分页存储过程(二)在sqlserver中返回更加准确的分页结果
在我的使用SQL Server2005的新函数构造分页存储过程中,我提到了使用ROW_NUMBER()函数来代替top实现分页存储过程。
但是时间长了,又发现了新问题,就是主子表的分页查询。例如:订单表和订单明细表,要求是查询订单,第二页,每页10条
--使用row_unmber()实现分页
--本来我们想要的结果是10条订单,结果却不是10条订单,而是10条明细
--其实是针对的子表进行分页了,订单并不是要显示的个数,出来的个数是明细的个数
--就是因为主表和子表联合查询的结果,主表记录和子表记录是1:N的关系,一个主表记录有多个明细
select * from
(SELECT ROW_NUMBER () OVER (ORDER BY oi.createdate DESC) AS rownumber,oi.orderseqno ,od.OrderDetailID
FROM OrderInfo oi LEFT JOIN OrderDetail od ON oi.OrderSeqNO=od.OrderSeqNO
WHERE oi.OrderSeqNO LIKE '%2%'
) AS o
WHERE rownumber BETWEEN 10 AND 20
结果如下图
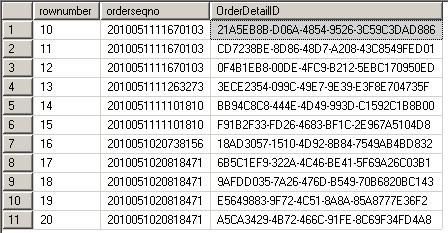
很明显不是10条订单,而是10条明细。
--解决上面的问题,有以下几种办法
--1、先根据条件查询主表记录,然后在C#代码中循环,再次到数据库查询每条主表记录的明细信息,然后赋值给属性
--2、在数据库的存储过程中使用游标,也是先查询主表记录,然后使用游标循环的过程中,查询子表信息,然后在C#中
--集中处理
--很显然,后一种减少了数据库的往来开销,一次获取了想要的数据,个人认为要比第一种好,欢迎大家一起讨论更好的办法
--需要注意的就是ROW_NUMBER()返回的类型是bigint,而不是int
--下面是游标的存储过程
--建立主表临时表
CREATE TABLE #temp
(
rownumber bigint,
orderseqno VARCHAR(36),
goodsname VARCHAR(50),
companyname VARCHAR(100)
)
--建立子表临时表
CREATE TABLE #detail
(
orderseqno VARCHAR(36),
detailid UNIQUEIDENTIFIER,
unitprice DECIMAL(12,2),
Qty int
)
--插入主表数据到主表临时表
insert into #temp
SELECT oo.rownumber, oo.OrderSeqNO, oo.GoodsName, oo.CompanyName FROM
(SELECT ROW_NUMBER () OVER (ORDER BY oi.createdate DESC) AS rownumber,
oi.OrderSeqNO, oi.GoodsName ,ci.CompanyName
FROM OrderInfo oi INNER JOIN CompanyInfo ci ON oi.CompanyID=ci.CompanyID
WHERE oi.CreateDate<GETDATE()
) AS oo
WHERE rownumber BETWEEN 10 AND 20
--定义游标
DECLARE @temp_cursor CURSOR
--给游标赋值
SET @temp_cursor=CURSOR FOR SELECT #temp.orderseqno,#temp.goodsname FROM #temp
--定义游标循环过程中所需保存的临时数据
DECLARE @orderseqno VARCHAR(36),@goodsname varchar(50)
--打开游标
OPEN @temp_cursor
FETCH NEXT FROM @temp_cursor INTO @orderseqno,@goodsname
--循环游标,查询子表数据,然后插入子表临时表
WHILE @@FETCH_STATUS=0
BEGIN
INSERT INTO #detail
SELECT od.OrderSeqNO,od.OrderDetailID, od.UnitPrice,od.Qty
FROM OrderDetail od
WHERE od.OrderSeqNO=@orderseqno
FETCH NEXT FROM @temp_cursor INTO @orderseqno,@goodsname
END
--关闭游标
CLOSE @temp_cursor
DEALLOCATE @temp_cursor
SELECT * FROM #temp
SELECT * FROM #detail
--删除临时表
DROP TABLE #temp
DROP TABLE #detail
结果如下图,马上看到效果就变了,欢迎大家一起讨论更好的,更精准的分页查询。
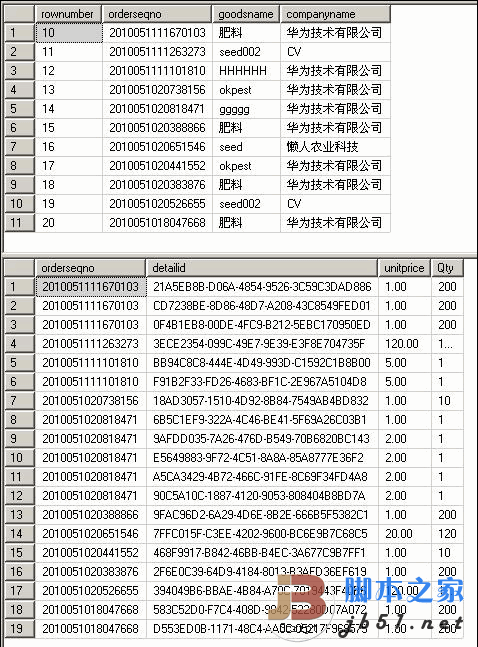
上面的T-SQL只在SQL Server 2005上调试成功。
推荐一篇MS SQL Server的查询计划的相关内容,可以利用它优化SQL,写的不错。引用:SqlServer 执行计划及Sql查询优化初探