python爬虫看看虎牙女主播中谁最“顶”步骤详解
网页链接:https://www.huya.com/g/4079
这里的主要步骤其实还是和我们之前分析的一样,如下图所示:
这里再简单带大家看一下就行,重点是我们的第二部分。

既然网页结构我们已经分析完了,那么我还是选择用之前的xpath来爬取我们所需要的资源。
# 获取所有的主播信息
def getDatas(html):
datalist=[]
parse=parsel.Selector(html)
lis=parse.xpath('//li[@class="game-live-item"]').getall()
# print(lis)
for li in lis:
data = []
parse1=parsel.Selector(li)
img_src=parse1.xpath('//img[@class="pic"]/@data-original').get("data")
data.append(img_src)
title=parse1.xpath('//i[@class="nick"]/@title').get("data")
data.append(title)
redu=parse1.xpath('//i[@class="js-num"]/text()').get("data")
data.append(redu)
datalist.append(data)
return datalist
这样我们就能获取到我们所需要的所有资源,之后将图片保存下来即可。这其中有两种文件的下载方式,一种是通过 with open打开文件的方式 ,另外一种就是通过 urllib.request.urlretrieve(data,path) 的方法,网上说第二种方式的下载速度会相对快一点,并且第二种有点 set 集合的意思,可以自动进行 去重 的操作,下载的文件夹中没有该文件就下载,否则就跳过。
#保存主播头像
def download(datalist):
for data in datalist:
#第一种下载方式
with open("D:/software/python/python爬虫/虎牙颜值主播排名/", 'wb') as f:
f.write(data[0])
#第二种下载方式
urllib.request.urlretrieve(data[0],"D:/software/python/python爬虫/虎牙颜值主播排名"+"/"+data[1]+".jpg")
print(data[1]+"下载完成")
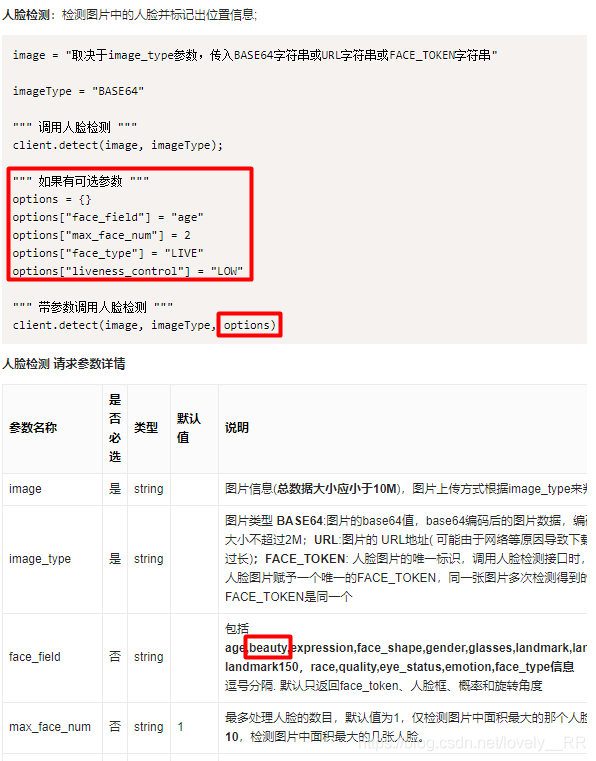
百度人脸识别接口
百度AI开放平台链接:https://ai.baidu.com/

