利用Python实现翻译HTML中的文本字符串
相信大家都用过浏览器的翻译网页功能,例如对于下图这个英文网页:

一键翻译成中文以后是这样的:
你可能会觉得这个功能很简单,不就是字符串替换吗?那你可以试一试把下面这个HTML片段中的<p>标签下面的英文翻译成中文。其它标签中的不要改动:
<div> <p>if you want to parse date and time, your could use <em>datetime</em>, by use this library, you can generate now time by one line code <span>datetime.datetime.now()</span> this is so easy.</p> </div>
在<em>标签中的datetime和<span>标签中的datetime.datetime.now()不需要翻译。
你一拍脑袋,马上写出了下面这几行代码(假设你已经有了一个现成的translate()函数,传入英文,输出中文):
from lxml.html import fromstring
source = '''<div>
<p>if you want to parse date and time, your could use <em>datetime</em>, by use this library, you can generate now time by one line code <span>datetime.datetime.now()</span> this is so easy.</p>
</div>
'''
selector = fromstring(source)
text_list = selector.xpath('//p/text()')
for text in text_list:
chinese = translate(text)
...
当你写到这里,你应该会愣一下。因为你突然发现一个问题,怎么把中文替换回去?
不用尝试去百度了。在今天(2022-06-20)之前,整个中文网络里面,你找不到解决方法。
一个比较笨的办法是直接对原始的HTML字符串进行文本替换:
for text in text_list: chinese = translate(text) source = source.replace(text, chinese)
但这样做,效率非常低。因为你要不停扫描整个HTML字符串。一般一个中型网站的HTML就有几千上万行,十几二十万个字符。你每翻译一小段就全文替换一次,这个时间会非常漫长。
那有没有办法只对当前这一个<p>标签里面的文本进行替换呢?关键的问题来了,你替换可以,但是怎么才能不影响这个<p>标签下面的两个子标签?要保证文本和子标签的相对位置不改变。
如果<p>标签下面只有一段文本,没有子标签,那么非常简单,如下图所示:

但现在的问题是,<p>标签下面有三段文本。每段文本之间还插入了其它的子标签。我们怎么样对每一段文本进行替换,但是又保持文本的相对顺序,并且还不能影响子标签?

p.text这种写法首先就可以排除了,因为它没有办法指定替换第几段文本。
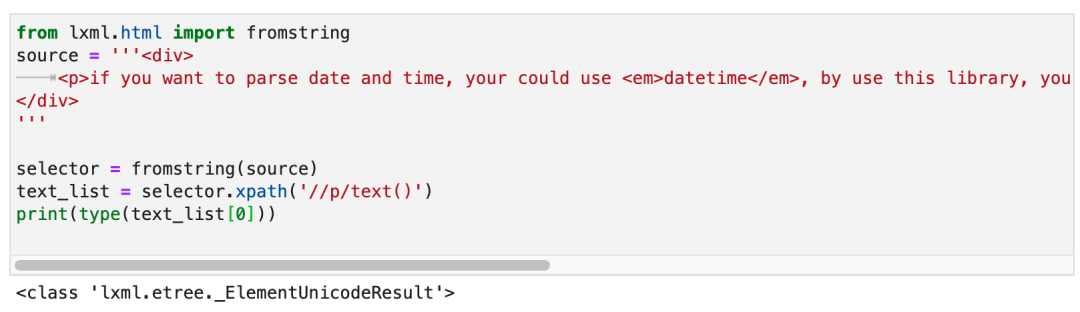
你之所以会觉得这个问题很难解决,是因为你有一个错觉,请看上面这张截图,我打印了text_list。打印出来是一个包含字符串的列表。所以你可能会觉得。使用lxml写Xpath的时候,/text()返回的总是包含字符串的列表。
但实际上,返回的列表里面的元素并不是字符串,而是_ElementUnicodeResult对象。如下图所示:
不是字符串就简单了,那么我们可以获取每一个文本对象的父标签。然后修改父标签下面的文本就可以了。
看到这里,你肯定会问,这三个文本节点的父标签,不都是同一个<p>吗?如果你觉得是,那你就犯了想当然的错误。我们用代码来看看:

其实只有第一段文本的父标签是<p>。第二段文本的父标签,竟然是<p>的子标签<em>。第三段文本的父标签,是<span>。
等等,如果第二段文本的父标签是<em>,那么<em>datetime</em>里面的datetime的父标签是什么?它的父标签也是<em>!那么问题来了,<em>的text()文本节点,怎么可能又是datetime,又是<p>下面的第二段文本呢?
实际上,<em>的text()始终都是datetime。如下图所示:

