Sql学习第三天——SQL 关于CTE(公用表达式)的递归查询使用
关于使用CTE(公用表表达式)的递归查询----SQL Server 2005及以上版本
公用表表达式 (CTE) 具有一个重要的优点,那就是能够引用其自身,从而创建递归 CTE。递归 CTE 是一个重复执行初始 CTE 以返回数据子集直到获取完整结果集的公用表表达式。
当某个查询引用递归 CTE 时,它即被称为递归查询。递归查询通常用于返回分层数据,例如:显示某个组织图中的雇员或物料清单方案(其中父级产品有一个或多个组件,而那些组件可能还有子组件,或者是其他父级产品的组件)中的数据。
递归 CTE 可以极大地简化在 SELECT、INSERT、UPDATE、DELETE 或 CREATE VIEW 语句中运行递归查询所需的代码。在 SQL Server 的早期版本中,递归查询通常需要使用临时表、游标和逻辑来控制递归步骤流。
WITH expression_name [ ( column_name [,...n] ) ]
AS
( CTE_query_definition )
--只有在查询定义中为所有结果列都提供了不同的名称时,列名称列表才是可选的。
--运行 CTE 的语句为:
SELECT <column_list> FROM expression_name;
在使用CTE时应注意如下几点:
CTE后面必须直接跟使用CTE的SQL语句(如select、insert、update等),否则,CTE将失效。如下面的SQL语句将无法正常使用CTE:
代码如下:
with
cr as
(
select * from 表名 where 条件
)
--select * from person.CountryRegion --如果加上这句话后面用到cr将报错
select * from cr
2. CTE后面也可以跟其他的CTE,但只能使用一个with,多个CTE中间用逗号(,)分隔,如下面的SQL语句所示:
代码如下:
with
cte1 as
(
select * from table1 where name like '测试%'
),
cte2 as
(
select * from table2 where id > 20
),
cte3 as
(
select * from table3 where price < 100
)
select a.* from cte1 a, cte2 b, cte3 c where a.id = b.id and a.id = c.id
3. 如果CTE的表达式名称与某个数据表或视图重名,则紧跟在该CTE后面的SQL语句使用的仍然是CTE,当然,后面的SQL语句使用的就是数据表或视图。
4. CTE 可以引用自身,也可以引用在同一 WITH 子句中预先定义的 CTE。
5. 不能在 CTE_query_definition 中使用以下子句:
代码如下:
COMPUTE 或 COMPUTE BY
ORDER BY(除非指定了 TOP 子句)
INTO
带有查询提示的 OPTION 子句
FOR XML
FOR BROWSE
6. 如果将 CTE 用在属于批处理的一部分的语句中,那么在它之前的语句必须以分号结尾,如下面的SQL所示:
代码如下:
declare @s nvarchar(3)
set @s = '测试%'; -- 必须加分号
with
t_tree as
(
select * from 表 where 字段 like @s
)
select * from t_tree
------------------------------------操作------------------------------------
上面可能对with as说的有点儿啰嗦了,下面进入正题:
CREATE TABLE [dbo].[Co_ItemNameSet](
[ItemId] [int] NULL,
[ParentItemId] [int] NULL,
[ItemName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL
) ON [PRIMARY]
--给表插入数据
insert into dbo.Co_ItemNameSet values(2,0,'管理费用')
insert into dbo.Co_ItemNameSet values(3,0,'销售费用')
insert into dbo.Co_ItemNameSet values(4,0,'财务费用')
insert into dbo.Co_ItemNameSet values(5,0,'生产成本')
insert into dbo.Co_ItemNameSet values(35,5,'材料')
insert into dbo.Co_ItemNameSet values(36,5,'人工')
insert into dbo.Co_ItemNameSet values(37,5,'制造费用')
insert into dbo.Co_ItemNameSet values(38,35,'原材料')
insert into dbo.Co_ItemNameSet values(39,35,'主要材料')
insert into dbo.Co_ItemNameSet values(40,35,'间辅材料')
insert into dbo.Co_ItemNameSet values(41,36,'工资')
insert into dbo.Co_ItemNameSet values(42,36,'福利')
insert into dbo.Co_ItemNameSet values(43,2,'管理费用子项')