输入相应的应用名称以及简介即可。

这样我们的应用就算创建完毕了。选中的部分也是我们接下来会用到的。
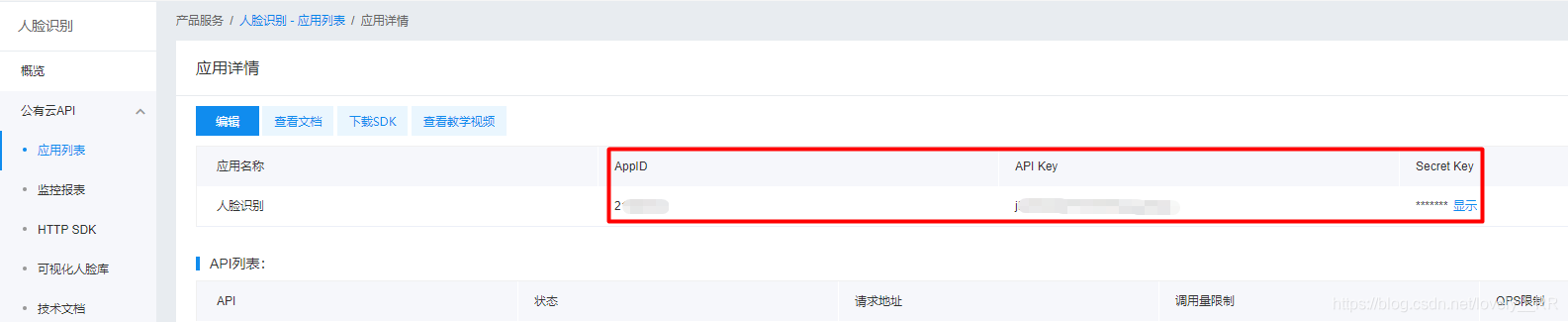
之后我们先去看一下sdk文件
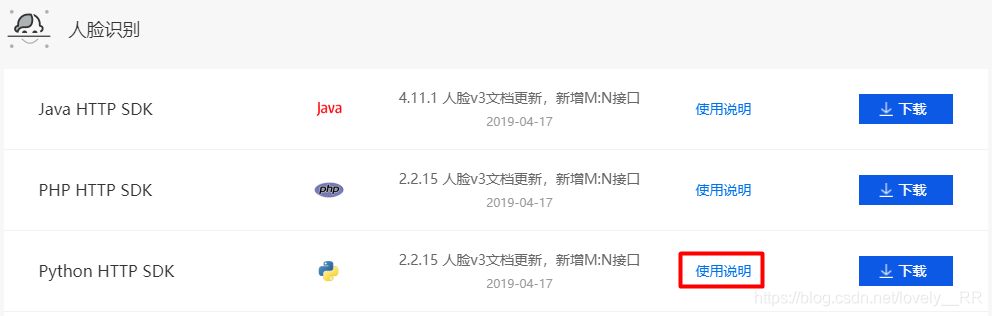
看使用说明即可,不用着急下载,之后我们直接在pycharm中安装模块就行。
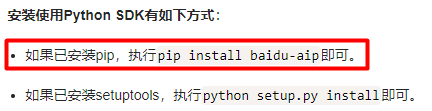
之后我们来看一下简单的操作流程首先先创建客户端:

之后我们就是调用接口解析图片,因为我们需要返回颜值分数这一个参数,所以还需要带参数进行请求,否则无法将分数信息返回给我们。如下图:
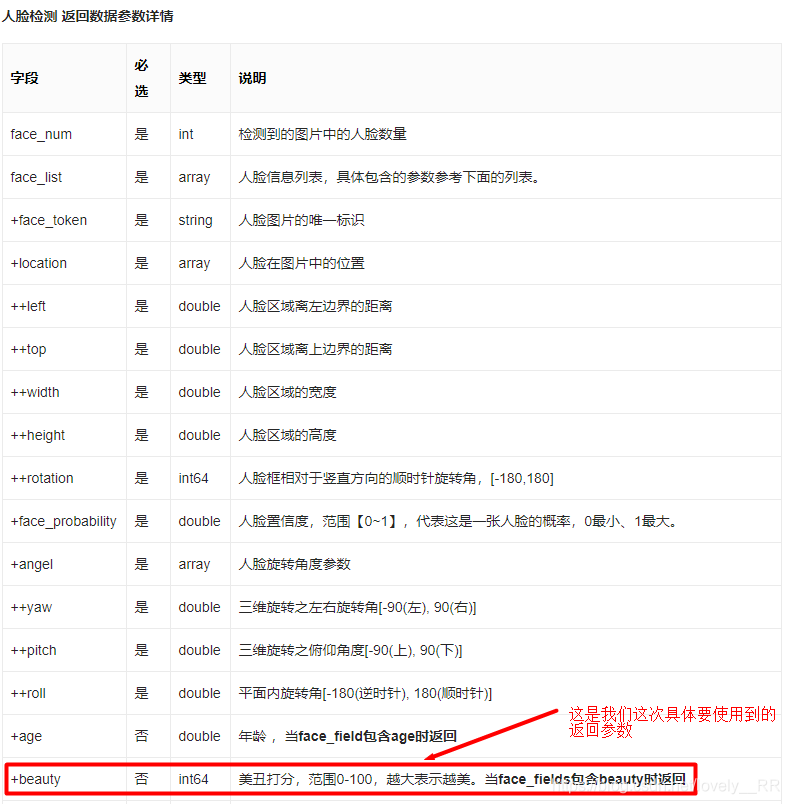
这样我们颜值检测的接口流程基本就已经理清楚了,代码如下:
def face_rg(file_path):
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipFace(APP_ID, API_KEY, SECRET_KEY)
with open(file_path,'rb')as file:
data=base64.b64encode(file.read())
image=data.decode()
imageType = "BASE64"
""" 如果有可选参数 """
options = {}
options["face_field"] = "beauty"
""" 带参数调用人脸检测 """
result=client.detect(image, imageType, options)
# print(result)
return result['result']['face_list'][0]['beauty']
之后我们就只需要编写一个遍历文件夹下面的图片进行检测,之后将整个信息按照颜值分数进行降序排列:
path=r"D:\software\python\python爬虫\虎牙颜值主播排名"
image_list=os.listdir(path)
name_score={}
for image in image_list:
try:
print(image.split(".")[0]+"颜值评分为:%d"%face_rg(path+"/"+image))
name_score[image.split(".")[0]]=face_rg(path+"/"+image)
except:
pass
second_score=sorted(name_score.items(),key=lambda x:x[1],reverse=True)
print("-------------------------------------检测结束-------------------------------------")
print("-------------------------------------以下是排名-------------------------------------")
for a,b in enumerate(second_score):
print("{}的颜值评分为:{},排名第{}".format(second_score[a][0],second_score[a][1],a+1))
这里博主测完自己的颜值是 52分,连及格线都没到 ,大家也可以在评论区说说自己的分数。