那么,<p>的第二段文本跟这个<em>标签是什么关系?实际上,这个关系叫做tail。如下图所示:
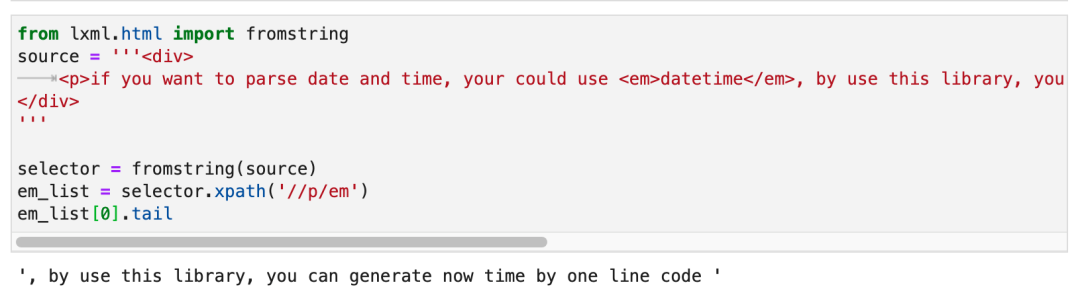
在一个标签里面,只有第一段text是它真正的text(),如果这个标签有子标签,那么位于子标签后面的文本,是这个子标签的tail。只不过当我们在正则表达式里面写/text()的时候,lxml会帮我们把所有子标签的tail都算作当前标签的text。
我们可以使用文本节点的.is_text和.is_tail来判断它属于哪种文本。最终运行效果如下图所示:

以上就是利用Python实现翻译HTML中的文本字符串的详细内容,更多关于Python翻译HTML中字符串的资料请关注我们其它相关文章!
相关推荐
-

python 将html转换为pdf的几种方法
将 HTML 网页转换为 PDF 是很多人常见的一个需求,在浏览器上,我们可以通过浏览器的"打印"功能直接将网页打印输出为 PDF. 但是如果有多个网页就不好办了. 二进制软件 网络上存在很多将 HTML 转换为 PDF 的软件和工具.比较著名的有 Carelib.wkhtmltopdf. whtmltopdf wkhtmltopdf 真是一个优秀的 HTML 转换 PDF 工具.其借助 Qt 的 WebKit 渲染引擎,将 HTML 文档渲染导出为 PDF 文档或图像. 功能十分完善
-
Python在字符串中处理html和xml的方法
问题 你想将HTML或者XML实体如 &entity; 或 &#code; 替换为对应的文本. 再者,你需要转换文本中特定的字符(比如<, >, 或 &). 解决方案 如果你想替换文本字符串中的 '<' 或者 '>' ,使用 html.escape() 函数可以很容易的完成.比如: >>> s = 'Elements are written as "<tag>text</tag>".' >&
-
python 提取html文本的方法
假设我们需要从各种网页中提取全文,并且要剥离所有HTML标记.通常,默认解决方案是使用BeautifulSoup软件包中的get_text方法,该方法内部使用lxml.这是一个经过充分测试的解决方案,但是在处理成千上万个HTML文档时可能会非常慢. 通过用selectolax替换BeautifulSoup,您几乎可以免费获得5-30倍的加速! 这是一个简单的基准测试,可分析commoncrawl(`处理NLP问题时,有时您需要获得大量的文本集.互联网是文本的最大来源,但是不幸的是,从任意HTML
-
在Python中的Django框架中进行字符串翻译
使用函数 ugettext() 来指定一个翻译字符串. 作为惯例,使用短别名 _ 来引入这个函数以节省键入时间. 在下面这个例子中,文本 "Welcome to my site" 被标记为待翻译字符串: from django.utils.translation import ugettext as _ def my_view(request): output = _("Welcome to my site.") return HttpResponse(output
-
利用Python实现翻译HTML中的文本字符串
相信大家都用过浏览器的翻译网页功能,例如对于下图这个英文网页: 一键翻译成中文以后是这样的: 你可能会觉得这个功能很简单,不就是字符串替换吗?那你可以试一试把下面这个HTML片段中的<p>标签下面的英文翻译成中文.其它标签中的不要改动: <div> <p>if you want to parse date and time, your could use <em>datetime</em>, by use this library, you c
-
教你利用python如何读取txt中的数据
目录 前言 方法一:运用open()函数 方法二:使用numpy包的loadtxt方法 方法三:使用pandas的read_table方法进行读取 总结 前言 当我们在用python时可能会遇到想要把txt文档里的数据读取出来然后进行绘图,那么我们要怎么才能够将txt里的数据读取出来呢? 假设有txt文本如下: 想要把上述文本数据读取出来,可以用以下方法: 方法一:运用open()函数 该方法使用最基本的open函数进行读取,此处将会把数据读取到一个列表中,这个方法一般就是open打开文件.re
-
利用Python实现朋友圈中的九宫格图片效果
前言 大家应该经常在朋友圈看到有人发九宫格图片,其实质就是将一张图片切成九份,然后在微信中一起发这九张图即可. 说到切图,Python 就可以实现,主要用到的 Python 库为 Pillow,安装使用 pip install pillow 即可,切图的主要步骤如下: 打开要处理的图片 判断打开的图片是否为正方形 如果是正方形,就进行九等分,如果不是正方形,先用白色填充为正方形,再进行九等分 保存处理完的图片 主要实现代码如下: # 填充新的 image def fill_image(image
-
如何利用Python处理excel表格中的数据
目录 一.基础.常用方法 二.提高 三.出错 总结 一.基础.常用方法 1. 读取excel 1.导入模块: import xlrd 2.打开文件: x1 = xlrd.open_workbook("data.xlsx") 3.获取sheet: sheet是指工作表的名称,因为一个excel有多个工作表 获取所有sheet名字:x1.sheet_names() 获取sheet数量:x1.nsheets 获取所有sheet对象:x1.sheets() 通过sheet名查找:x1.shee
-
如何利用python执行txt文件中的代码
目录 前言: 1.什么是exec()函数? 2.如何将txt中的代码作为字符串读取? 3.使用exec()执行txt文件的完整例子 前言: 我们知道,python代码文件大多数都是py类型. 那么,能不能使用txt文件存储我们的代码呢? python这么强大的语言当然可以做大,只需使用内置的exex()函数. 1.什么是exec()函数? 根据官方文档的介绍,exec函数的定义如下: exec(source, globals=None, locals=None, /) Execute t
-
如何利用Python随机从list中挑选一个元素
目录 1. 引言 2. 举个栗子 3. 使用Random库 3.1 随机下标 3.2 随机选择单个元素 3.3 随机选择多个元素 4. 使用Secrets库 4.1 随机下标 4.2 随机选择单个元素 4.3 随机选择多个元素 5. 总结 1. 引言 在本文中,我们将研究从列表中选择随机元素的不同实现方法.在日常项目中,我们经常会遇到这种情形,比如随机从多种数据增强策略中选择一种或几种来提升训练数据的多样性.闲话少说,我们直接开始吧. :) 2. 举个栗子 为了方便示例,这里我们假设有一个包含多
-
教你如何利用Python批量翻译英文Word文档并保留格式
一.需求描述 手上有大量外文文档(本案例以5份为例,分别命名为 test1.docx test2.docx 以此类推),其中一份如下: 基本需求:「批量将这些文档的内容全部翻译成中文,并转存到新的文件中」,效果如下: 高级需求:基本需求满足的同时,要求 「保留原文档的格式」,效果如下: 二.逻辑梳理 2.1 翻译 API 本需求的核心是翻译,策略是利用网络的翻译 API,这里推荐百度翻译开放平台,不考虑并发数的话可以用标准版,免费使用不限字符量! " 百度翻译开放平台:http://api.fa
-
利用Python的Django框架中的ORM建立查询API
摘要 在这篇文章里,我将以反模式的角度来直接讨论Django的低级ORM查询方法的使用.作为一种替代方式,我们需要在包含业务逻辑的模型层建立与特定领域相关的查询API,这些在Django中做起来不是非常容易,但通过深入地了解ORM的内容原理,我将告诉你一些简捷的方式来达到这个目的. 概览 当编写Django应用程序时,我们已经习惯通过添加方法到模型里以此达到封装业务逻辑并隐藏实现细节.这种方法看起来是非常的自然,而且实际上它也用在Django的内建应用中. >>> from djang
-
利用Python找出序列中出现最多的元素示例代码
前言 Python包含6种内置的序列:列表.元组.字符串 .Unicode字符串.buffer对象.xrange对象.在序列中的每个元素都有自己的编号.列表与元组的区别在于,列表是可以修改,而组元不可修改.理论上几乎所有情况下元组都可以用列表来代替.有个例外是但元组作为字典的键时,在这种情况下,因为键不可修改,所以就不能使用列表. 我们在一些统计工作或者分析过程中,有事会遇到要统计一个序列中出现最多次的元素,比如一段英文中,查询出现最多的词是什么,及每个词出现的次数.一遍的做法为,将每个此作为k
-
Python实现PS滤镜中马赛克效果示例
本文实例讲述了Python实现PS滤镜中马赛克效果.分享给大家供大家参考,具体如下: 这里利用 Python 实现PS 滤镜中的马赛克效果,具体的算法原理和效果可以参考附录说明,Python示例代码如下: from skimage import img_as_float import matplotlib.pyplot as plt from skimage import io import random import numpy as np file_name='D:/Visual Effec