insert into dbo.Co_ItemNameSet values(113,43,'管理费用子项的子项')
--查询数据
select * from Co_ItemNameSet
结果图:
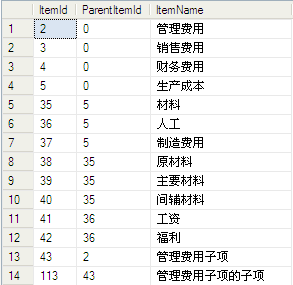
题目需求是:查询ItemId=2及子节点,也就是管理费用和其下属所有节点的信息
操作1:先看看不用CTE递归操作的sql语句如下(需要真是的建两个表进行数据的存放和判断,非常麻烦):
代码如下:
declare @i int
select @i=2;
create table #tem(
[ItemId] [INT] NOT NULL,
[level] INT
);
create table #list(
[ItemId] [INT] NOT NULL,
[ParentItemId] [INT] NOT NULL default ((0)),
[ItemName] [nvarchar](100) NOT NULL default (''),
[level] int
);
insert INTO #tem([ItemId],[level])
select ItemId,1
from Co_ItemNameSet
where itemid=@i
insert into #list([ItemId],[ParentItemId],[ItemName],[level])
select ItemId,ParentItemId,ItemName,1
from Co_ItemNameSet
where itemid=@i
declare @level int
select @level=1
declare @current INT
select @current=0
while(@level>0)
begin
select @current=ItemId
from #tem
where [level]=@level
if @@ROWCOUNT>0
begin
delete from #tem
where [level]=@level and ItemId=@current
insert into #tem([ItemId],[level])
select [ItemId],@level+1
from Co_ItemNameSet
where ParentItemId=@current
insert into #list([ItemId],[ParentItemId],[ItemName],[level])
select [ItemId],[ParentItemId],[ItemName],@level+1
from Co_ItemNameSet
where ParentItemId=@current
if @@rowcount>0
begin
select @level=@level+1
end
end
else
begin
select @level=@level-1
end
end
select * from #list
drop table #tem
drop table #list
结果图:

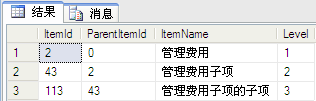
DECLARE @i INT
SELECT @i=2;
WITH Co_ItemNameSet_CTE(ItemId,ParentItemId,ItemName,[Level])
AS
(
SELECT ItemId,ParentItemId,ItemName,1 AS [Level]
FROM Co_ItemNameSet
WHERE itemid=@i
UNION ALL
SELECT c.ItemId,c.ParentItemId,c.ItemName,[Level] + 1
FROM Co_ItemNameSet c INNER JOIN Co_ItemNameSet_CTE ct
ON c.ParentItemId=ct.ItemId
)
SELECT * FROM Co_ItemNameSet_CTE
结果图:
-----------------------------分析(查看MSDN的分析)----------------------------
主要分析一下用CTE的递归操作:
递归 CTE 由下列三个元素组成:
例程的调用。
递归 CTE 的第一个调用包括一个或多个由 UNION ALL、UNION、EXCEPT 或 INTERSECT 运算符联接的 CTE_query_definitions。由于这些查询定义形成了 CTE 结构的基准结果集,所以它们被称为“定位点成员”。
CTE_query_definitions 被视为定位点成员,除非它们引用了 CTE 本身。所有定位点成员查询定义必须放置在第一个递归成员定义之前,而且必须使用 UNION ALL 运算符联接最后一个定位点成员和第一个递归成员。
例程的递归调用。
递归调用包括一个或多个由引用 CTE 本身的 UNION ALL 运算符联接的 CTE_query_definitions(就是as里的语句块)。这些查询定义被称为“递归成员”。
终止检查。
终止检查是隐式的;当上一个调用中未返回行时,递归将停止。
递归 CTE 结构必须至少包含一个定位点成员和一个递归成员。以下伪代码显示了包含一个定位点成员和一个递归成员的简单递归 CTE 的组件。
代码如下:
WITH cte_name ( column_name [,...n] )
AS
(
CTE_query_definition --定位点成员
UNION ALL
CTE_query_definition --递归成员.
