pandas 读取excel文件的操作代码
目录
- 一 read_excel() 的基本用法
- 二 read_excel() 的常用的参数:
- 三 示例
- 1. IO:路径
- 2. sheet_name:指定工作表名
- 3. header :指定标题行
- 4. names: 指定列名
- 5. index_col: 指定列索引
- 6. skiprows:跳过指定行数的数据
- 7. skipfooter:省略从尾部的行数据
- 8.dtype 指定某些列的数据类型
一 read_excel() 的基本用法
import pandas as pd file_name = 'xxx.xlsx' pd.read_excel(file_name)
二 read_excel() 的常用的参数:
io: excel路径 可以是文件路径, 类文件对象, 文件路径对象等。
sheet_name=0: 访问指定excel某张工作表。sheet_name可以是str, int, list 或 None类型, 默认值是0。
str类型 是直接指定工作表的名称
int类型 是指定从0开始的工作表的索引, 所以sheelt_name默认值是0,即第一个工作表。
list类型 是多个索引或工作表名构成的list,指定多个工作表。
None类型, 访问所有的工作表
sheet_name=0: 得到的是第1个sheet的DataFrame类型的数据
sheet_name=2: 得到的是第3个sheet的DataFrame类型的数据
sheet_name=‘Test1': 得到的是名为'Test1'的sheet的DataFrame类型的数据
sheet_name=[0, 3, ‘Test5']: 得到的是第1个,第4个和名为Test5 的工作表作为DataFrame类型的数据的字典。
header=0:header是标题行,通过指定具体的行索引,将该行作为数据的标题行,也就是整个数据的列名。默认首行数据(0-index)作为标题行,如果传入的是一个整数列表,那这些行将组合成一个多级列索引。没有标题行使用header=None。
name=None: 传入一列类数组类型的数据,用来作为数据的列名。如果文件数据不包含标题行,要显式的指出header=None。
skiprows:int类型, 类列表类型或可调函数。 要跳过的行号(0索引)或文件开头要跳过的行数(int)。如果可调用,可调用函数将根据行索引进行计算,如果应该跳过行则返回True,否则返回False。一个有效的可调用参数的例子是lambda x: x in [0, 1, 2]。
skipfooter=0: int类型, 默认0。自下而上,从尾部指定跳过行数的数据。
usecols=None: 指定要使用的列,如果没有默认解析所有的列。
index_col=None: int或元素都是int的列表, 将某列的数据作为DataFrame的行标签,如果传递了一个列表,这些列将被组合成一个多索引,如果使用usecols选择的子集,index_col将基于该子集。
squeeze=False, 布尔值,默认False。 如果解析的数据只有一列,返回一个Series。