效果演示

到此这篇关于python爬虫看看虎牙女主播中谁最“顶”的文章就介绍到这了,更多相关python爬虫虎牙女主播内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python3爬虫之自动查询天气并实现语音播报
一.写在前面 之前写过一篇用Python发送天气预报邮件的博客,但是因为要手动输入城市名称,还要打开邮箱才能知道天气情况,这也太麻烦了.于是乎,有了这一篇博客,这次我要做的就是用Python获取本机IP地址,并根据这个IP地址获取物理位置也就是我所在的城市名称,然后用之前的办法实现查询天气,再利用百度语音得到天气预报的MP3文件,最后播放,这样是不是就很方(tou)便(lan)了呢? 二.具体步骤 这次有四个py文件:get_ip.py,get_wather.py,get_mp3.py和main
-
Python 爬虫实现增加播客访问量的方法实现
一.序言: 世界 1024 程序猿节日不加班,闲着没事儿...随手写了个播客访问量爬虫玩玩,访问量过万不是事儿!!!每个步骤注释都很清晰,代码仅供学习参考! ---- Nick.Peng 二.所需环境: Python3.x 相关模块: requests.json.lxml.urllib.bs4.fake_useragent 三.增加Blog访问量代码如下: #!/usr/bin/env python # -*- coding: utf-8 -*- # @Author: Nick # @Date:
-

