MySQL索引使用全程分析
创建2张用户表user、user2,表结构相同,但user表使用InnoDB存储引擎,而user2表则使用 MyISAM存储引擎。
代码如下:
-- Table "user" DDL
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`email` varchar(100) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`nickname` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `email` (`email`),
KEY `name` (`name`),
KEY `age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- Table "user2" DDL
CREATE TABLE `user2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`email` varchar(100) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`nickname` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `email` (`email`),
KEY `name` (`name`),
KEY `age` (`age`)
) ENGINE=MyISAM AUTO_INCREMENT=131610 DEFAULT CHARSET=utf8;
分别插入10W条测试数据到表user & user2。
代码如下:
<?php
$example = array(
'@qq.com',
'@sina.com.cn',
'@163.com',
'@126.com',
'@gmail.com',
'@yahoo.com',
'@live.com',
'@msn.com',
'@cisco.com',
'@microsoft.com',
'@ibm.com',
'@apple.com');
$con = mysql_connect("localhost", "root", "your_mysql_password");
mysql_select_db("index_test", $con);
//添加10W测试数据到表 user & user2
for($i=0; $i<100000; $i++)
{
$temp = md5(uniqid());
$name = substr($temp, 0, 16);
$email = substr($temp, 8, 12).$example[array_rand($example, 1)];
$age = rand(18, 99);
$nickname = substr($temp, 16, 16);
mysql_query("INSERT INTO user(name,email,age,nickname) VALUES('$name','$email',$age,'$nickname')");
mysql_query("INSERT INTO user2(name,email,age,nickname) VALUES('$name','$email',$age,'$nickname')");
}
mysql_close($con);
echo 'success';
?>
对索引的使用分析
Explain Select * from user where id>100 \G; 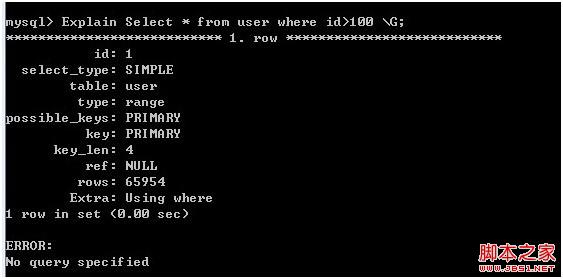
图1
Explain Select * from user2 where id>100 \G; 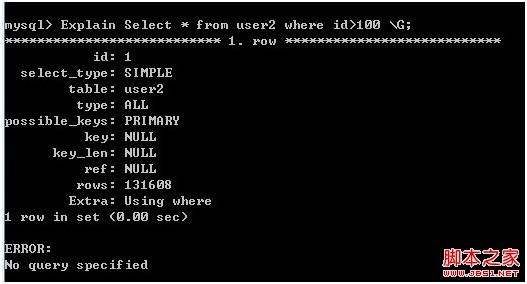
图2
User 表中的数据和 User2 表中的数据是一样的,索引结构也是一样的,只不过它们的存储引擎不同。在图1中,查询用到了PRIMARY主键索引,而查询优化器预估的结果大概在65954行左右(实际是131513);在图2中,查询却没有使用索引,而是全表扫描了,返回的预估结果在131608行(实际是131509)。
Explain Select * from user where id>100 and age>50 \G; 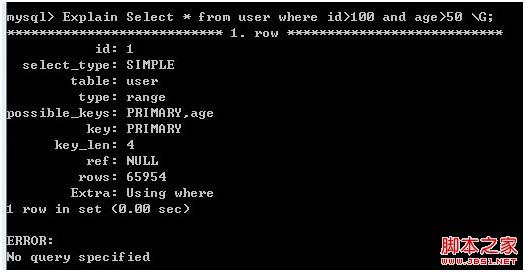
图3
Explain Select * from user where id>100 and age=50 \G; 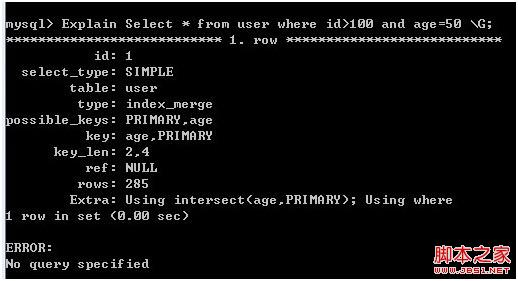
图4
Explain Select * from user2 where id>100 and age>50 \G; 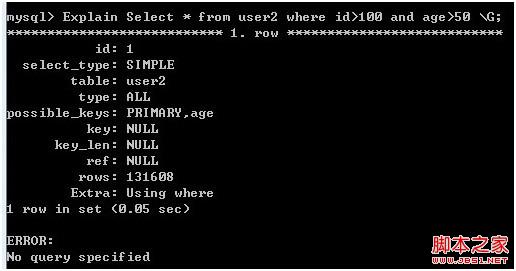