dtype=None: 指定某列的数据类型,可以使类型名或一个对应列名与类型的字典,例 {‘A': np.int64, ‘B': str}
nrows=None: int类型,默认None。 只解析指定行数的数据。
三 示例
如图是演示使用的excel文件,它包含5张工作表。
1. IO:路径
举一个IO为文件对象的例子, 有些时候file文件路径的包含较复杂的中文字符串时,pandas 可能会解析文件路径失败,可以使用文件对象来解决。
file = 'xxxx.xlsx'
f = open(file, 'rb')
df = pd.read_excel(f, sheet_name='Sheet1')
f.close() # 没有使用with的话,记得要手动释放。
# ------------- with模式 -------------------
with open(file, 'rb') as f:
df = pd.read_excel(f, sheet_name='Sheet1')
2. sheet_name:指定工作表名
sheet_name=‘Sheet', 指定解析名为"Sheet1"的工作表。返回一个DataFrame类型的数据。
df = pd.read_excel(file, sheet_name='Sheet1')
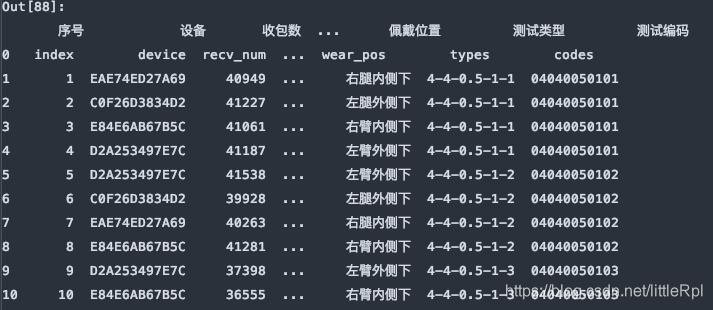
sheet_name=[0, 1, ‘Sheet1'], 对应的是解析文件的第1, 2张工作表和名为"Sheet1"的工作表。它返回的是一个有序字典。结构为{name:DataFrame}这种类型。
df_dict = pd.read_excel(file, sheet_name=[0,1,'Sheet1'])
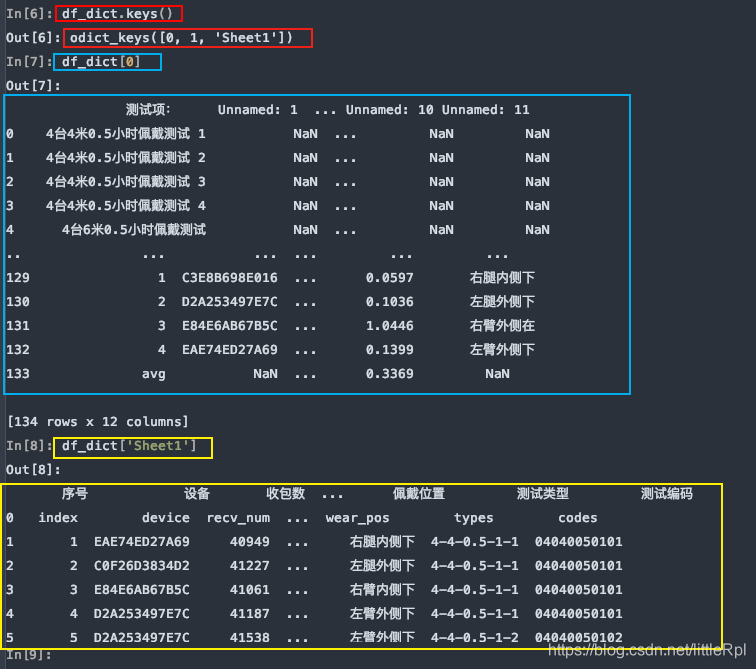
sheet_name=None 会解析该文件中所有的工作表,返回一个同上的字典类型的数据。
df_dict = pd.read_excel(file, sheet_name=None)

3. header :指定标题行
header是用来指定数据的标题行,也就是数据的列名的。本文使用的示例文件具有中英文两行列名,默认header=0是使用第一行数据作为数据的列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1')
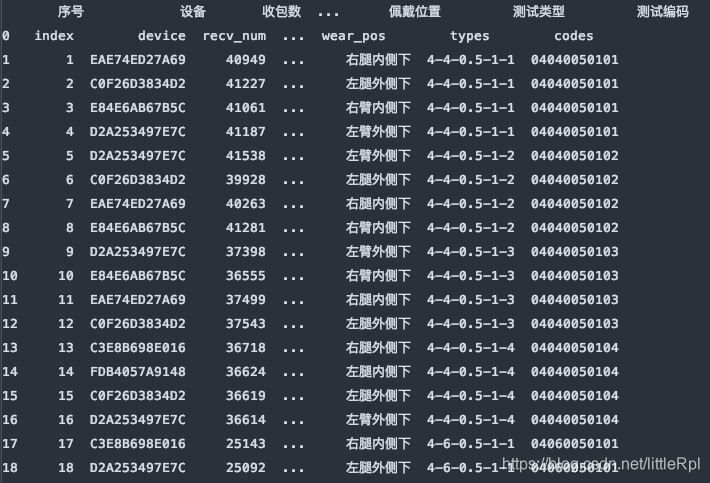
header=1, 使用指定使用第二行的英文列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1', header=1)
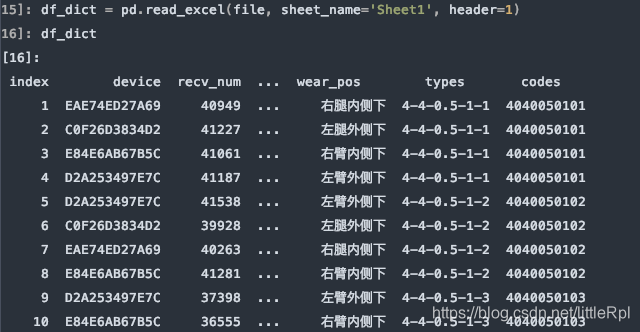
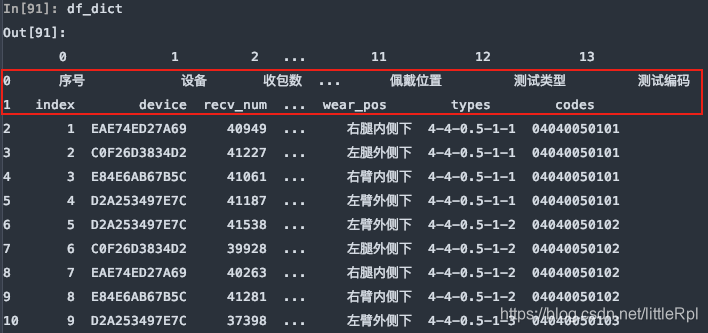
需要注意的是,如果不行指定任何行作为列名,或数据源是无标题行的数据,可以显示的指定header=None来表明不使用列名。
df_dict = pd.read_excel(file, sheet_name='Sheet1', header=None)
