使用Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载。刚开始学习python希望可以获得宝贵的意见。
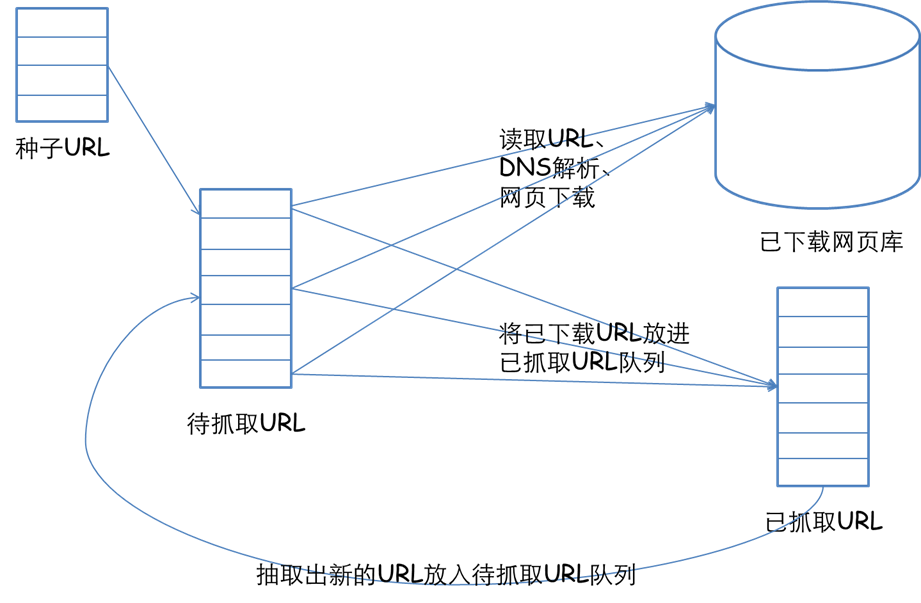
先来简单介绍一下,网络爬虫的基本实现原理吧。一个爬虫首先要给它一个起点,所以需要精心选取一些URL作为起点,然后我们的爬虫从这些起点出发,抓取并解析所抓取到的页面,将所需要的信息提取出来,同时获得的新的URL插入到队列中作为下一次爬取的起点。这样不断地循环,一直到获得你想得到的所有的信息爬虫的任务就算结束了。我们通过一张图片来看一下。
好的 下面进入正题,来讲解下程序的实现。
首先要分析一下电影天堂网站的首页结构。

从上面的菜单栏中我们可以看到整个网站资源的总体分类情况。刚刚好我们可以利用到它的这个分类,将每一个分类地址作为爬虫的起点。
①解析首页地址 提取分类信息
#解析首页
def CrawIndexPage(starturl):
print "正在爬取首页"
page = __getpage(starturl)
if page=="error":
return
page = page.decode('gbk', 'ignore')
tree = etree.HTML(page)
Nodes = tree.xpath("//div[@id='menu']//a")
print "首页解析出地址",len(Nodes),"条"
for node in Nodes:
CrawledURLs = []
CrawledURLs.append(starturl)
url=node.xpath("@href")[0]
if re.match(r'/html/[A-Za-z0-9_/]+/index.html', url):
if __isexit(host + url,CrawledURLs):
pass
else:
try:
catalog = node.xpath("text()")[0].encode("utf-8")
newdir = "E:/电影资源/" + catalog
os.makedirs(newdir.decode("utf-8"))
print "创建分类目录成功------"+newdir
thread = myThread(host + url, newdir,CrawledURLs)
thread.start()
except:
pass
在这个函数中,首先将网页的源码下载下来,通过XPath解析出其中的菜单分类信息。并创建相应的文件目录。有一个需要注意的地方就是编码问题,但是也是被这个编码纠缠了好久,通过查看网页的源代码,我们可以发现,网页的编码采用的是GB2312,这里通过XPath构造Tree对象是需要对文本信息进行解码操作,将gb2312变成Unicode编码,这样DOM树结构才是正确的,要不然在后面解析的时候就会出现问题。
②解析每个分类的主页
# 解析分类文件
def CrawListPage(indexurl,filedir,CrawledURLs):
