C语言静态链表和动态链表
1. 静态链表
结构体中的成员可以是各种类型的指针变量,当一个结构体中有一个或多个成员的基类型是本结构体类型时,则称这种结构体为“引用自身的结构体”。如:
struct link
{
char ch;
struct link *p;
} a;
p是一个可以指向 struct link 类型变量的指针成员。因此,a.p = &a 是合法的表达式,由此构成的存储结构如图1所示。
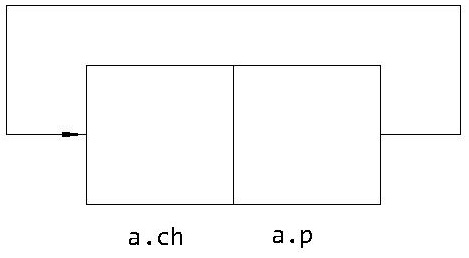
图1 引用自身的结构体
例1 一个简单的链表
#include <stdio.h>
struct node
{
int data;
struct node *next;
};
typedef struct node NODETYPE;
int main()
{
//a是头结点,b是中间节点,c是尾节点
//h是基类型为NODETYPE的指针,指向头结点
//p是基类型为NODETYPE的指针,用于遍历链表
NODETYPE a, b, c, *h, *p;
//给变量中的data赋值
a.data = 10;
b.data = 20;
c.data = 30;
//将节点相连
h = &a;
a.next = &b;
b.next = &c;
c.next = '\0';
//移动p,使之依次指向a、b、c,输出它们data中的值
p = h;
while (p)
{
printf("%d\t", p->data);
p = p->next; //p顺序后移
}
printf("\n");
return 0;
}
STRUCT_LIST
STRUCT_LIST
以上程序中所定义的结构体类型 NODETYPE 共有两个成员:成员 data 是整型;成员 next 是指针类型,其基类型是 NODETYPE 类型。
a、b、c 是 NODETYPE 结构体类型变量,h 和 p 是指向 NODETYPE 结构体类型的指针变量。执行程序后,形成如图2所示的存储结构体:指针 h 中存放变量 a 的地址,变量 a 的成员 a.next 中存放变量 b 的地址……,最后一个变量 c 的成员 c.next 置为 '\0'(NULL)。这样就把同一类型的结构体变量 a、b、c “链接”到一起,形成所谓的“链表”,变量 a、b、c 称为链表的节点。
在此例中,链接到一起的每个节点(结构体变量 a、b、c)都是通过定义,由系统在内存中开辟了固定的、不一定连续的存储单元。在程序执行过程中,不可能人为的再产生新的存储单元,也不能认为的使已开辟的存储单元消失。这种链表成为“静态链表”。

图2 链表存储结构示意图
2.动态链表的概念
到目前为止,凡是遇到处理“批量”数据时,我们都是利用数组来存储。定义数组必须(显式的或隐含的)指明元素的个数,从而也就限定了一个数组中存放的数据量。在实际应用中,一个程序在每次运行时要处理的数据的数目通常并不确定。如果数组定义的小了,就没有足够的空间存放数据,定义大了又浪费存储空间。
对于这种情况,如果能在程序执行过程中,根据需要随时开辟存储空间,不需要时再随时释放,就能比较合理的使用存储空间。C 语言的动态存储分配提供了这种可能性。每次动态分配的存储单元,其地址不一定是连续的,而所需处理的批量数据往往是一个整体,各数据之间存在着接序关系。链表的每个节点中,除了要有存放数据本身的数据域外,至少还需要有一个指针域,用它来存放下一个节点元素的地址,以便通过这些指针把各节点连接起来(如图3)。由于链表每个存储单元都由动态存储分配获得,故称这样的链表为“动态链表”。
需要强调的是:动态链表中,每个节点没有自己的名字,只能靠指针维系节点之间的接序关系。一旦某个节点的指针“断开”,后续节点就再也无法找寻。
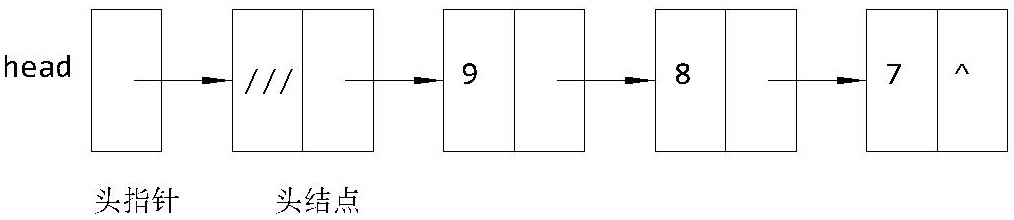
图3 带有头结点的单向链表
每个链表都用一个“头指针”变量来指向链表的开始,如图3中的 head。也就是说,在 head 中存放了链表的第一个节点的地址。在这个链表中,我们设置了一个“头结点”,这个节点的数据域中不存放数据(根据需要也可以不设头结点)。链表最后一个节点的指针域不存放地址,置为 '\0'(NULL) 值,标志着链表的结束。上述链表的每个节点都只有一个指针域,每个指针域存放着下一个节点的地址。因此,这种链表只能从当前节点找到后继节点,故称为“单向链表”。
相关推荐
-
C语言实现支持动态拓展和销毁的线程池
本文实例介绍了C 语言实现线程池,支持动态拓展和销毁,分享给大家供大家参考,具体内容如下 实现功能 1.初始化指定个数的线程 2.使用链表来管理任务队列 3.支持拓展动态线程 4.如果闲置线程过多,动态销毁部分线程 #include <stdio.h> #include <pthread.h> #include <stdlib.h> #include <signal.h> /*线程的任务队列由,函数和参数组成,任务由链表来进行管理*/ typedef str
-
C语言 动态内存分配的详解及实例
1. 动态内存分配的意义 (1)C 语言中的一切操作都是基于内存的. (2)变量和数组都是内存的别名. ①内存分配由编译器在编译期间决定 ②定义数组的时候必须指定数组长度 ③数组长度是在编译期就必须确定的 (3)但是程序运行的过程中,可能需要使用一些额外的内存空间 2. malloc 和 free 函数 (1)malloc 和 free 用于执行动态内存分配的释放 (2)malloc 所分配的是一块连续的内存 (3)malloc 以字节为单位,并且返回值不带任何的类型信息:void* mallo
-
C语言构建动态数组完整实例
本文以一个完整的实例代码简述了C语言构建动态数组的方法,供大家参考,完整实例如下: #include <stdio.h> #include <malloc.h> int main(void) { int len; int * arr; printf("请输入数组长度:"); scanf("%d", &len); arr = (int *)malloc(sizeof(int)*len); printf("请输入数组的值:&qu
-
在C语言中调用C++做的动态链接库
今天在做东西的时候遇到一个问题,就是如何在C语言中调用C++做的动态链接库so文件 如果你有一个c++做的动态链接库.so文件,而你只有一些相关类的声明, 那么你如何用c调用呢,别着急,本文通过一个小小的例子,让你能够很爽的搞定. 链接库头文件: head.h class A { public: A(); virtual ~A(); int gt(); int pt(); private: int s; }; firstso.cpp #include <iostream> #include &
-
C语言创建链表错误之通过指针参数申请动态内存实例分析
本文实例讲述了C语言创建链表中经典错误的通过指针参数申请动态内存,分享给大家供大家参考之用.具体实例如下: #include <stdio.h> #include <stdlib.h>// 用malloc要包含这个头文件 typedef struct node { int data; struct node* next;// 这个地方注意结构体变量的定义规则 } Node; void createLinklist(Node* pHder, int length) { int i =
-
c语言动态数组示例
复制代码 代码如下: #include <stdio.h>#include <stdlib.h> int main(){ //从控制台获取初始数组大小 int N; printf("Input array length:"); scanf("%d",&N); printf("\n"); //分配空间 int *a; a=(int *)calloc(N,sizeof(int)
-
使用C语言实现vector动态数组的实例分享
下面是做项目时实现的一个动态数组,先后加入了好几个之后的项目,下面晒下代码. 头文件: # ifndef __CVECTOR_H__ # define __CVECTOR_H__ # define MIN_LEN 256 # define CVEFAILED -1 # define CVESUCCESS 0 # define CVEPUSHBACK 1 # define CVEPOPBACK 2 # define CVEINSERT 3 # define CVERM 4 # define EXP
-
C语言使用DP动态规划思想解最大K乘积与乘积最大问题
最大K乘积问题 设I是一个n位十进制整数.如果将I划分为k段,则可得到k个整数.这k个整数的乘积称为I的一个k乘积.试设计一个算法,对于给定的I和k,求出I的最大k乘积. 编程任务: 对于给定的I 和k,编程计算I 的最大k 乘积. 需求输入: 输入的第1 行中有2个正整数n和k.正整数n是序列的长度:正整数k是分割的段数.接下来的一行中是一个n位十进制整数.(n<=10) 需求输出: 计算出的最大k乘积. 解题思路:DP 设w(h,k) 表示: 从第1位到第K位所组成的十进制数,设m(i,j)
-
C语言完美实现动态数组代码分享
我们知道,C语言中的数组大小是固定的,定义的时候必须要给一个常量值,不能是变量. 这带来了很大的不便,如果数组过小,不能容下所有数组,如果过大,浪费资源. 请实现一个简单的动态数组,能够随时改变大小,不会溢出,也不会浪费内存空间. 下面的代码实现了简单的动态数组: #include <stdio.h> #include <stdlib.h> int main() { //从控制台获取初始数组大小 int N; int *a; int i; printf("Input ar
-

老生常谈C语言动态函数库的制作和使用(推荐)
>>>>>>老生常谈C语言接静态函数库的制作和使用>>点击进入 2 动态函数库的制作和使用 动态函数库的制作步骤可以用下图来描述,具体包括 (1) 编写函数的.c文件(例如add.c.sub.c.mul.c和div.c) (2) 编写Makefile,然后make,实现函数的编译和归档入库 函数的编译:使用gcc –c add.c -fPIC只编译不链接函数.c文件,分别生成函数的目标文件(例如add.o.sub.o.mul.o和div.o). 函数的归档入