4. names: 指定列名
指定数据的列名,如果数据已经有列名了,会替换掉原有的列名。
df = pd.read_excel(file, sheet_name='Sheet1', names=list('123456789ABCDE'))
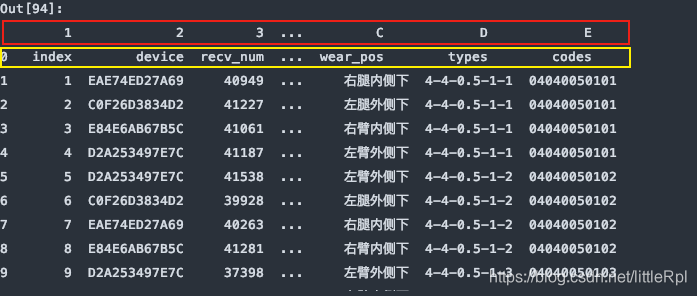
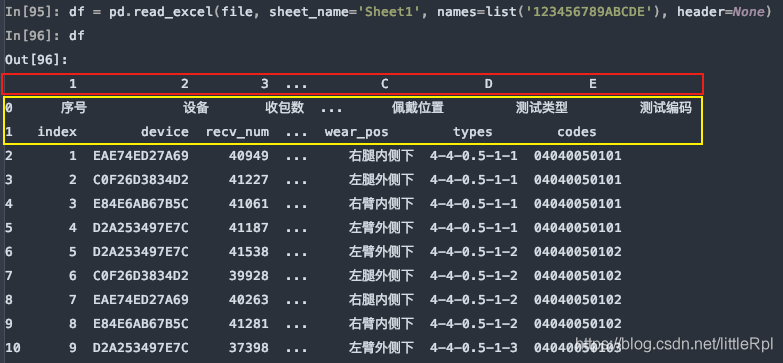
上图是header=0默认第一行中文名是标题行,最后被names给替换了列名,如果只想使用names,而又对源数据不做任何修改,我们可以指定header=None
df = pd.read_excel(file, sheet_name='Sheet1', names=list('123456789ABCDE'), header=None)
5. index_col: 指定列索引
df = pd.read_excel(file, sheet_name='Sheet1', header=1, index_col=0)
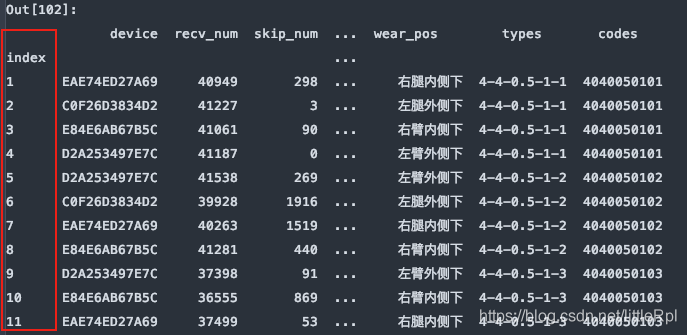
6. skiprows:跳过指定行数的数据
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=0)
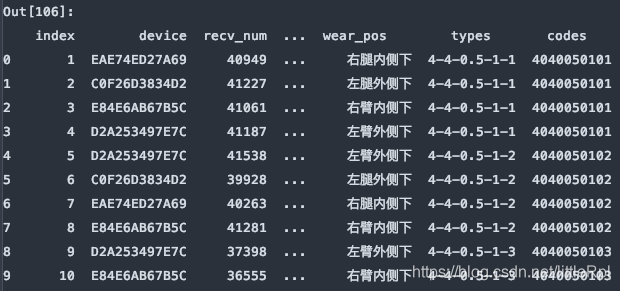
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=[1,3,5,7,9,])
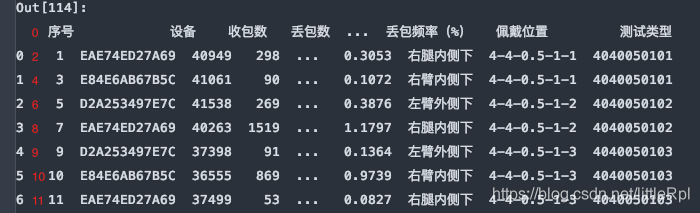
header与skiprows在有些时候效果相同,例skiprows=5和header=5。因为跳过5行后就是以第六行,也就是索引为5的行默认为标题行了。需要注意的是skiprows=5的5是行数,header=5的5是索引为5的行。
df = pd.read_excel(file, sheet_name='Sheet1', header=5)
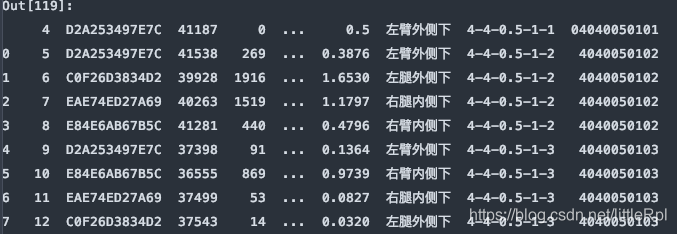
df = pd.read_excel(file, sheet_name='Sheet1', skiprows=5)
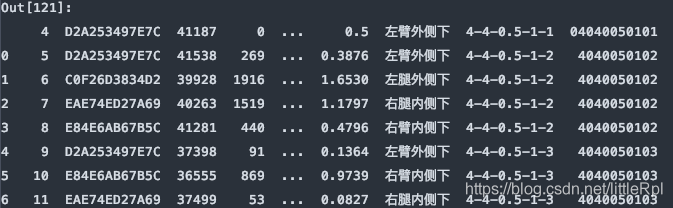
7. skipfooter:省略从尾部的行数据
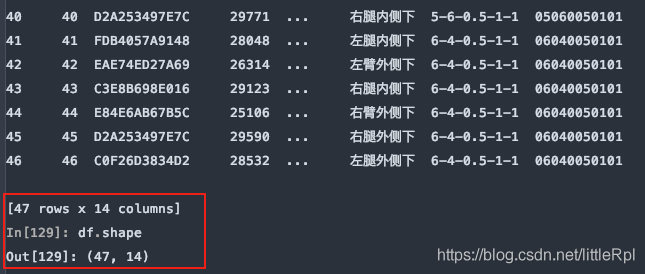
原始的数据有47行,如下图所示:
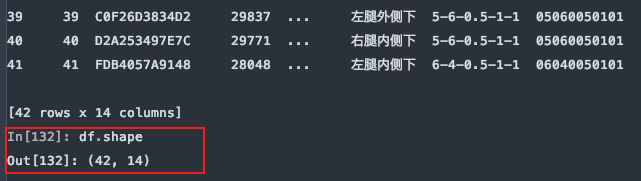
从尾部跳过5行:
df = pd.read_excel(file, sheet_name='Sheet1', skipfooter=5)
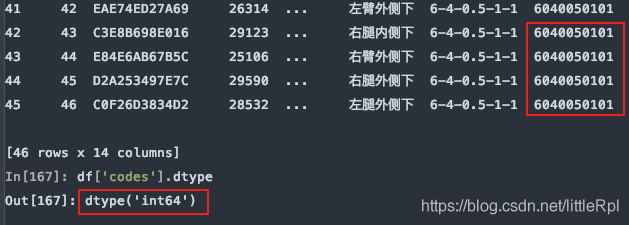
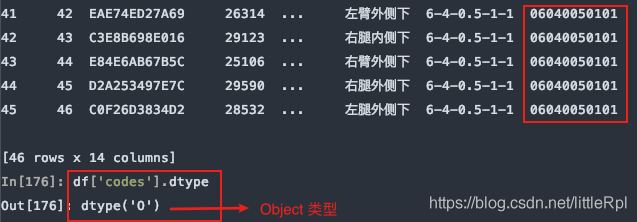
8.dtype 指定某些列的数据类型
示例数据中,测试编码数据是文本,而pandas在解析的时候自动转换成了int64类型,这样codes列的首位0就会消失,造成数据错误,如下图所示