python爬虫看看虎牙女主播中谁最“顶”步骤详解
网页链接:https://www.huya.com/g/4079 这里的主要步骤其实还是和我们之前分析的一样,如下图所示: 这里再简单带大家看一下就行,重点是我们的第二部分. 既然网页结构我们已经分析完了,那么我还是选择用之前的xpath来爬取我们所需要的资源. # 获取所有的主播信息 def getDatas(html): datalist=[] parse=parsel.Selector(html) lis=parse.xpath('//li[@class="game-live-item&q
-
python编程之requests在网络请求中添加cookies参数方法详解
哎,好久没有学习爬虫了,现在想要重新拾起来.发现之前学习爬虫有些粗糙,竟然连requests中添加cookies都没有掌握,惭愧.废话不宜多,直接上内容. 我们平时使用requests获取网络内容很简单,几行代码搞定了,例如: import requests res=requests.get("https://cloud.flyme.cn/browser/index.jsp") print res.content 你没有看错,真的只有三行代码.但是简单归简单,问题还是不少的. 首先,这
-
对python中Librosa的mfcc步骤详解
1.对语音数据归一化 如16000hz的数据,会将每个点/32768 2.计算窗函数:(*注意librosa中不进行预处理) 3.进行数据扩展填充,他进行的是镜像填充("reflect") 如原数据为 12345 -> 填充为4的,左右各填充4 即:5432123454321 即:5432-12345-4321 4.分帧 5.加窗:对每一帧进行加窗, 6.进行fft傅里叶变换 librosa中fft计算,可以使用.net中的System.Numerics MathNet.Nume
-
C#中添加窗口的步骤详解
C#中添加窗口的步骤:1是添加窗口.2是在程序中使用new实例化窗口类对象,并显示窗口. 1 添加窗口 在解决方案管理器->主项目名称->右键->添加->Windows窗体 2 实例化并显示窗口 //实例化窗口对象Form2 f2 = new Form2();//调用类成员函数Show()来显示窗口f2.Show(); 以上这篇C#中添加窗口的步骤详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Android在fragment中编写toobar的步骤详解
第一步的话就是首先导入我们的依赖的包: compile 'com.android.support:appcompat-v7:23.3.0' 第二步的话就是准备我们的布局文件和我们的item 在这的话我是将我们的toobar单独的放在一个布局文件中的方便以后的调用以及将我们的主题改为 我们noactionbar,同时在我们的主文件中进行引用 修改为nopactionbar 引用 设置单独的xml文件 然后的话就是我们在我们的这个位置设置的是我们的啊就是toobar的单独的一个文件代码如下: <?x
-
在CentOS 6.5环境中安装VPN 的步骤详解
想通过VPN上网,因为各种免费或收费的VPN工具不是不稳定就是怕不靠谱,所以打算自己搭一个玩玩.以下是搭建的大致过程: 因为只是做个实验环境,所以申请了一个腾讯云的15天免费服务器,以下是相关信息: 系统:CentOS 6.5 64位 公网IP:139.155.96.23 内网IP:172.27.0.12 系统资源:1 核 1 GB 1 Mbps 在网上找了很多教程,但搭完后上不了网,有点奇怪,后来找到一个简单版的教程才晓得是防火墙配置有问题.以下是按照这个简单版本的方式搭建的. 原文参考地址:
-
vue中引入mxGraph的步骤详解
第一步:下载npm包 npm install mxgraph --save 第二步:新建一个index.js文件 文件内容如下 import mx from 'mxgraph'; const mxgraph = mx({ mxImageBasePath: './src/images', mxBasePath: './src' }); // decode bug https://github.com/jgraph/mxgraph/issues/49 window.mxGraph = mxgraph
-
Java 添加、删除、替换、格式化Word中的文本的步骤详解(基于Spire.Cloud.SDK for Java)
Spire.Cloud.SDK for Java提供了TextRangesApi接口可通过addTextRange()添加文本.deleteTextRange()删除文本.updateTextRangeText()替换文本.updateTextRangeFormat()格式化文本等.本文将从以上方法介绍如何来实现对文本的操作.可参考以下步骤进行准备: 一.导入jar文件 创建Maven项目程序,通过maven仓库下载导入.以IDEA为例,新建Maven项目,在pom.xml文件中配置maven仓
-
Python入门开发教程 windows下搭建开发环境vscode的步骤详解
目录 一.环境介绍 二. 搭建python开发环境 2.1 Python版本介绍 2.2 在windows下安装Python环境 2.3 windows下安装VSCode代码编辑器 一.环境介绍 操作系统: win10 64位 python版本: 3.8 IDE: 采用vscode 用到的相关安装包CSDN打包下载地址: http://xiazai.jb51.net/202107/yuanma/Pytho_jb51.rar 二. 搭建python开发环境 2.1 Python版本介绍 因为Pyt
-
Python实现批量识别银行卡号码以及自动写入Excel表格步骤详解
每当有新员工入职,人事小姐姐都要收集大量的工资卡信息,并且生成Excel文档,看到小姐姐这么辛苦,我就忍不住要去帮她了… 于是我用1行代码就实现了自动识别银行卡信息并且自动生成Excel文件,小姐姐当场就亮眼汪汪的看着我,搞得我都害羞了~ 第一步:识别一张银行卡 识别银行卡的代码最简单,只需要1行腾讯云AI的第三方库potencent的代码,如下所示.左右滑动,查看全部. # pip install potencent import potencent # 可以填写本地图片的地址:img_pat