SQLSERVER2008中CTE的Split与CLR的性能比较
我们新建一个DataBase project,然后建立一个UserDefinedFunctions,Code像这样:
代码如下:
1: /// <summary>
/// SQLs the array.
/// </summary>
/// <param name="str">The STR.</param>
/// <param name="delimiter">The delimiter.</param>
/// <returns></returns>
/// 1/8/2010 2:41 PM author: v-pliu
[SqlFunction(Name = "CLR_Split",
FillRowMethodName = "FillRow",
TableDefinition = "id nvarchar(10)")]
public static IEnumerable SqlArray(SqlString str, SqlChars delimiter)
{
if (delimiter.Length == 0)
return new string[1] { str.Value };
return str.Value.Split(delimiter[0]);
}
/// <summary>
/// Fills the row.
/// </summary>
/// <param name="row">The row.</param>
/// <param name="str">The STR.</param>
/// 1/8/2010 2:41 PM author: v-pliu
public static void FillRow(object row, out SqlString str)
{
str = new SqlString((string)row);
}
然后Bulid,Deploy一切OK后,在SSMS中执行以下测试T-sql:
代码如下:
DECLARE @array VARCHAR(max)
SET @array = '39,15,93,68,64,43,90,58,39,9,26,26,89,47,91,57,98,16,55,9,63,29,69,16,41,76,34,60,68,64,61,53,32,30,11,72,57,63,36,43,22,14,60,38,24,5,66,26,26,21,22,99,55,18,7,10,46,76,27,88,9,29,89,75,48,72,94,59,35,19,0,35,79,11,87,49,68,30,91,35,9,7,34,47,41,61,98,13,22,1,26,80,35,48,34,92,24,85,90,51' SELECT id FROM dbo.CLR_Split(@array,',')
我们来看它的Client Statistic:
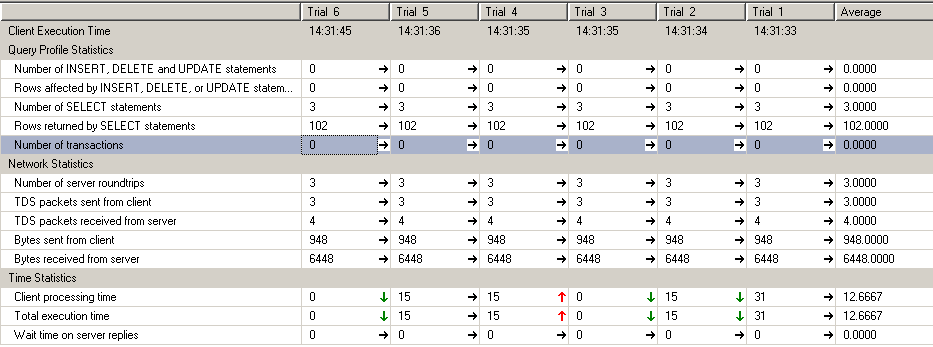
接着我们执行测试T-sql使用相同的array:
代码如下:
DECLARE @array VARCHAR(max)
SET @array = '39,15,93,68,64,43,90,58,39,9,26,26,89,47,91,57,98,16,55,9,63,29,69,16,41,76,34,60,68,64,61,53,32,30,11,72,57,63,36,43,22,14,60,38,24,5,66,26,26,21,22,99,55,18,7,10,46,76,27,88,9,29,89,75,48,72,94,59,35,19,0,35,79,11,87,49,68,30,91,35,9,7,34,47,41,61,98,13,22,1,26,80,35,48,34,92,24,85,90,51'
SELECT item FROM strToTable(@array,',')
CTE实现的Split function的Client statistic:
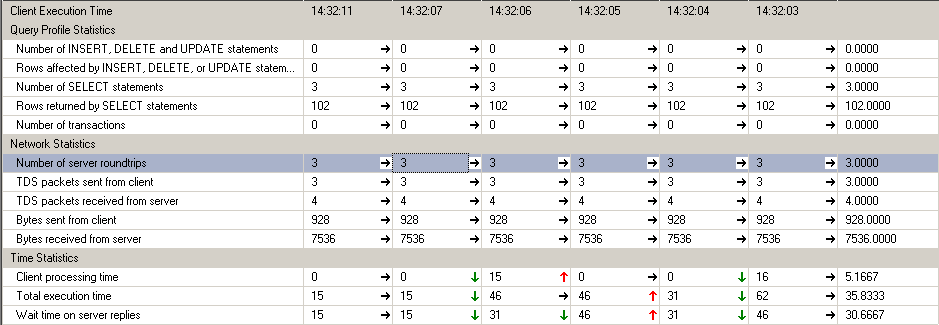
通过对比,你可以发现CLR的performance略高于CTE方式,原因在于CLR方式有Cache功能,并且把一个复杂的运算放到程序里比DataBase里更加高效。
您还可以参考:
Split string in SQL Server 2005+ CLR vs. T-SQL
Author:Petter Liu
相关推荐
-
SqlServer使用公用表表达式(CTE)实现无限级树形构建
SQL Server 2005开始,我们可以直接通过CTE来支持递归查询,CTE即公用表表达式 公用表表达式(CTE),是一个在查询中定义的临时命名结果集将在from子句中使用它.每个CTE仅被定义一次(但在其作用域内可以被引用任意次),并且在该查询生存期间将一直生存.可以使用CTE来执行递归操作. DECLARE @Level INT=3 ;WITH cte_parent(CategoryID,CategoryName,ParentCategoryID,Level) AS ( SELECT c
-
SQLSERVER2005 中树形数据的递归查询
问题描述.借用了adinet的问题.参见:http://www.jb51.net/article/28670.htm 今天做项目遇到一个问题, 有产品分类A,B,C顶级分类, 期中A下面有a1,a2,a3子分类. 但是a1可能共同属于A和B,然后我的数据库是这样设计的 id name parnet 1 A 0 2 B 0 3 a1 1,2 如果想要查询A的所有子类的话就要查询parent中包含1的,所以就萌生了这个办法.呵呵,解决方案 复制代码
-
在sqlserver中如何使用CTE解决复杂查询问题
最近,同事需要从数个表中查询用户的业务和报告数据,写了一个SQL语句,查询比较慢: Select S.Name, S.AccountantCode, ( Select COUNT(*) from ( Select Distinct BusinessBackupId from Biz_BusinessBackupCustomer where Id in ( Select BusinessBackupCustomerId from Rpt_RegistForm where ( SignatureCP
-
使用SqlServer CTE递归查询处理树、图和层次结构
CTE(Common Table Expressions)是从SQL Server 2005以后版本才有的.指定的临时命名结果集,这些结果集称为CTE. 与派生表类似,不存储为对象,并且只在查询期间有效.与派生表的不同之处在于,CTE 可自引用,还可在同一查询中引用多次.使用CTE能改善代码可读性,且不损害其性能. 递归CTE是SQL SERVER 2005中重要的增强之一.一般我们在处理树,图和层次结构的问题时需要用到递归查询. CTE的语法如下 WITH CTE AS ( SELECT Em
-

使用SQLSERVER 2005/2008 递归CTE查询树型结构的方法
下面是一个简单的Family Tree 示例: 复制代码 代码如下: DECLARE @TT TABLE (ID int,Relation varchar(25),Name varchar(25),ParentID int) INSERT @TT SELECT 1,' Great GrandFather' , 'Thomas Bishop', null UNION ALL SELECT 2,'Grand Mom', 'Elian Thomas Wilson' , 1 UNION ALL SELE
-
sqlserver另类非递归的无限级分类(存储过程版)
下面是我统计的几种方案: 第一种方案(递归式): 简单的表结构为: CategoryID int(4), CategoryName nvarchar(50), ParentID int(4), Depth int(4) 这样根据ParentID一级级的运用递归找他的上级目录. 还有可以为了方便添加CategoryLeft,CategoryRight保存他的上级目录或下级目录 第二种方案: 设置一个varchar类型的CategoryPath字段来保存目录的完整路径,将父目录id用符号分隔开来.比
-
SQLSERVER2008中CTE的Split与CLR的性能比较
我们新建一个DataBase project,然后建立一个UserDefinedFunctions,Code像这样: 复制代码 代码如下: 1: /// <summary> /// SQLs the array. /// </summary> /// <param name="str">The STR.</param> /// <param name="delimiter">The delimiter.&l
-
Java中String的split切割字符串方法实例及扩展
目录 一.public String[] split(String regex) 二.public String[] split(String regex, int limit) 三.扩展 总结 一.public String[] split(String regex) public String[] split(String regex): 根据传入的字符串参数,作为规则,切割当前字符串 String a="198,168,10,1"; String [] arr=a.split(&
-
MySQL中distinct与group by之间的性能进行比较
最近在网上看到了一些测试,感觉不是很准确,今天亲自测试了一番.得出了结论,测试过程在个人计算机上,可能不够全面,仅供参考. 测试过程: 准备一张测试表 CREATE TABLE `test_test` ( `id` int(11) NOT NULL auto_increment, `num` int(11) NOT NULL default '0', PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1
-
对python中两种列表元素去重函数性能的比较方法
测试函数: 第一种:list的set函数 第二种:{}.fromkeys().keys() 测试代码: #!/usr/bin/python #-*- coding:utf-8 -*- import time import random l1 = [] leng = 10L for i in range(0,leng): temp = random.randint(1,10) l1.append(temp) print '测试列表长度为:',leng #first set last = time.
-
关于SQL中CTE(公用表表达式)(Common Table Expression)的总结
一.WITH AS的含义 WITH AS短语,也叫做子查询部分(subquery factoring),可以让你做很多事情,定义一个SQL片断,该SQL片断会被整个SQL语句所用到.有的时候,是为了让SQL语句的可读性更高些,也有可能是在UNION ALL的不同部分,作为提供数据的部分. 特别对于UNION ALL比较有用.因为UNION ALL的每个部分可能相同,但是如果每个部分都去执行一遍的话,则成本太高,所以可以使用WITH AS短语,则只要执行一遍即可.如果WITH AS短语所定义的表名
-
深入浅析Python中join 和 split详解(推荐)
python join 和 split方法简单的说是:join用来连接字符串,split恰好相反,拆分字符串的. .join() join将 容器对象 拆分并以指定的字符将列表内的元素(element)连接起来,返回字符串(注:容器对象内的元素须为字符类型) >>> a = ['no','pain','no','gain'] >>> '_ '.join(a) 'no_pain_no_gain' >>> 注:容器对象内的元素须为字符类型 >>
-
jQuery中filter(),not(),split()使用方法
filter()和not(): 复制代码 代码如下: <script type="text/javascript"> $(document).ready(function() { //输出 hello alert($("p").filter(".selected").html()); //输出 How are you? alert($("p").not(".selected").html());
-
javascript中slice(),splice(),split(),substring(),substr()使用方法
1.slice(): Array和String对象都有 在Array中 slice(i,[j]) i为开始截取的索引值,负数代表从末尾算起的索引值,-1为倒数第一个元素 j为结束的索引值,缺省时则获取从i到末尾的所有元素 参数返回: 返回索引值从i到j的数组,原数组不改变 在String中 slice(i,[j]) 参数说明: i为开始截取的索引值,负数代表从末尾算起的索引值,-1为倒数第一个字符 j为结束的索引值,缺省时则获取从i到末尾的所有字符 2.splice() 存在Array中
-
php中explode与split的区别介绍
首先来看下两个方法的定义: 函数原型:array split (string $pattern, string $string [, int $limit]) 函数原型:array explode ( string $separator, string $string [, int $limit]) 初看没有啥差别,貌似功能都一样.我就犯了这个错误. 请注意两个函数的第一个参数string $pattern和string separator,一个是$pattern说明是正则字符串,一个是$sep
-
Python中join和split用法实例
join用来连接字符串,split恰好相反,拆分字符串的. 不用多解释,看完代码,其意自现了. 复制代码 代码如下: >>>li = ['my','name','is','bob'] >>>' '.join(li) 'my name is bob' >>>s = '_'.join(li) >>>s 'my_name_is_bob' >>>s.split('_') ['my', 'name', 'is', 'bob']