图5
Explain Select * from user2 where id>100 and age=50 \G; 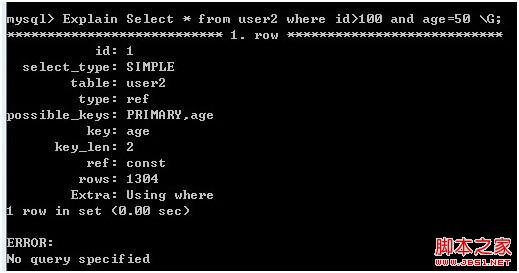
图6
相关推荐
-
MySQL 通过索引优化含ORDER BY的语句
关于建立索引的几个准则: 1.合理的建立索引能够加速数据读取效率,不合理的建立索引反而会拖慢数据库的响应速度. 2.索引越多,更新数据的速度越慢. 3.尽量在采用MyIsam作为引擎的时候使用索引(因为MySQL以BTree存储索引),而不是InnoDB.但MyISAM不支持Transcation. 4.当你的程序和数据库结构/SQL语句已经优化到无法优化的程度,而程序瓶颈并不能顺利解决,那就是应该考虑使用诸如memcached这样的分布式缓存系统的时候了. 5.习惯和强迫自己用EXPLAIN来
-
MySQL查询优化之索引的应用详解
糟糕的SQL查询语句可对整个应用程序的运行产生严重的影响,其不仅消耗掉更多的数据库时间,且它将对其他应用组件产生影响. 如同其它学科,优化查询性能很大程度上决定于开发者的直觉.幸运的是,像MySQL这样的数据库自带有一些协助工具.本文简要讨论诸多工具之三种:使用索引,使用EXPLAIN分析查询以及调整MySQL的内部配置. MySQL允许对数据库表进行索引,以此能迅速查找记录,而无需一开始就扫描整个表,由此显著地加快查询速度.每个表最多可以做到16个索引,此外MySQL还支持多列索引及全文检索.
-
MySQL Order By索引优化方法
尽管 ORDER BY 不是和索引的顺序准确匹配,索引还是可以被用到,只要不用的索引部分和所有的额外的 ORDER BY 字段在 WHERE 子句中都被包括了. 使用索引的MySQL Order By 下列的几个查询都会使用索引来解决 ORDER BY 或 GROUP BY 部分: 复制代码 代码如下: SELECT * FROM t1 ORDER BY key_part1,key_part2,... ; SELECT * FROM t1 WHERE key_part1=constant ORD
-
如何提高MYSQL数据库的查询统计速度 select 索引应用
数据库系统是管理信息系统的核心,基于数据库的联机事务处理(OLTP)以及联机分析处理(OLAP)是银行.企业.政府等部门最为重要的计算机应用之一.从大多数系统的应用实例来看,查询操作在各种数据库操作中所占据的比重最大,而查询操作所基于的SELECT语句在SQL语句中又是代价最大的语句.举例来说,如果数据的量积累到一定的程度,比如一个银行的账户数据库表信息积累到上百万甚至上千万条记录,全表扫描一次往往需要数十分钟,甚至数小时.如果采用比全表扫描更好的查询策略,往往可以使查询时间降为几分钟,由此可见
-
mysql 表索引的一些要点
1.表的主键.外键必须有索引: 2.数据量超过300的表应该有索引: 3.经常与其他表进行连接的表,在连接字段上应该建立索引: 4.经常出现在Where子句中的字段,特别是大表的字段,应该建立索引: 5.索引应该建在选择性高的字段上: 6.索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引: 7.复合索引的建立需要进行仔细分析:尽量考虑用单字段索引代替: A.正确选择复合索引中的主列字段,一般是选择性较好的字段: B.复合索引的几个字段是否经常同时以AND方式出现在Whe
-
MySQL 主键与索引的联系与区别分析
关系数据库依赖于主键,它是数据库物理模式的基石.主键在物理层面上只有两个用途: 惟一地标识一行. 作为一个可以被外键有效引用的对象. 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针.下面是主键和索引的一些区别与联系. 1. 主键一定是唯一性索引,唯一性索引并不一定就是主键. 所谓主键就是能够唯一标识表中某一行的属性或属性组,一个表只能有一个主键,但可以有多个候选索引.因为主键可以唯一标识某一行记录,所以可以确保执行数据更新.删除的
-
MySQL索引的缺点以及MySQL索引在实际操作中有哪些事项
以下的文章主要介绍的是MySQL索引的缺点以及MySQL索引在实际操作中有哪些事项是值得我们大家注意的,我们大家可能不知道过多的对索引进行使用将会造成滥用.因此MySQL索引也会有它的缺点: 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT.UPDATE和DELETE.因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件. 建立索引会占用磁盘空间的索引文件.一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快. 索引只是提高效
-

MySQL 索引分析和优化