指定codes列的数据类型:
df = pd.read_excel(file, sheet_name='Sheet1', header=1, dtype={'codes': str})
到此这篇关于pandas 读取excel文件的文章就介绍到这了,更多相关pandas 读取excel文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解pandas库pd.read_excel操作读取excel文件参数整理与实例
除了使用xlrd库或者xlwt库进行对excel表格的操作读与写,而且pandas库同样支持excel的操作:且pandas操作更加简介方便. 首先是pd.read_excel的参数:函数为: pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None, arse_cols=None,date_parser=None,na_values=None,thousands=None, convert_fl
-
解决使用Pandas 读取超过65536行的Excel文件问题
场景 今天需要合并天猫订单数据,由于前期6.18活动有很多数据需要处理,将几个月份合并一起,结果报错. 问题分析 Excel 文件的格式曾经发生过一次变化,在 Excel 2007 以前,使用扩展名为 .xls 格式的文件,这种文件格式是一种特定的二进制格式,最多支持 65,536 行,256 列表格.从 Excel 2007 版开始,默认采用了基于 XML 的新的文件格式 .xlsx ,支持的表格行数达到了 1,048,576,列数达到了 16,384.需要注意的是,将 .xlsx 格式的文件
-
python pandas写入excel文件的方法示例
pandas读取.写入csv数据非常方便,但是有时希望通过excel画个简单的图表看一下数据质量.变化趋势并保存,这时候csv格式的数据就略显不便,因此尝试直接将数据写入excel文件. pandas可以写入一个或者工作簿,两种方法介绍如下: 1.如果是将整个DafaFrame写入excel,则调用to_excel()方法即可实现,示例代码如下: # output为要保存的Dataframe output.to_excel('保存路径 + 文件名.xlsx') 2.有多个数据需要写入多个exce
-
python使用pandas处理excel文件转为csv文件的方法示例
由于客户提供的是excel文件,在使用时期望使用csv文件格式,且对某些字段内容需要做一些处理,如从某个字段中固定的几位抽取出来,独立作为一个字段等,下面记录下使用acaconda处理的过程: import pandas df = pandas.read_excel("/***/***.xlsx") df.columns = [内部为你给你的excel每一列自定义的名称](比如我给我的excel自定义列表为: ["url","productName&quo
-
pandas将多个dataframe以多个sheet的形式保存到一个excel文件中
