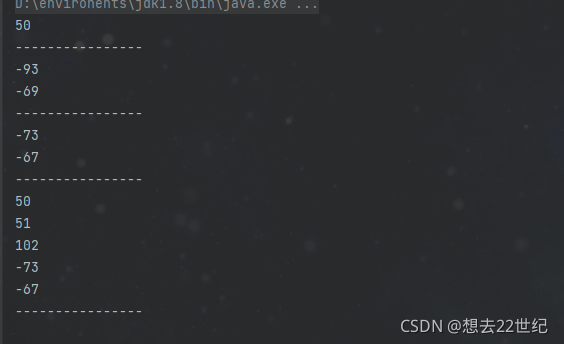
GBK编码方式下,键盘在中文状态
数字字母占一个字节,符号或者中文占用两个字节
public static void main(String[] args) {
String s1 = "2";
print(s1);
String s2 = ";";
print(s2);
String s3 = "方";
print(s3);
String s4 = "23f方";
print(s4);
}
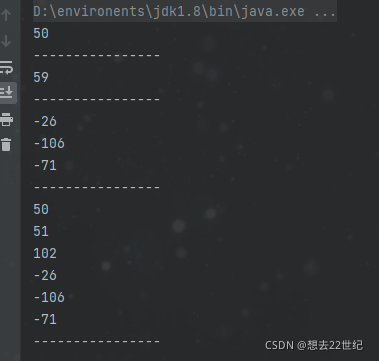
gbk编码方式下,键盘在英文状态
字母数字占,符号用1个字节,中文占用两个字节
public static void main(String[] args) {
String s1 = "2";
print(s1);
String s2 = ";";
print(s2);
String s3 = "f";
print(s3);
String s4 = "23f方";
print(s4);
}

utf-8的方式下
中文,中文符号占用3个字节,英文符号占用1个字节,字母数字占用1个字节
public static void main(String[] args) {
String s1 = "2";
print(s1);
String s2 = ";";
print(s2);
String s3 = "方";
print(s3);
String s4 = "23f方";
print(s4);
}
小结:
- utf-8下中文中文符号占用3字节,英文符号,字母数字占用1个字节
- gbk下中文中文符号占用2字节,英文符号,字母数字占用1个字节
设置字符串编码、转码
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。目前的Unicode字符分为17组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有65536个码位,共1114112个。然而目前只用了少数平面。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
通用字符集(Universal Character Set, UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。UCS-2用两个字节编码,UCS-4用4个字节编码。
UTF-8
UTF-8以字节为单位对Unicode进行编码。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码,由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码Unicode字符。
用在网页上可以统一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
UTF-16
UTF-16编码以16位无符号整数为单位。
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为 "storage format")的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
UTF-16是Unicode的其中一个使用方式。 UTF是 Unicode TransferFormat,即把Unicode转做某种格式的意思。
它定义于ISO/IEC 10646-1的附录Q,而RFC2781也定义了相似的做法。
在Unicode基本多文种平面定义的字符(无论是拉丁字母、汉字或其他文字或符号),一律使用2字节储存。而在辅助平面定义的字符,会以代理对(surrogate pair)的形式,以两个2字节的值来储存。UTF-16比起UTF-8,好处在于大部分字符都以固定长度的字节 (2字节) 储存,但UTF-16却无法兼容于ASCII编码。
UTF-32
UTF-32编码以32位无符号整数为单位。
Unicode的UTF-32编码就是其对应的32位无符号整数。
UTF-32 (或 UCS-4)是一种将Unicode字符编码的协定,对每一个Unicode码位使用恰好32位元。其它的Unicode transformation formats则使用不定长度编码。因为UTF-32对每个字符都使用4字节,就空间而言,是非常没有效率的。特别地,非基本多文种平面的字符在大部分文件中通常很罕见,以致于它们通常被认为不存在占用空间大小的讨论,使得UTF-32通常会是其它编码的二到四倍。虽然每一个码位使用固定长定的字节看似方便,它并不如其它Unicode编码使用得广泛。j
java中编码
String gbkStr = "你好哦!"; //源码文件是GBK格式,或者这个字符串是从GBK文件中读取出来的, 转换为string 变成unicode格式
//利用getBytes将unicode字符串转成UTF-8格式的字节数组
byte[] utf8Bytes = gbkStr.getBytes("UTF-8");
//然后用utf-8 对这个字节数组解码成新的字符串
String utf8Str = new String(utf8Bytes, "UTF-8");
简化后就是:
unicodeToUtf8 (String s) {
return new String( s.getBytes("utf-8") , "utf-8");
}
UTF-8 转GBK原理也是一样
return new String( s.getBytes("GBK") , "GBK");
解决编码乱码
java 获取系统中默认的编码
//方法一:中文操作系统中打印GBK
System.out.println(System.getProperty("file.encoding"));
//方法二:中文操作系统中打印GBK
System.out.println(Charset.defaultCharset());
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
一文解开java中字符串编码的小秘密(干货)
简介 在本文中你将了解到Unicode和UTF-8,UTF-16,UTF-32的关系,同时你还会了解变种UTF-8,并且探讨一下UTF-8和变种UTF-8在java中的应用. 一起来看看吧. Unicode的发展史 在很久很久以前,西方世界出现了一种叫做计算机的高科技产品. 初代计算机只能做些简单的算数运算,还要使用人工打孔的程序才能运行,不过随着时间的推移,计算机的体积越来越小,计算能力越来越强,打孔已经不存在了,变成了人工编写的计算机语言. 一切都在变化,唯有一件事情没有变化.这件事件就是计
-
Java JDK1.7对字符串的BASE64编码解码方法
如下所示: package cn.itcast; import java.io.IOException; import java.io.UnsupportedEncodingException; import org.junit.Test; import sun.misc.BASE64Decoder; /* * @author soto * BASE64编码 解码 * */ public class Demo1 { @Test public void fun1() throws IOExcept
-

java基础之字符串编码知识点总结
一.为什么要编码 不知道大家有没有想过一个问题,那就是为什么要编码?我们能不能不编码?要回答这个问题必须要回到计算机是如何表示我们人类能够理解的符号的,这些符号也就是我们人类使用的语言.由于人类的语言有太多,因而表示这些语言的符号太多,无法用计算机中一个基本的存储单元-- byte 来表示,因而必须要经过拆分或一些翻译工作,才能让计算机能理解.我们可以把计算机能够理解的语言假定为英语,其它语言要能够在计算机中使用必须经过一次翻译,把它翻译成英语.这个翻译的过程就是编码.所以可以想象只要不是说英语
-
Java中关于字符串的编码方式
目录 字符串的编码方式 idea中默认的字符串编码方式为utf-8 utf-8和GBK中字符串所占用的字节数 设置字符串编码.转码 UTF-8 UTF-16 UTF-32 java中编码 解决编码乱码 字符串的编码方式 UTF-8是Unicode的一种实现方式,也就是它的字节结构有特殊要求,所以我们说一个汉字的范围是0X4E00到0x9FA5,是指unicode值,至于放在utf-8的编码里去就是由三个字节来组织,所以可以看出unicode是给出一个字符的范围,定义了这个字是码值是多少,至于具体
-
java中String字符串删除空格的七种方式
目录 trim() strip() stripLeading() 和 stripTrailing() replace replaceAll replaceFirst 总结 在Java中从字符串中删除空格有很多不同的方法,如trim,replaceAll等.但是,在JDK 11添加了一些新的功能,如strip.stripLeading.stripTrailing等. 想要从String中移除空格部分,有多少种方法,下面介绍JDK原生自带的方法,不包含第三方工具类库中的类似方法 trim() : 删
-
Java中BufferedReader和BufferedWriter使用方式
目录 FileWriter/FileReader BufferedReader/BufferedWriter FileWriter/FileReader 介绍:FileWriter 类从 OutputStreamWriter 类继承而来.该类按字符向流中写入数据. 构造:参数为 File 对象 FileWriter(File file) 参数是文件的路径及文件名(默认是当前执行文件的路径) FileWrite(String filename) 等价于: OutputStreamWriter ou
-
深入理解Java中的字符串类型
1.Java内置对字符串的支持: 所谓的内置支持,即不用像C语言通过char指针实现字符串类型,并且Java的字符串编码是符合Unicode编码标准,这也意味着不用像C++那样通过使用string和wstring类实现与C语言兼容和Unicode标准.Java内部通过String类实现对字符串类型的支持.这意味着:我们可以直接对字符串常量调用和String对象同样的方法: //可以再"abc"上直接调用String对象的所有方法 int length="abc".l
-
Java 中的字符串常量池详解
Java中的字符串常量池 Java中字符串对象创建有两种形式,一种为字面量形式,如String str = "droid";,另一种就是使用new这种标准的构造对象的方法,如String str = new String("droid");,这两种方式我们在代码编写时都经常使用,尤其是字面量的方式.然而这两种实现其实存在着一些性能和内存占用的差别.这一切都是源于JVM为了减少字符串对象的重复创建,其维护了一个特殊的内存,这段内存被成为字符串常量池或者字符串字面量池.
-
Java 中运行字符串表达式的方法
在日常的开发中,偶尔会遇到运行字符串表达式的情况,通常这样的需求会对需求进行进一步分析,然后进行进一步 "特殊化",最后直接写到硬代码中,这样做的话,就不太好扩展了:也有另外的处理方式是采用 Java 内置的 JavaScript 引擎等运行字符串表达式,但是内置引擎也有弊端,比如频繁运行片段式的字符串的效率非常低,并且与 Java 之间的数据交互比较麻烦,于是,便产生了写一个"字符串表达式计算引擎"的想法... 写的过程其实没想象中那么麻烦,最初版大概在今年 5
-
Java中的3种输入方式实现解析
这篇文章主要介绍了Java中的3种输入方式实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.从键盘读取char类型数据 char ch = (char)System.in.read(); System.in 提供的 read() 方法每次只能读取一个字节的数据,所以用的频率比较低. 2.BufferedReader 实现从键盘读取String类型数据 使用BufferedReader 对象的 readLine() 方法必须处理 jav
-
Java中动态规则的实现方式示例详解
背景 业务系统在应用过程中,有时候要处理"经常变化"的部分,这部分需求可能是"业务规则",也可能是"不同的数据处理逻辑",这部分动态规则的问题,往往需要可配置,并对性能和实时性有一定要求. Java不是解决动态层问题的理想语言,在实践中发现主要有以下几种方式可以实现: 表达式语言(expression language) 动态语言(dynamic/script language language),如Groovy 规则引擎(rule engine
-
浅谈在Java中JSON的多种使用方式
1. 常用的JSON转换 JSONObject 转 JSON 字符串 JSONObject json = new JSONObject(); jsonObject.put("name", "test"); String str = JSONObject.toJSONString(json); JSON字符串转JSON String str = "{\"name\":\"test\"}"; JSONObjec
-
Java中判断字符串是否相等的实现
在最近的开发中,我踩到一个坑,过程是这样的.我需要在Java中判断两个字符串是否相等,按照以往的经历使用 == 双等号的操作符来判断,但是在Java中,这样写却没有实现我想要的效果.经过查阅资料后,把得到的经验分享给大家. 相等判断操作符== Java中,==相等判断符用于判断基本数据类型和引用数据类型. 当判断基本数据类型的时候判断的是数值,当判断引用数据类型时判断变量是否指向同一引用对象. 使用==判断字符串时,判断的是两个字符串是否指向同一个对象.如果两个字符串指向同一个对象,那么它们就是