一.什么是索引? 索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-树的形式保存.如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录.表里面的记录数量越多,这个操作的代价就越高.如果作为搜索条件的列上已经创建了索引,MySQL无需扫描任何记录即可迅速得到目标记录所在的位置.如果表有1000个记录,通过索引查找记录至少要比顺序扫描记录快100倍. 假设我们创建了一个名为people的表: CREATE TABLE people ( p
-
php mysql索引问题
显然这是一个凡是使用MySQL的朋友都会遇到的问题. 回忆一下当初在配置环境时提到的MySQL GUI工具,对了,就是它,大家可以到http://www.mysql.com中找到它.因为sunec也只是一名程序爱好者,远没有达到程序员水平,所以借助一些工具的帮助还是很有必要的~相信一些朋友也和我一样~ 用GUI工具创建表,建立REF字段,把REF设置为主键,定义类型为int,并在AUTO INC选项上打勾.好了,在MySQL端的工作就结束了. 接下去就交给PHP了,用之前专题中介绍过的inser
-
基于mysql全文索引的深入理解
前言:本文简单讲述全文索引的应用实例,MYSQL演示版本5.5.24. Q:全文索引适用于什么场合? A:全文索引是目前实现大数据搜索的关键技术. 至于更详细的介绍请自行百度,本文不再阐述. -------------------------------------------------------------------------------- 一.如何设置? 如图点击结尾处的{全文搜索}即可设置全文索引,不同MYSQL版本名字可能不同. 二.设置条件 1.表的存储引擎是MyISAM,默认
-
MySQL笔记之索引的使用
索引是创建在表上的,对数据库表中一列或多列的值进行排序的一种结构 其作用主要在于提高查询的速度,降低数据库系统的性能开销 通过索引,查询数据不必读完记录的全部信息进行匹配,而是只查询索引列 索引相当于字典中的音序表,要查询某字时可以在音序表中找到 然后直接跳转到那一音序所在位置,而不必从字典第一页开始翻,逐字匹配 tips:索引虽能提高查询速度,但在插入记录时会按照索引进行排序,因此降低了插入速度 最好的操作方式是先删除索引,插入大量记录后再创建索引 索引分类 1.普通索引:不附加任何限制条
-
Mysql建表与索引使用规范详解
一. MySQL建表,字段需设置为非空,需设置字段默认值.二. MySQL建表,字段需NULL时,需设置字段默认值,默认值不为NULL.三. MySQL建表,如果字段等价于外键,应在该字段加索引.四. MySQL建表,不同表之间的相同属性值的字段,列类型,类型长度,是否非空,是否默认值,需保持一致,否则无法正确使用索引进行关联对比.五. MySQL使用时,一条SQL语句只能使用一个表的一个索引.所有的字段类型都可以索引,多列索引的属性最多15个.六. 如果可以在多个索引中进行选择,MySQL通常
-
MYSQL索引建立需要注意以下几点细节
1.建立索引的时机:若表中的某字段出现在select.过滤.排序条件中,为该字段建立索引是值得的. 2.对于like '%xxx'的模糊查询,普通的索引是无法满足的,需要建立全文索引. 3.对于有多个条件的,比如: "...where a=xxx and b=yyy","...where a=xxx order by b","...where a=xxx group by b".需要使用组合索引.但是组合索引只能在SQL语句中满足"最左
-
mysql占用CPU过高的解决办法(添加索引)
下面是MYSQL占用CPU高处理的一个例子,希望对遇到类似问题的朋友们有点启发.一般来说MYQL占用CPU高,多半是数据库查询代码问题,查询数据库过多.所以一方面要精简代码,另一方面最好对频繁使用的代码设置索引. 今天早上起来 机器报警 一查负载一直都在4以上 top了一下 发现 mysql 稳居 第一 而且相当稳定 我擦 重启一下mysql不行 mysql> show processlist;一下 发现xxx网站有两条 查询语句 一直 在列,我擦 该站 也就30多万条记录 量也不大 不可能是机
-
MySQL索引背后的之使用策略及优化(高性能索引策略)
本章的内容完全基于上文的理论基础,实际上一旦理解了索引背后的机制,那么选择高性能的策略就变成了纯粹的推理,并且可以理解这些策略背后的逻辑. 示例数据库 为了讨论索引策略,需要一个数据量不算小的数据库作为示例.本文选用MySQL官方文档中提供的示例数据库之一:employees.这个数据库关系复杂度适中,且数据量较大.下图是这个数据库的E-R关系图(引用自MySQL官方手册): 图12 MySQL官方文档中关于此数据库的页面为http://dev.mysql.com/doc/employee/en