要实现这个功能,可能有多种方法,我在这里记录下一个比较方便的方法: import pandas as pd writer = pd.ExcelWriter('test.xlsx') data1.to_excel(writer,sheet_name='sheet1') data2.to_excel(writer,sheet_name='sheet2') writer.save() 上面的方法会将原来的excel文件覆盖掉,假如想要对已经存在的excel文件进行修改,可以使用开源工具包(anacon
-
python利用pandas将excel文件转换为txt文件的方法
python将数据换为txt的方法有很多,可以用xlrd库实现.本人比较懒,不想按太多用的少的插件,利用已有库pandas将excel文件转换为txt文件. 直接上代码: ''' function:将excel文件转换为text author:Nstock date:2018/3/1 ''' import pandas as pd import re import codecs #将excel转化为txt文件 def exceltotxt(excel_dir, txt_dir): with co
-

pandas 读取excel文件的操作代码
目录 一 read_excel() 的基本用法 二 read_excel() 的常用的参数: 三 示例 1. IO:路径 2. sheet_name:指定工作表名 3. header :指定标题行 4. names: 指定列名 5. index_col: 指定列索引 6. skiprows:跳过指定行数的数据 7. skipfooter:省略从尾部的行数据 8.dtype 指定某些列的数据类型 一 read_excel() 的基本用法 import pandas as pd file_name
-
可以读取EXCEL文件的js代码第1/2页
首页给个有中文说明的例子,下面的例子很多大家可以多测试. 复制代码 代码如下: <script language="javascript" type="text/javascript"><!-- function readExcel() { var excelApp; var excelWorkBook; var excelSheet; try{ excelApp = new ActiveXObject("Excel.Applicatio
-
PHPExcel读取Excel文件的实现代码
涉及知识点: php对excel文件进行循环读取 php对字符进行ascii编码转化,将字符转为十进制数 php对excel日期格式读取,并进行显示转化 php对汉字乱码进行编码转化 复制代码 代码如下: <?php require_once 'PHPExcel.php'; /**对excel里的日期进行格式转化*/ function GetData($val){ $jd = GregorianToJD(1, 1, 1970); $gregorian = JDToGregorian($jd+in
-
用vbs读取Excel文件的函数代码