)
现在让我们看一下递归执行过程:
将 CTE 表达式拆分为定位点成员和递归成员。
运行定位点成员,创建第一个调用或基准结果集 (T0)。
运行递归成员,将 Ti 作为输入,将 Ti+1 作为输出。
重复步骤 3,直到返回空集。
返回结果集。这是对 T0 到 Tn 执行 UNION ALL 的结果。
相关推荐
-
sqlserver中存储过程的递归调用示例
递归式指代码片段调用自身的情况:危险之处在于:如果调用了自身一次,那么如何防止他反复地调用自身.也就是说提供递归检验来保证适当的时候可以跳出. 以阶层为例子说存储过程中递归的调用. 递归 CREATE PROC [dbo].[usp_spFactorial] @InputValue INT, @OuputValue INT OUTPUT AS BEGIN DECLARE @InValue INT; DECLARE @OutValue INT; IF(@InputValue!=1) BEGIN S
-

sqlserver另类非递归的无限级分类(存储过程版)
下面是我统计的几种方案: 第一种方案(递归式): 简单的表结构为: CategoryID int(4), CategoryName nvarchar(50), ParentID int(4), Depth int(4) 这样根据ParentID一级级的运用递归找他的上级目录. 还有可以为了方便添加CategoryLeft,CategoryRight保存他的上级目录或下级目录 第二种方案: 设置一个varchar类型的CategoryPath字段来保存目录的完整路径,将父目录id用符号分隔开来.比
-
使用SQLSERVER 2005/2008 递归CTE查询树型结构的方法
下面是一个简单的Family Tree 示例: 复制代码 代码如下: DECLARE @TT TABLE (ID int,Relation varchar(25),Name varchar(25),ParentID int) INSERT @TT SELECT 1,' Great GrandFather' , 'Thomas Bishop', null UNION ALL SELECT 2,'Grand Mom', 'Elian Thomas Wilson' , 1 UNION ALL SELE
-
SQLSERVER2005 中树形数据的递归查询
问题描述.借用了adinet的问题.参见:http://www.jb51.net/article/28670.htm 今天做项目遇到一个问题, 有产品分类A,B,C顶级分类, 期中A下面有a1,a2,a3子分类. 但是a1可能共同属于A和B,然后我的数据库是这样设计的 id name parnet 1 A 0 2 B 0 3 a1 1,2 如果想要查询A的所有子类的话就要查询parent中包含1的,所以就萌生了这个办法.呵呵,解决方案 复制代码
-
SQLserver2008使用表达式递归查询
复制代码 代码如下: --由父项递归下级 with cte(id,parentid,text) as (--父项 select id,parentid,text from treeview where parentid = 450 union all --递归结果集中的下级 select t.id,t.parentid,t.text from treeview as t inner join cte as c on t.parentid = c.id ) select id,parentid,t
-
使用SqlServer CTE递归查询处理树、图和层次结构
CTE(Common Table Expressions)是从SQL Server 2005以后版本才有的.指定的临时命名结果集,这些结果集称为CTE. 与派生表类似,不存储为对象,并且只在查询期间有效.与派生表的不同之处在于,CTE 可自引用,还可在同一查询中引用多次.使用CTE能改善代码可读性,且不损害其性能. 递归CTE是SQL SERVER 2005中重要的增强之一.一般我们在处理树,图和层次结构的问题时需要用到递归查询. CTE的语法如下 WITH CTE AS ( SELECT Em
-
Sql学习第三天——SQL 关于CTE(公用表达式)的递归查询使用
关于使用CTE(公用表表达式)的递归查询----SQL Server 2005及以上版本 公用表表达式 (CTE) 具有一个重要的优点,那就是能够引用其自身,从而创建递归 CTE.递归 CTE 是一个重复执行初始 CTE 以返回数据子集直到获取完整结果集的公用表表达式. 当某个查询引用递归 CTE 时,它即被称为递归查询.递归查询通常用于返回分层数据,例如:显示某个组织图中的雇员或物料清单方案(其中父级产品有一个或多个组件,而那些组件可能还有子组件,或者是其他父级产品的组件)中的数据. 递归 C
-
Sql学习第三天——SQL 关于with ties介绍
关于with ties 对于with ties一般是和Top , order by相结合使用的,会查询出最后一条数据额外的返回值(解释:如果按照order by 参数排序TOP n(PERCENT)返回了前面n(pencent)个记录,但是n+1-n+k条记录和排序后的第n条记录的参数值(order by 后面的参数)相同,则n+1.-.n+k也返回.n+1.-.n+k就是额外的返回值). 实验: 实验用表(PeopleInfo): 复制代码 代码如下: CREATE TABLE [dbo].[
-
Sql学习第四天——SQL 关于with cube,with rollup和grouping解释及演示
关于with cube ,with rollup 和 grouping 通过查看sql 2005的帮助文档找到了CUBE 和 ROLLUP 之间的具体区别: CUBE 生成的结果集显示了所选列中值的所有组合的聚合.ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合. 再看看对grouping的解释: 当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1:当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0. 仅在与包含 C
-
SQL学习笔记三 select语句的各种形式小结
复制代码 代码如下: Select * from T_Employee select FName,FAge from T_Employee select FName from T_Employee where FSalary < 5000 select FName as 姓名,FAge as 年龄,FSalary as 月薪from T_Employee where FSalary < 5000 select FName as 姓名,FAge as 年龄,FSalary as 月薪,getda
-
SQL中的三种去重方法小结
目录 distinct group by row_number 在使用SQL提数的时候,常会遇到表内有重复值的时候,比如我们想得到 uv (独立访客),就需要做去重. 在 MySQL 中通常是使用 distinct 或 group by子句,但在支持窗口函数的 sql(如Hive SQL.Oracle等等) 中还可以使用 row_number 窗口函数进行去重. 举个栗子,现有这样一张表 task: task_id order_id start_time 1 123 2020-01-05 1 2
-
pandas学习之txt与sql文件的基本操作指南
目录 前言 1.导入txt文件 2.导入sql文件 2.1 安装依赖库pymysql 3.小结 总结 前言 Pandas是python的一个数据分析包,是基于NumPy的一种工具提供了大量数据结构和函数,可以很方便的处理结构化数据,常见数据结构有: Series:一维数组,与Numpy中的一维array类似. DataFrame:二维的表格型数据结构,可以将DataFrame理解为Series的容器 Time- Series:以时间为索引的Series Panel :三维的数组,可以理解为Dat
-
MySQL导入sql文件的三种方法小结
目录 一.使用工具Navicat for MySQL导入 1.打开localhost_3306,选中右击“新建数据库” 2.指定数据库名和字符集(可根据sql文件的字符集类型自行选择) 3.选中数据库下的表运行SQL文件 4.选中路径导入 二.使用官方工具MySQL Workbench导入 1.第一种方法 2.第二种方法 三.使用命令行导入 总结 一.使用工具Navicat for MySQL导入 工具的具体下载及使用方法推荐的一篇文章:https://www.jb51.net/article/
-
三种SQL分页查询的存储过程代码
复制代码 代码如下: --根据MAX(MIN)ID CREATE PROC [dbo].[proc_select_id] @pageindex int=1,--当前页数 @pagesize int=10,--每页大小 @tablename VARCHAR(50)='',--表名 @fields VARCHAR(1000)='',--查询的字段集合 @keyid VARCHAR(50)='',--主键 @condition NVARCHAR(1000)='',--查询条件 @orderstr VA
-
DB2 UDB V8.1管理学习笔记(三)
正在看的db2教程是:DB2 UDB V8.1管理学习笔记(三).强制断开已有连接,停止实例并删除. $ db2idrop -f instance_name 用于在UNIX下迁移实例. $ db2imigr instance_name 更新实例,用于实例获得一些新的产品选项或修订包的访问权. $ db2iupdt instance_name 获取当前所处的实例. $ db2 get instance 当更新实例级别或数据库级别的参数后,有些可以立即生效,有些需要重新启动实例才可生效.immed
-
MyBatis学习教程(三)-MyBatis配置优化
一.连接数据库的配置单独放在一个properties文件中 之前,我们是直接将数据库的连接配置信息写在了MyBatis的conf.xml文件中,如下: <?xml version="." encoding="UTF-"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config .//EN" "http://mybatis.org/dtd/mybatis--