print "正在解析分类主页资源"
print indexurl
page = __getpage(indexurl)
if page=="error":
return
CrawledURLs.append(indexurl)
page = page.decode('gbk', 'ignore')
tree = etree.HTML(page)
Nodes = tree.xpath("//div[@class='co_content8']//a")
for node in Nodes:
url=node.xpath("@href")[0]
if re.match(r'/', url):
# 非分页地址 可以从中解析出视频资源地址
if __isexit(host + url,CrawledURLs):
pass
else:
#文件命名是不能出现以下特殊符号
filename=node.xpath("text()")[0].encode("utf-8").replace("/"," ")\
.replace("\\"," ")\
.replace(":"," ")\
.replace("*"," ")\
.replace("?"," ")\
.replace("\""," ")\
.replace("<", " ") \
.replace(">", " ")\
.replace("|", " ")
CrawlSourcePage(host + url,filedir,filename,CrawledURLs)
pass
else:
# 分页地址 从中嵌套再次解析
print "分页地址 从中嵌套再次解析",url
index = indexurl.rfind("/")
baseurl = indexurl[0:index + 1]
pageurl = baseurl + url
if __isexit(pageurl,CrawledURLs):
pass
else:
print "分页地址 从中嵌套再次解析", pageurl
CrawListPage(pageurl,filedir,CrawledURLs)
pass
pass
打开每一个分类的首页会发现都有一个相同的结构(点击打开示例)首先解析出包含资源URL的节点,然后将名称和URL提取出来。这一部分有两个需要注意的地方。一是因为最终想要把资源保存到一个txt文件中,但是在命名时不能出现一些特殊符号,所以需要处理掉。二是一定要对分页进行处理,网站中的数据都是通过分页这种形式展示的,所以如何识别并抓取分页也是很重要的。通过观察发现,分页的地址前面没有“/”,所以只需要通过正则表达式找出分页地址链接,然后嵌套调用即可解决分页问题。
③解析资源地址保存到文件中
#处理资源页面 爬取资源地址
def CrawlSourcePage(url,filedir,filename,CrawledURLs):
print url
page = __getpage(url)
if page=="error":
return
CrawledURLs.append(url)
page = page.decode('gbk', 'ignore')
tree = etree.HTML(page)
Nodes = tree.xpath("//div[@align='left']//table//a")
try:
source = filedir + "/" + filename + ".txt"
f = open(source.decode("utf-8"), 'w')
for node in Nodes:
sourceurl = node.xpath("text()")[0]
f.write(sourceurl.encode("utf-8")+"\n")
f.close()
except:
print "!!!!!!!!!!!!!!!!!"
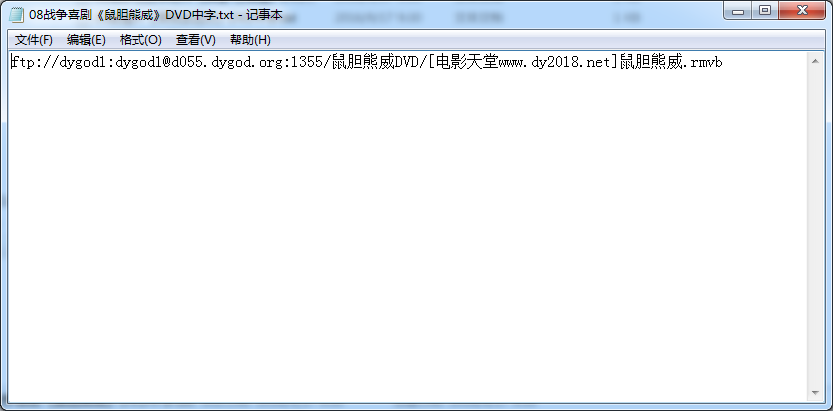
这段就比较简单了,将提取出来的内容写到一个文件中就行了
为了能够提高程序的运行效率,使用了多线程进行抓取,在这里我是为每一个分类的主页都开辟了一个线程,这样极大地加快了爬虫的效率。想当初,只是用单线程去跑,结果等了一下午最后因为一个异常没处理到结果一下午都白跑了!!!!心累
class myThread (threading.Thread): #继承父类threading.Thread def __init__(self, url, newdir,CrawledURLs): threading.Thread.__init__(self) self.url = url self.newdir = newdir self.CrawledURLs=CrawledURLs def run(self): #把要执行的代码写到run函数里面 线程在创建后会直接运行run函数 CrawListPage(self.url, self.newdir,self.CrawledURLs)
以上只是部分代码,全部代码可以到GitHub上面去下载(点我跳转)
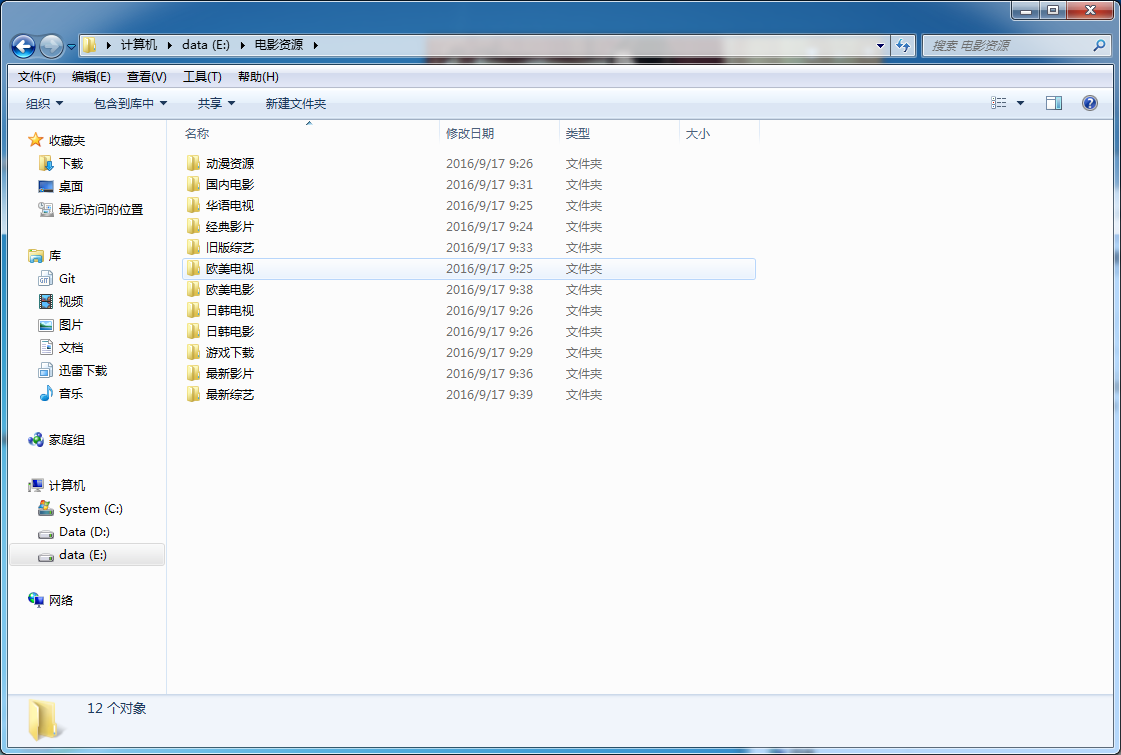
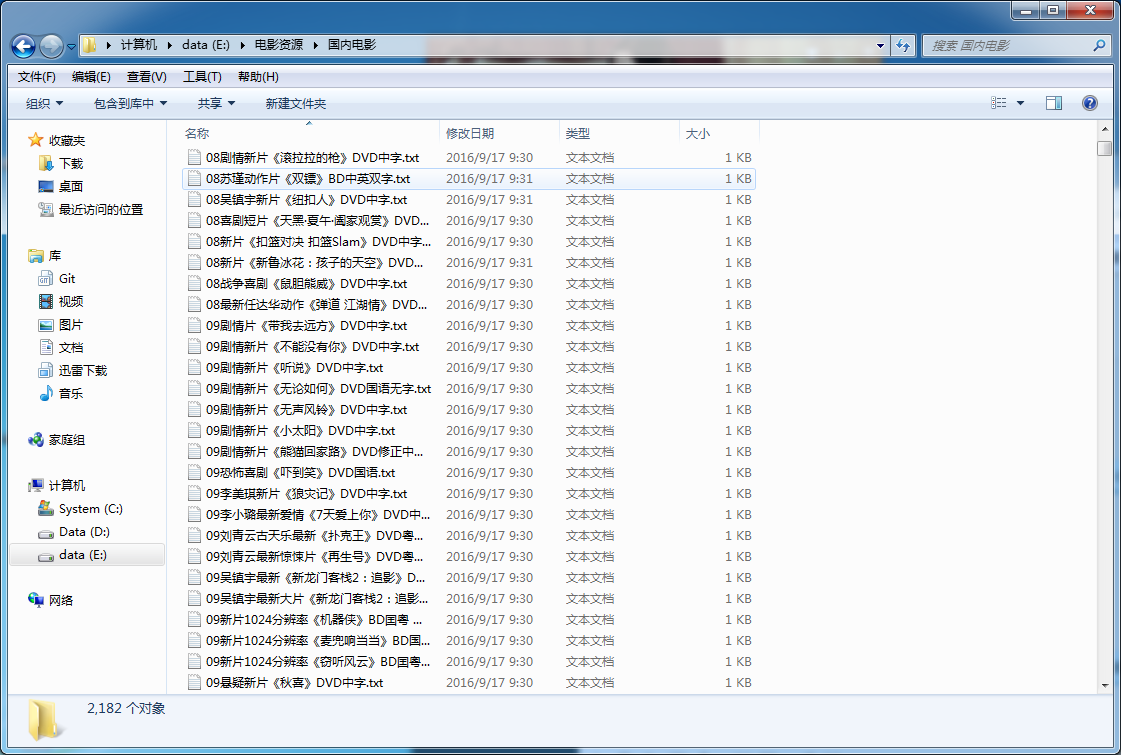
最后爬取的结果如下。
以上所述是小编给大家介绍的使用Python多线程爬虫爬取电影天堂资源 ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
python脚本爬取字体文件的实现方法
前言 大家应该都有所体会,为了提高验证码的识别准确率,我们当然要首先得到足够多的测试数据.验证码下载下来容易,但是需要人脑手工识别着实让人受不了,于是我就想了个折衷的办法--自己造验证码. 为了保证多样性,首先当然需要不同的字模了,直接用类似ttf格式的字体文件即可,网上有很多ttf格式的字体包供我们下载.当然,我不会傻到手动下载解压缩,果断要写个爬虫了. 实现方法 网站一:fontsquirrel.com 这个网站的字体可以免费下载,但是有很多下载点都是外链连接到其他网站的,这部分得忽略掉.
-

利用Python爬取可用的代理IP
前言 就以最近发现的一个免费代理IP网站为例:http://www.xicidaili.com/nn/.在使用的时候发现很多IP都用不了. 所以用Python写了个脚本,该脚本可以把能用的代理IP检测出来. 脚本如下: #encoding=utf8 import urllib2 from bs4 import BeautifulSoup import urllib import socket User_Agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv
-
python动态网页批量爬取
四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页.我使用的是学信网,好了,网站截图如下: 网站的代码如下: <form method="get" name="form1" id="form1" action="/cet/query"> <table border=&qu
-
Python使用Scrapy爬取妹子图
Python Scrapy爬虫,听说妹子图挺火,我整站爬取了,上周一共搞了大概8000多张图片.和大家分享一下. 核心爬虫代码 # -*- coding: utf-8 -*- from scrapy.selector import Selector import scrapy from scrapy.contrib.loader import ItemLoader, Identity from fun.items import MeizituItem class MeizituSpider(sc
-
python爬虫教程之爬取百度贴吧并下载的示例
测试url:http://tieba.baidu.com/p/27141123322?pn=begin 1end 4 复制代码 代码如下: import string ,urllib2 def baidu_tieba(url,begin_page,end_page): for i in range(begin_page, end_page+1): sName = string.zfill(i,5)+ '.html' print '正在下载第' + str(
-
python爬取网站数据保存使用的方法
编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了.问题要从文字的编码讲起.原本的英文编码只有0~255,刚好是8位1个字节.为了表示各种不同的语言,自然要进行扩充.中文的话有GB系列.可能还听说过Unicode和UTF-8,那么,它们之间是什么关系呢?Unicode是一种编码方案,又称万国码,可见其包含之广.但是具体存储到计算机上,并不用这种编码,可以说它起着一个中间人的作用.你可以再把Unicode编码(encode)为UTF-8,或者GB,再存储到计算机
-
python 爬取微信文章
本人想搞个采集微信文章的网站,无奈实在从微信本生无法找到入口链接,网上翻看了大量的资料,发现大家的做法总体来说大同小异,都是以搜狗为入口.下文是笔者整理的一份python爬取微信文章的代码,有兴趣的欢迎阅读 #coding:utf-8 author = 'haoning' **#!/usr/bin/env python import time import datetime import requests** import json import sys reload(sys) sys.setd
-
Python实现爬取知乎神回复简单爬虫代码分享
看知乎的时候发现了一个 "如何正确地吐槽" 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到全部的,于是就开始动手了. 工具 1.Python 2.7 2.BeautifulSoup 分析网页 我们先来看看知乎上该网页的情况 网址:,容易看到,网址是有规律的,page慢慢递增,这样就能够实现全部爬取了. 再来看一下我们要爬取的内容: 我们要爬取两个内容:问题和回答,回答仅限于显示
-
python实现爬取千万淘宝商品的方法
本文实例讲述了python实现爬取千万淘宝商品的方法.分享给大家供大家参考.具体实现方法如下: import time import leveldb from urllib.parse import quote_plus import re import json import itertools import sys import requests from queue import Queue from threading import Thread URL_BASE = 'http://s
-
Python爬取Coursera课程资源的详细过程
有时候我们需要把一些经典的东西收藏起来,时时回味,而Coursera上的一些课程无疑就是经典之作.Coursera中的大部分完结课程都提供了完整的配套教学资源,包括ppt,视频以及字幕等,离线下来后会非常便于学习.很明显,我们不会去一个文件一个文件的下载,只有傻子才那么干,程序员都是聪明人! 那我们聪明人准备怎么办呢?当然是写一个脚本来批量下载了.首先我们需要分析一下手工下载的流程:登录自己的Coursera账户(有的课程需要我们登录并选课后才能看到相应的资源),在课程资源页面里,找到相应的文件