核心代码 复制代码 代码如下: Function ReadExcel( myXlsFile, mySheet, my1stCell, myLastCell, blnHeader ) ' Function : ReadExcel ' Version : 2.00 ' This function reads data from an Excel sheet without using MS-Office ' ' Arguments: ' myXlsFile [string] The path and
-
如何使用Golang创建与读取Excel文件
目录 摘要 引言 正文 架构 文件对象 数据的表示 数据的解析 实际架构 Excelize 基础库 文件 坐标 样式 单元格操作 数据验证 数据的表示和解析 表示 解析 大规模数据的写入 需要关注的问题 大量枚举值的设置 大工作表的读取 流式写入的注意事项 结语 参考资料 总结 摘要 本文提出一种使用 Golang 进行 Excel 文件创建和读取的方案.首先对问题进行分析,引出方案的基本架构:然后分章节描述了 Excelize 基础库的基本用法,以及 Excel 数据在 Golang 中的表示
-
python 使用pandas读取csv文件的方法
目录 pandas读取csv文件的操作 1. 读取csv文件 在这里记录一下,python使用pandas读取文件的方法用到pandas库的read_csv函数 # -*- coding: utf-8 -*- """ Created on Mon Jan 24 16:48:32 2022 @author: zxy """ # 导入包 import numpy as np import pandas as pd import matplotlib.
-
Pandas实现Excel文件读取,增删,打开,保存操作
目录 前言 一.Pandas 的主要函数包括 二.使用步骤 1.简单示例 2.保存Excel操作 3.删除和添加数据 4.添加新的表单 前言 Pandas 是一种基于 NumPy 的开源数据分析工具,用于处理和分析大量数据.Pandas 模块提供了一组高效的工具,可以轻松地读取.处理和分析各种类型的数据,包括 CSV.Excel.SQL 数据库.JSON 等格式的数据. 一.Pandas 的主要函数包括 pd.read_csv() / pd.read_excel() / pd.read_sql(
-
pandas读取excel,txt,csv,pkl文件等命令的操作
pandas读取txt文件 读取txt文件需要确定txt文件是否符合基本的格式,也就是是否存在\t,,,等特殊的分隔符 一般txt文件长成这个样子 txt文件举例 下面的文件为空格间隔 1 2019-03-22 00:06:24.4463094 中文测试 2 2019-03-22 00:06:32.4565680 需要编辑encoding 3 2019-03-22 00:06:32.6835965 ashshsh 4 2017-03-22 00:06:32.8041945 eggg 读取命令采用
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf